假期的前段时间对于上学期的大数据稍微做了总结,对可视化工具echarts参照b站学习了几节。
接下来的假期将学习spark。
今天将spark安装完成,并且在大学生mooc上将其spark的一章视频学习完。其分为6小节。
Spark概述,spark生态系统,spark运行架构,spark sql,spark的部署和应用方式,spark编程实践。
成功安装spark
- Spark是基于内存计算的大数据并行计算框架,所以相比于基于磁盘计算的hadoop计算框架具有低延迟,运行速度快的优点。
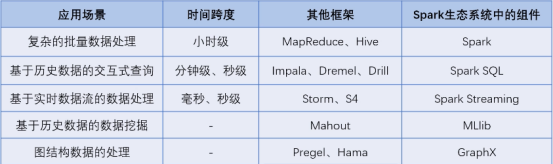
- Spark生态系统包含了spark core(提供内存计算,)、spark sql(提供交互式查询分析)、spark streaming(提供流计算功能)、MLLib(提供机器学习算法库的组件)和Graphx(提供图计算)等组件。
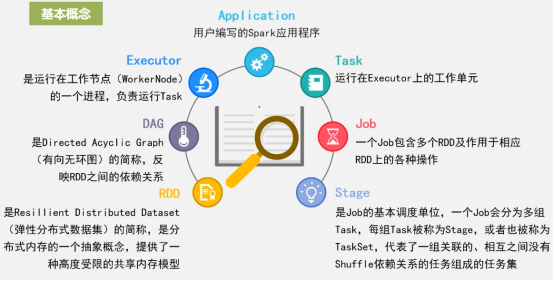
3.运行架构
spark运行流程:
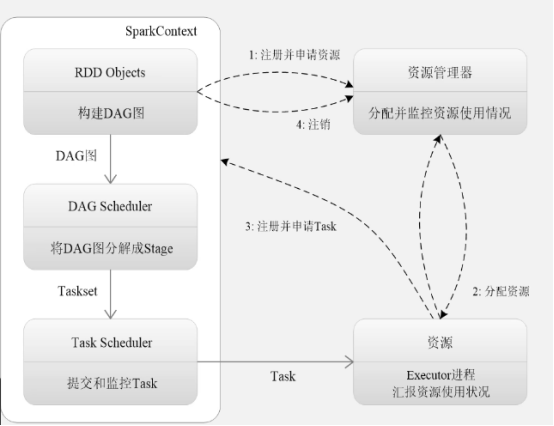
Spark采用Executor的优点
①利用多线程来执行具体的任务,减少任务的启动开销
②利用BlockManager存储模块减少IO开销
4.spark sql:在hive兼容层面仅依赖HiveQL解析、Hive元数据。
接下来准备每天进行spark实验