一.集合与数组的比较:
数组无法判断其中实际存有多少元素,length只告诉了数组的容量,而集合的size()可以确切知道元素的个数
二.集合:是一个用来存放对象的容器。
注意:
- 集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
- 集合存放的是多个对象的引用,对象本身还是放在堆内存中。
- 集合可以存放不同类型,不限数量的数据类型。
Collection和Map,是集合框架的根接口。
Collection的子接口:
Set:接口 ---实现类: HashSet、LinkedHashSet
Set的子接口SortedSet接口---实现类:TreeSet
List:接口---实现类: LinkedList,Vector,ArrayList
Map的实现类:HashMap,TreeMap
List集合
有序列表,允许存放重复的元素;
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
数组与链表的区别:
- 数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要望某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
- 链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起,每个结点包括两个部分:一个是存储数据元素 的数据域,另一个是存储下一个结点地址的 指针。如果要访问链表中一个元素,需要从第一个元素始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表。
2.set集合:
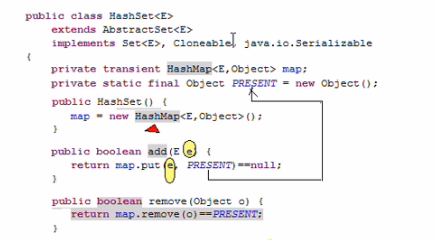
典型实现 HashSet()是一个无序,不可重复的集合,其底层其实是包装了一个HashMap去实现的。HashSet采用HashCode算法来存取集合中的元素,因此具有比较好的读取和查找性能。
1、Set hashSet = new HashSet();
HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL(只能有1个);
对于 HashSet: 如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
- 1、当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
- 1.1、如果 hashCode 值不同,直接把该元素存储到 hashCode() 指定的位置
- 1.2、如果 hashCode 值相同,那么会继续判断该元素和集合对象的 equals() 作比较
- 1.2.1、hashCode 相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
- 1.2.2、hashCode 相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该约束这种情况,即保证:如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
2.Set treeSet = new TreeSet();
TreeSet实现了SortedSet接口,顾名思义这是一种排序的Set集合,查看jdk源码发现底层是用TreeMap实现的,本质上是一个红黑树原理。
- * 如果使用 TreeSet() 无参数的构造器创建一个 TreeSet 对象, 则要求放入其中的元素的类必须实现 Comparable 接口所以, 在其中不能放入 null 元素
- * 必须放入同样类的对象.(默认会进行排序) 否则可能会发生类型转换异常.我们可以使用泛型来进行限制
比较:
4.EnumSet特征
3.Map集合
Map:key-value 的键值对,key 不允许重复,value 可以
1、严格来说 Map 并不是一个集合,而是两个集合之间 的映射关系。
2、这两个集合没每一条数据通过映射关系,我们可以看成是一条数据。即 Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3、因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 for-each 遍历。

、Map 和 Set 集合的关系
1、都有几个类型的集合。HashMap 和 HashSet ,都采 哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
2、分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成。