完整代码:https://github.com/zle1992/Reinforcement_Learning_Game
Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无法单步更新。
QLearning 先预测出Q值,根据Q值选动作,无法预测连续动作、或者动作种类多的情况,但是可以单步更新。
一句话概括 Actor Critic 方法:
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法.
Actor 基于概率选行为 Critic 基于 Actor 的行为评判行为的得分,
Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快.
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
Actor Critic 方法与Policy Gradinet的区别:
Policy Gradinet 中的梯度下降 :
grad[logPi(s,a) * v_t]
其中v_t是真实的reward ,通过记录每个epoch的每一个state,action,reward得到。
而Actor中的v_t 是td_error 由Critic估计得到,不一定准确哦。
Actor Critic 方法与DQN的区别:
DQN 评价网络与动作网络其实是一个网络,只是采用了TD的方法,用滞后的网络去评价当前的动作。
Actor-Critic 就是在求解策略的同时用值函数进行辅助,用估计的值函数替代采样的reward,提高样本利用率。
Q-learning 是一种基于值函数估计的强化学习方法,Policy Gradient是一种策略搜索强化学习方法
Critic估计td_error跟DQN一样,用到了贝尔曼方程,
贝尔曼方程 :
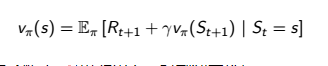
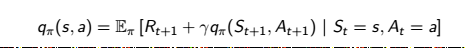
Critic利用的是V函数的贝尔曼方程,来得到TD_error,
gradient = grad[r + gamma * V(s_) - V(s)]
Q-learning 利用的是Q函数的贝尔曼方程,来更新Q函数。
q_target = r + gamma * maxq(s_next)
q_eval = maxq(s)
Actor网络的输入(st,at,TDerror)
Actor 网络与policy gradient 差不多,多分类网络,在算loss时候,policy gradient需要乘一个权重Vt,而Vt是根据回报R 累计计算的。
在Actor中,在算loss时候,loss的权重是TDerror
TDerror是Critic网络计算出来的。
Critic网络的输入(st,vt+1,r),输出TDerror
V_eval = network(st)
# TD_error = (r+gamma*V_next) - V_eval
学习的时候输入:(st, r, st+1)
vt+1 = network(st+1)
Critic网络(st,vt+1,r)
ACNetwork.py
1 import os 2 import numpy as np 3 import tensorflow as tf 4 from abc import ABCMeta, abstractmethod 5 np.random.seed(1) 6 tf.set_random_seed(1) 7 8 import logging # 寮曞叆logging妯″潡 9 logging.basicConfig(level=logging.DEBUG, 10 format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig鍑芥暟瀵规棩蹇楃殑杈撳嚭鏍煎紡鍙婃柟寮忓仛鐩稿叧閰嶇疆 11 # 鐢变簬鏃ュ織鍩烘湰閰嶇疆涓�骇鍒��缃�负DEBUG锛屾墍浠ヤ竴涓嬫墦鍗颁俊鎭�皢浼氬叏閮ㄦ樉绀哄湪鎺у埗鍙颁笂 12 13 tfconfig = tf.ConfigProto() 14 tfconfig.gpu_options.allow_growth = True 15 session = tf.Session(config=tfconfig) 16 17 18 class ACNetwork(object): 19 __metaclass__ = ABCMeta 20 """docstring for ACNetwork""" 21 def __init__(self, 22 n_actions, 23 n_features, 24 learning_rate, 25 memory_size, 26 reward_decay, 27 output_graph, 28 log_dir, 29 model_dir, 30 ): 31 super(ACNetwork, self).__init__() 32 33 self.n_actions = n_actions 34 self.n_features = n_features 35 self.learning_rate=learning_rate 36 self.gamma=reward_decay 37 self.memory_size =memory_size 38 self.output_graph=output_graph 39 self.lr =learning_rate 40 41 self.log_dir = log_dir 42 43 self.model_dir = model_dir 44 # total learning step 45 self.learn_step_counter = 0 46 47 48 self.s = tf.placeholder(tf.float32,[None]+self.n_features,name='s') 49 self.s_next = tf.placeholder(tf.float32,[None]+self.n_features,name='s_next') 50 51 self.r = tf.placeholder(tf.float32,[None,],name='r') 52 self.a = tf.placeholder(tf.int32,[None,],name='a') 53 54 55 56 57 58 with tf.variable_scope('Critic'): 59 60 self.v = self._build_c_net(self.s, scope='v', trainable=True) 61 self.v_ = self._build_c_net(self.s_next, scope='v_next', trainable=False) 62 63 self.td_error =self.r + self.gamma * self.v_ - self.v 64 self.loss_critic = tf.square(self.td_error) 65 with tf.variable_scope('train'): 66 self.train_op_critic = tf.train.AdamOptimizer(self.lr).minimize(self.loss_critic) 67 68 69 70 with tf.variable_scope('Actor'): 71 self.acts_prob = self._build_a_net(self.s, scope='actor_net', trainable=True) 72 # this is negative log of chosen action 73 log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.acts_prob, labels=self.a) 74 75 self.loss_actor = tf.reduce_mean(log_prob*self.td_error) 76 with tf.variable_scope('train'): 77 self.train_op_actor = tf.train.AdamOptimizer(self.lr).minimize(-self.loss_actor) 78 79 80 self.sess = tf.Session() 81 if self.output_graph: 82 tf.summary.FileWriter(self.log_dir,self.sess.graph) 83 84 self.sess.run(tf.global_variables_initializer()) 85 86 self.cost_his =[0] 87 88 89 self.saver = tf.train.Saver() 90 91 if not os.path.exists(self.model_dir): 92 os.mkdir(self.model_dir) 93 94 checkpoint = tf.train.get_checkpoint_state(self.model_dir) 95 if checkpoint and checkpoint.model_checkpoint_path: 96 self.saver.restore(self.sess, checkpoint.model_checkpoint_path) 97 print ("Loading Successfully") 98 self.learn_step_counter = int(checkpoint.model_checkpoint_path.split('-')[-1]) + 1 99 100 101 @abstractmethod 102 def _build_a_net(self,x,scope,trainable): 103 104 raise NotImplementedError 105 def _build_c_net(self,x,scope,trainable): 106 107 raise NotImplementedError 108 def learn(self,data): 109 110 111 112 113 batch_memory_s = data['s'] 114 batch_memory_a = data['a'] 115 batch_memory_r = data['r'] 116 batch_memory_s_ = data['s_'] 117 118 119 120 _, cost = self.sess.run( 121 [self.train_op_critic, self.loss_critic], 122 feed_dict={ 123 self.s: batch_memory_s, 124 self.a: batch_memory_a, 125 self.r: batch_memory_r, 126 self.s_next: batch_memory_s_, 127 128 }) 129 130 _, cost = self.sess.run( 131 [self.train_op_actor, self.loss_actor], 132 feed_dict={ 133 self.s: batch_memory_s, 134 self.a: batch_memory_a, 135 self.r: batch_memory_r, 136 self.s_next: batch_memory_s_, 137 138 }) 139 140 141 self.cost_his.append(cost) 142 143 self.learn_step_counter += 1 144 # save network every 100000 iteration 145 if self.learn_step_counter % 10000 == 0: 146 self.saver.save(self.sess,self.model_dir,global_step=self.learn_step_counter) 147 148 149 150 def choose_action(self,s): 151 s = s[np.newaxis,:] 152 153 probs = self.sess.run(self.acts_prob,feed_dict={self.s:s}) 154 return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())
game.py
1 import sys 2 import gym 3 import numpy as np 4 import tensorflow as tf 5 sys.path.append('./') 6 sys.path.append('model') 7 8 from util import Memory ,StateProcessor 9 from ACNetwork import ACNetwork 10 np.random.seed(1) 11 tf.set_random_seed(1) 12 13 import logging # 引入logging模块 14 logging.basicConfig(level=logging.DEBUG, 15 format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig函数对日志的输出格式及方式做相关配置 16 # 由于日志基本配置中级别设置为DEBUG,所以一下打印信息将会全部显示在控制台上 17 import os 18 os.environ["CUDA_VISIBLE_DEVICES"] = "1" 19 tfconfig = tf.ConfigProto() 20 tfconfig.gpu_options.allow_growth = True 21 session = tf.Session(config=tfconfig) 22 23 24 25 class ACNetwork4CartPole(ACNetwork): 26 """docstring for ClassName""" 27 def __init__(self, **kwargs): 28 super(ACNetwork4CartPole, self).__init__(**kwargs) 29 30 def _build_a_net(self,x,scope,trainable): 31 w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) 32 33 with tf.variable_scope(scope): 34 e1 = tf.layers.dense(inputs=x, 35 units=32, 36 bias_initializer = b_initializer, 37 kernel_initializer=w_initializer, 38 activation = tf.nn.relu, 39 trainable=trainable) 40 q = tf.layers.dense(inputs=e1, 41 units=self.n_actions, 42 bias_initializer = b_initializer, 43 kernel_initializer=w_initializer, 44 activation = tf.nn.softmax, 45 trainable=trainable) 46 47 return q 48 49 def _build_c_net(self,x,scope,trainable): 50 w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) 51 52 with tf.variable_scope(scope): 53 e1 = tf.layers.dense(inputs=x, 54 units=32, 55 bias_initializer = b_initializer, 56 kernel_initializer=w_initializer, 57 activation = tf.nn.relu, 58 trainable=trainable) 59 q = tf.layers.dense(inputs=e1, 60 units=1, 61 bias_initializer = b_initializer, 62 kernel_initializer=w_initializer, 63 activation =None, 64 trainable=trainable) 65 66 return q 67 68 69 70 batch_size = 32 71 72 memory_size =100 73 #env = gym.make('Breakout-v0') #离散 74 env = gym.make('CartPole-v0') #离散 75 76 77 n_features= list(env.observation_space.shape) 78 n_actions= env.action_space.n 79 env = env.unwrapped 80 81 def run(): 82 83 RL = ACNetwork4CartPole( 84 n_actions=n_actions, 85 n_features=n_features, 86 learning_rate=0.01, 87 reward_decay=0.9, 88 89 memory_size=memory_size, 90 91 output_graph=True, 92 log_dir = 'log/ACNetwork4CartPole/', 93 94 model_dir = 'model_dir/ACNetwork4CartPole/' 95 ) 96 97 memory = Memory(n_actions,n_features,memory_size=memory_size) 98 99 100 step = 0 101 ep_r = 0 102 for episode in range(2000): 103 # initial observation 104 observation = env.reset() 105 106 while True: 107 108 109 # RL choose action based on observation 110 action = RL.choose_action(observation) 111 # logging.debug('action') 112 # print(action) 113 # RL take action and get_collectiot next observation and reward 114 observation_, reward, done, info=env.step(action) # take a random action 115 116 # the smaller theta and closer to center the better 117 x, x_dot, theta, theta_dot = observation_ 118 r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8 119 r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5 120 reward = r1 + r2 121 122 123 124 125 memory.store_transition(observation, action, reward, observation_) 126 127 128 if (step > 200) and (step % 1 == 0): 129 130 data = memory.sample(batch_size) 131 RL.learn(data) 132 #print('step:%d----reward:%f---action:%d'%(step,reward,action)) 133 # swap observation 134 observation = observation_ 135 ep_r += reward 136 # break while loop when end of this episode 137 if(episode>700): 138 env.render() # render on the screen 139 if done: 140 print('step: ',step, 141 'episode: ', episode, 142 'ep_r: ', round(ep_r, 2), 143 'loss: ',RL.cost_his[-1] 144 ) 145 ep_r = 0 146 147 break 148 step += 1 149 150 # end of game 151 print('game over') 152 env.destroy() 153 154 def main(): 155 156 run() 157 158 159 160 if __name__ == '__main__': 161 main() 162 #run2()