本博文主要内容有
1、kmeans算法简介
2、kmeans执行过程
3、关于查看mahout中聚类结果的一些注意事项
4、kmeans算法图解
5、mahout的kmeans算法实现原理
6、kmeans算法运行时参数介绍
7、使用mahout自带的fpg算法来对我们的测数据retail.dat进行kmeans算法(但是0.9及其以后版本照样可以用,但是格式要注意)
8、使用开始使用mahout自带的kmeans算法来对我们的测数据retail.dat进行kmeans算法!
K-means算法

Kmeans的介绍
(1)Kmeans算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。
(2)Kmeans算法的基本思想是:以空间中k个点为中心聚类,对最靠近它们的对象归类。
(3)通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
关于kmeans迭代的体验,可以见博客。
mahout-distribution-0.9.tar.gz的安装的与配置、启动与运行自带的mahout算法
Kmeans的执行过程
1、假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
2、该算法的最大优势在于简介和快速。算法的关键在于初始中心的选择和距离公式。
关于查看mahout中聚类结果的一些注意事项
mahout seqdumper : 将SequenceFile文件转换成可读的文本形式,对应的源文件是org.apache.mahout.utils.SequenceFileDumper.java
mahout vectordump : 将向量文件转成可读的文本形式,对应的源文件是org.apache.mahout.utils.vectors.VectorDumper.java
mahout clusterdump : 分析最后聚类的输出结果,对应的源文件是org.apache.mahout.utils.clustering.ClusterDumper.java
mahout-distribution-0.9.tar.gz的安装的与配置、启动与运行自带的mahout算法
比如
[hadoop@djt002 ~]$ $MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m-00000 -o ~/res.txt
这里,我仅仅是用自带的来测试下。大家根据自己的实际去做。
注意:
/user/hadoop/output
这个输出目录,是mahout自带的kmeans算法里已经写死了的,所以每次,必须清空。
然后
sz res.txt
或者
cat res.txt
例如:
现有一份杂乱的样本数据,我们希望数据最后按照某些类别来划分(红豆分为红豆,绿豆分为绿豆等意思)。
聚类算法会从n个类的初始中心开始(如果没有人为设置,其会按照随机的初始中心开始)
什么意思呢?来看一张图。下面是kmeans算法图解。
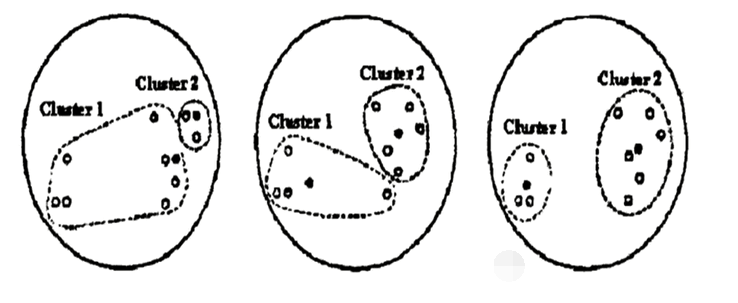
第一张图(左1图)是,我没有指定中心点,让它自己去选,去聚类。
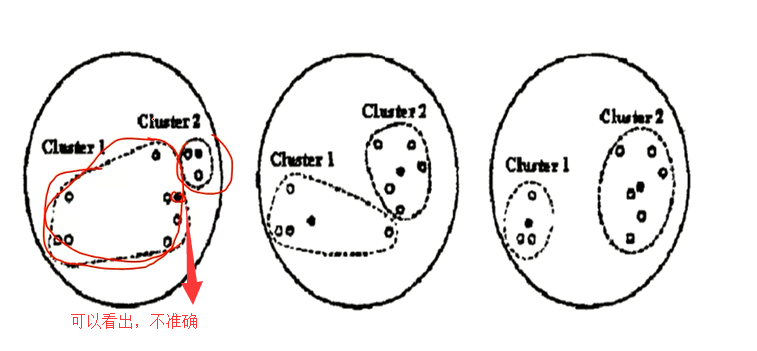
第二张图(中1图),是我们定义的一个k。
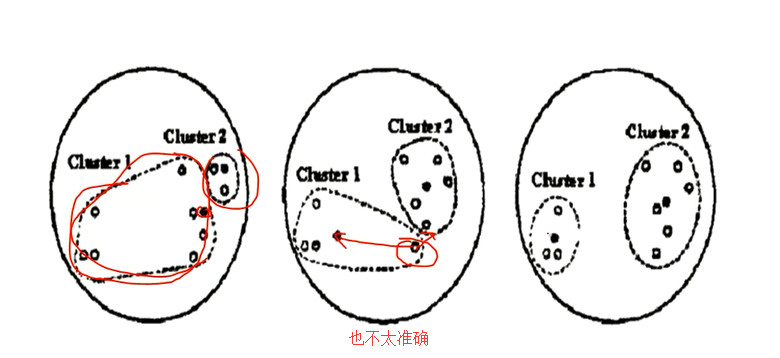
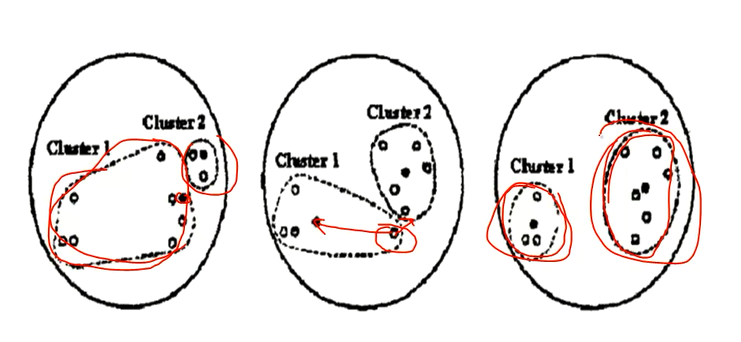
上图中,左一的圆圈图表示原始数据在随机的初始中心划分后的的分布,但是可以看出很明显cluster1中有很多是靠近cluster2的数据点
所以kmeans会根据规则再次计算出更加合适的中心点来进行划分。
这个规则就是:计算每个数据点,到原始中心cluster1和cluster2的距离,离谁比较近就划分到谁那边去(形如中间的圆圈图)。然后将cluster1和cluster2中的数据分别求平均值,得到的两个平均值成为新的cluster1和cluster2中心点。
但是很明显这样划分还是不够合理,所以kmeans会继续迭代计算每个数据到新的中心点的距离,离谁比较近就划分给谁,然后在分别求平均值得到新的中心点
直到cluster1和cluster2中的数据平均值不在发生变化时认为此时是最理想的划分方式(也可以进行人工的干预)。
kmeans图解
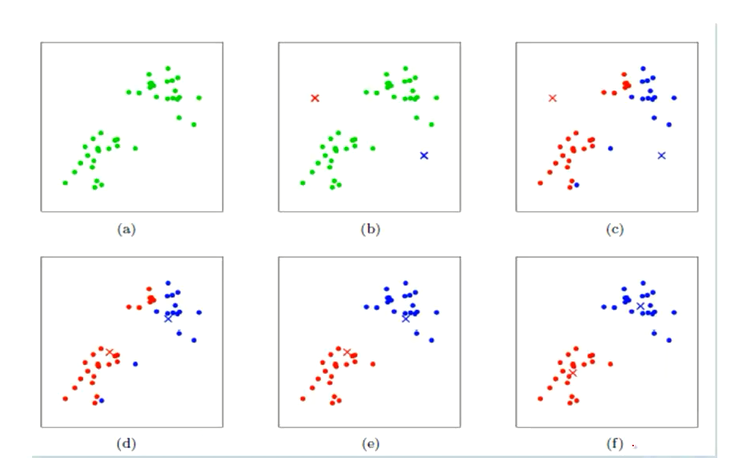
下面展示了对n个样本点进行kmeans聚类的效果,这里K取2。
(a) 准备数据,比如样本数据如图所示。即未聚类的初始点集
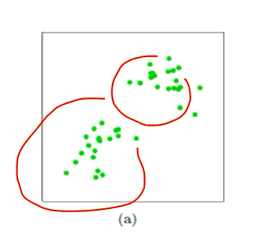
(b) 假设确定两个值,cluster1 和 cluster2。为什么是两个簇,是我们自己定义的。随机选取两个点作为聚类中心
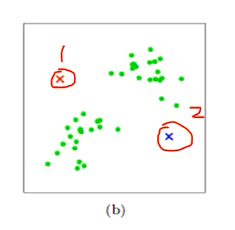
(c) mahout中kmeans会去找每个点, 比较距离1和距离2哪个近,依次迭代下去。计算每个点到聚类中心的聚类,并聚类到离该点最近的聚类中去
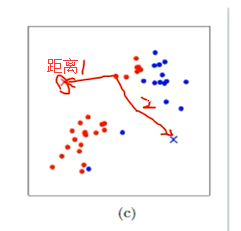
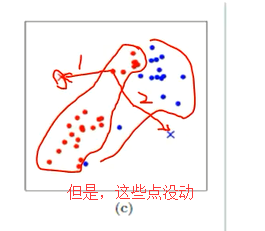
(d)然后呢,把那些红点全部一起取个平均值,把那些蓝点也全部一起取个平均值。 计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。
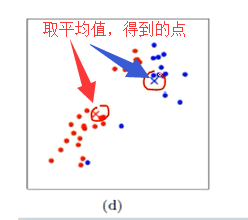
(e) 同时,再根据这平均值后得到的这两个点,分别再算距离。依次迭代,。重复(c),计算每个点到聚类中心的聚类,并聚类到离该点最近的聚类中去
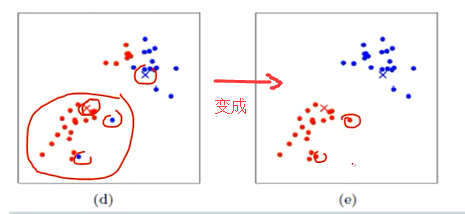
(e) 进一步精确啦!
(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
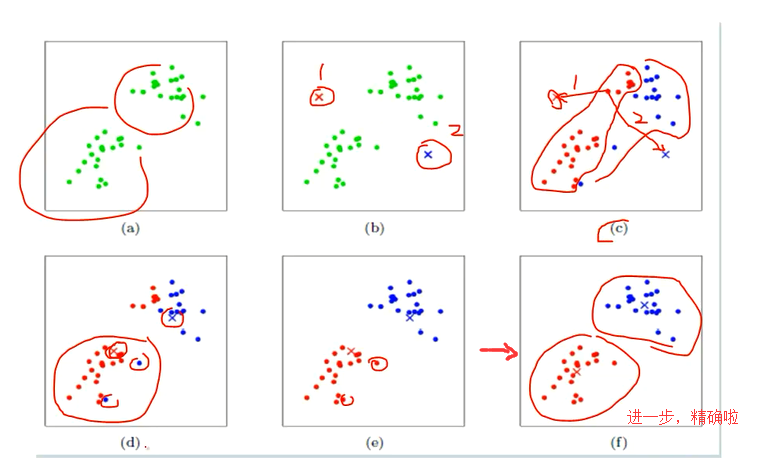
当然,我们若还要进一步更加精确的话,循环(a)(b)(c)(d)(e)这几步。
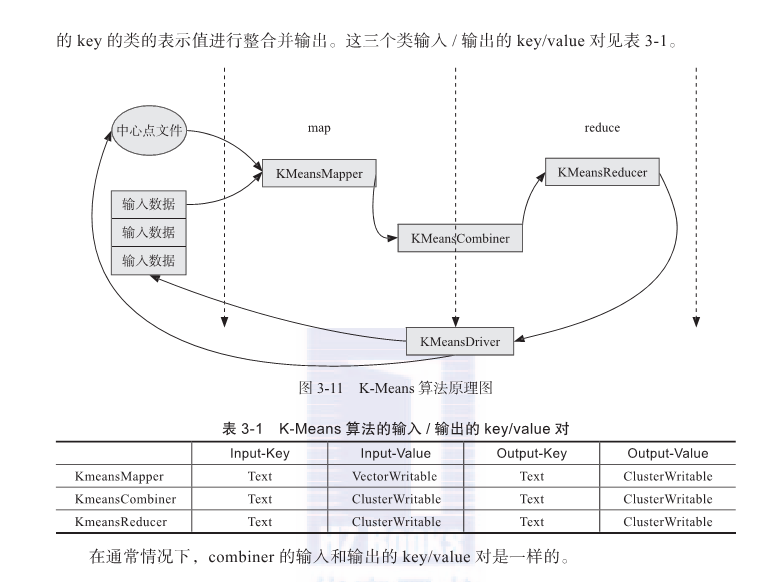
Mahout kmeans的实现(其实就是源码过程)
(1)参数input指定待聚类的所有数据点,clusters指定初始聚类中心
如果指定参数k,由org.apache.mahout.clustering.kmeans.RandomSeedGenerator.buildRandom通过org.apache.hadoop.fs直接从input指定文件中随机读取k个点放入cluster中。
(2)根据原数据点和上次迭代(或初始聚类)的聚类中心计算本次迭代的聚类中心,输出到cluster-N目录下。该过程由org.apache.mahout.clustering.kmeans下的KMeansMapperKMeansCombinerKMeansReducerKMeansDriver实现
KMeansMapper:在configure中初始化mapper时读入上一次跌打产生或初始聚类中心(每个mapper都读入所有的聚类中心);
map方法对输入的每个点,计算距离其最近的类,并加入其中输出key为该点所属聚类ID,value为KMeansInfo实例,包含点的个数和各分量的累加和。
KMeansCombiner: 本地累积KMeansMapper输出的同一聚类ID下的点个数和各分量的和
KMeansReducer : 累加同一聚类ID下的点个数和各分量的和,求本地迭代的聚类中心;并根据输入Delta判断该聚类是否收敛;上一次迭代聚类中心与本次迭代聚类中心距离 < Delta;输出各聚类中心和其是否收敛标记。
KMeansDriver : 控制迭代过程直至超过最大迭代次数或所有聚类都已收敛,每轮迭代后,KMeansDriver读取其clusters-N目录下的所有聚类,若所有聚类已经收敛,则整个kmeans聚类过程收敛了。
参数调整:
manhout kmeans聚类有两个重要参数: 收敛Delta 和 最大迭代次数。
参数介绍
bin/mahout kmeans
-i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-k <optional number of initial clusters to sample from input vectors>
-dm <DistanceMeasure>
-x <maximum number of iterations>
-cd <optional output directory if present>
-ow <overwrite output directory if present>
-cl <run input vector clustering after computing Canopies>
-xm <execution method : sequential or mapreduce>
注意: 当-k被指定的时候, -c目录下的所有聚类都被重写,将从输入的数据向量中随机抽取-k个点作为初始聚类的中心。
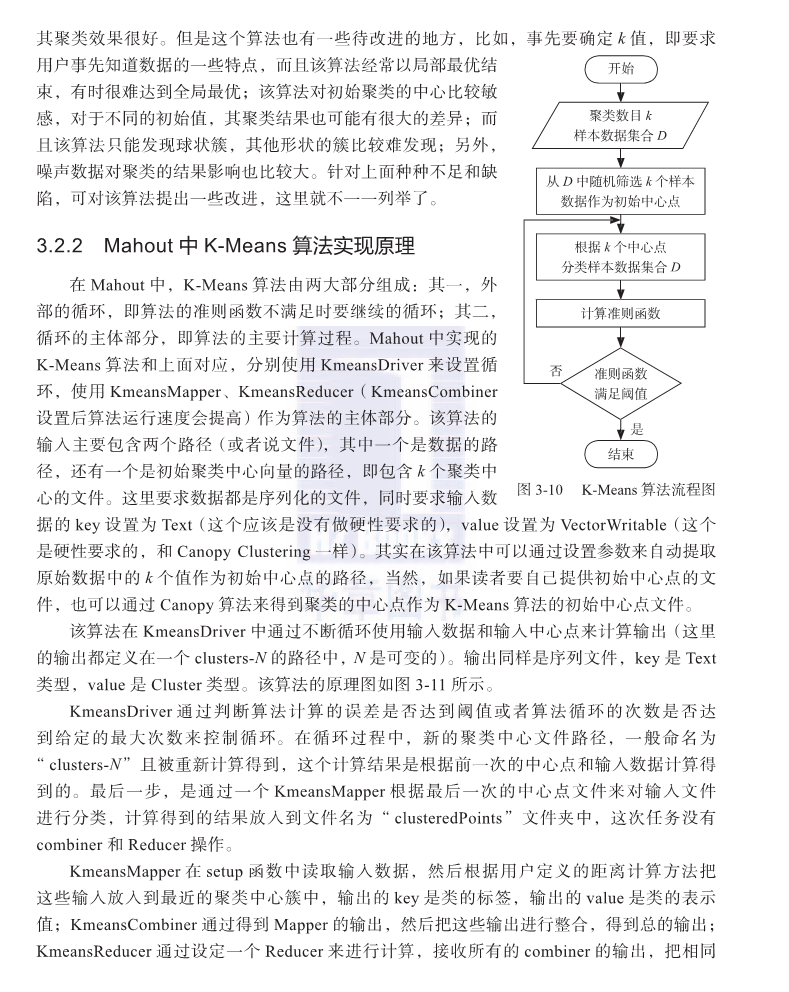
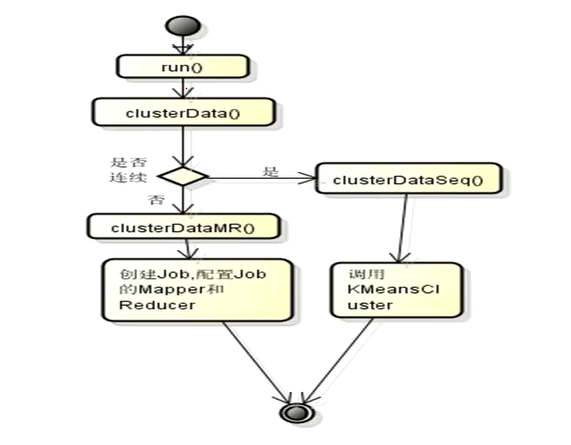
kmeans流程图
案例零售retail.dat
http://fimi.ua.ac.be/data/
通过官网下载得到数据,或者拿最下面的数据也可以。
测试数据下载tail.txt(电商购物车数据)
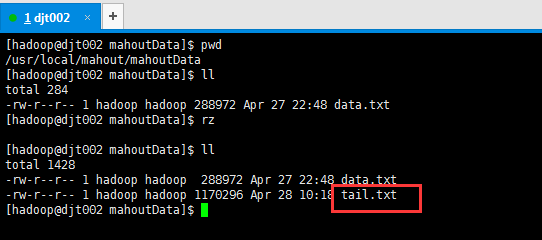
[hadoop@djt002 mahoutData]$ pwd /usr/local/mahout/mahoutData [hadoop@djt002 mahoutData]$ ll total 284 -rw-r--r-- 1 hadoop hadoop 288972 Apr 27 22:48 data.txt [hadoop@djt002 mahoutData]$ rz [hadoop@djt002 mahoutData]$ ll total 1428 -rw-r--r-- 1 hadoop hadoop 288972 Apr 27 22:48 data.txt -rw-r--r-- 1 hadoop hadoop 1170296 Apr 28 10:18 tail.txt [hadoop@djt002 mahoutData]$
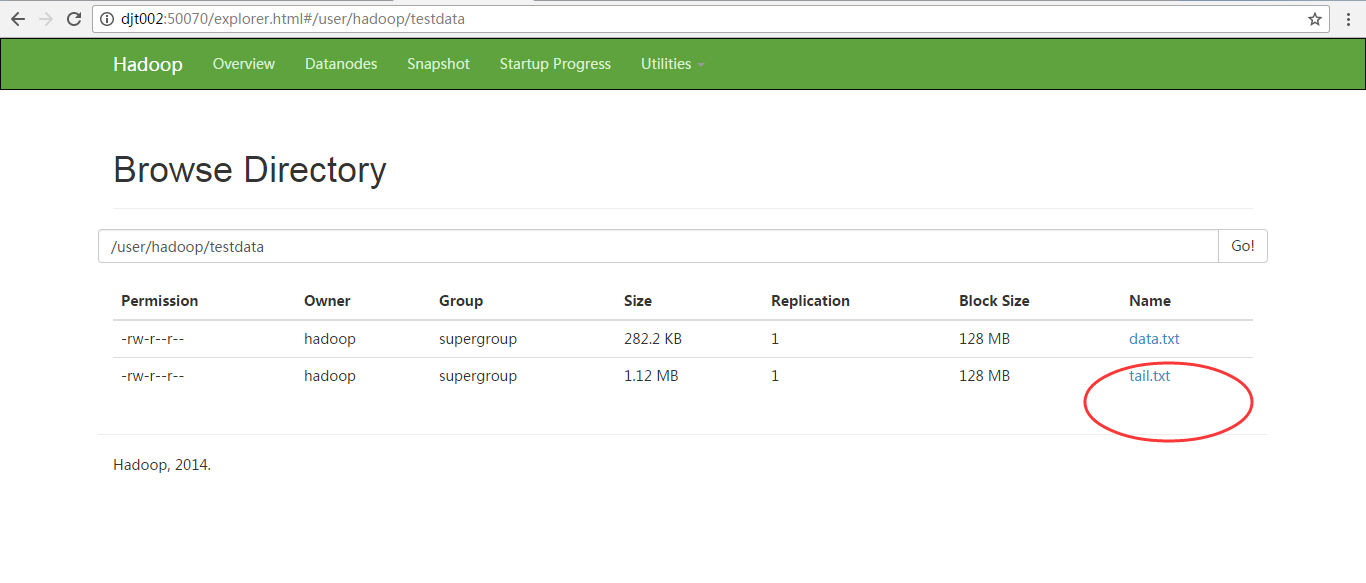
将这个数据tail.txt上传到hdfs://djt002://9000/user/hadoop/testdata/下(通过以下命令)
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/tail.txt hdfs://djt002:9000/user/hadoop/testdata/
或者
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /usr/local/mahout/mahoutData/tail.txt hdfs://djt002:9000/user/hadoop/testdata/

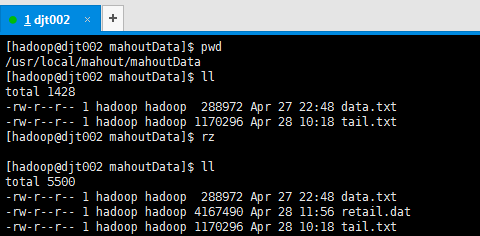
[hadoop@djt002 mahoutData]$ pwd /usr/local/mahout/mahoutData [hadoop@djt002 mahoutData]$ ll total 1428 -rw-r--r-- 1 hadoop hadoop 288972 Apr 27 22:48 data.txt -rw-r--r-- 1 hadoop hadoop 1170296 Apr 28 10:18 tail.txt [hadoop@djt002 mahoutData]$ rz [hadoop@djt002 mahoutData]$ ll total 5500 -rw-r--r-- 1 hadoop hadoop 288972 Apr 27 22:48 data.txt -rw-r--r-- 1 hadoop hadoop 4167490 Apr 28 11:56 retail.dat -rw-r--r-- 1 hadoop hadoop 1170296 Apr 28 10:18 tail.txt

[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -mkdir hdfs://djt002:9000/user/hadoop/mahoutData [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -put /usr/local/mahout/mahoutData/retail.dat hdfs://djt002:9000/user/hadoop/mahoutData/ [hadoop@djt002 mahoutData]$
注意,是不需输入路径和输出路径的啊!(自带的jar包里都已经写死了的)
(注意:如果你是选择用mahout压缩包里自带的kmeans算法的话,则它的输入路径是testdata是固定死的,
即hdfs:djt002://9000/user/hadoop/testdata/ )
并且每次运行hadoop都要删掉原来的output目录!
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm hdfs://djt002:9000/user/hadoop/testdata/data.txt [hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm hdfs://djt002:9000/user/hadoop/testdata/tail.txt
通过以下命令去清空输入目录(没办吧,因为mahout自带的kmeans算法已经写死了)(为了保证输入数据每次只有一个,不混淆)

通过以下命令去清空输出目录(没办吧,因为mahout自带的kmeans算法已经写死了)
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop fs -rm -r hdfs://djt002:9000/user/hadoop/output/*
使用mahout自带的fpg算法来对我们的测数据retail.dat进行kmeans算法(但是0.9及其以后版本照样可以用,但是格式要注意)
这里选择mahout中的自带的FpGrowth算法
$MAHOUT_HOME/bin/mahout fpg -i /user/hadoop/mahoutData/retail.dat -0 /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
各个参数的意义:
-i:指定输入数据的路径
-o:指定输出结果的路径
-method:指定使用mapreduce方法
-s:最小支持度
-regex:使用指定的正则来匹配过滤数据
我这里是,用的是自定义的是输入路径和输出路径。
当然你也可以,用默认的输入路径是/user/hadoop/testdata , 默认的输出路径是/user/hadoop/output
$MAHOUT_HOME/bin/mahout fpg -i /user/hadoop/testdata/retail.dat -0 /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
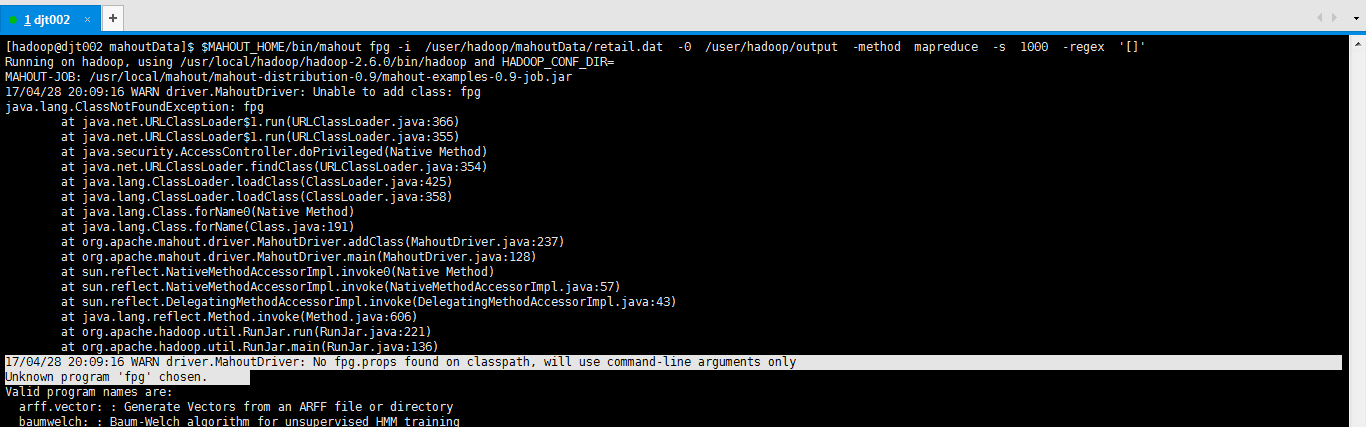
[hadoop@djt002 mahoutData]$ $MAHOUT_HOME/bin/mahout fpg -i /user/hadoop/mahoutData/retail.dat -0 /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
Running on hadoop, using /usr/local/hadoop/hadoop-2.6.0/bin/hadoop and HADOOP_CONF_DIR=
MAHOUT-JOB: /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar
17/04/28 20:09:16 WARN driver.MahoutDriver: Unable to add class: fpg
java.lang.ClassNotFoundException: fpg
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:191)
at org.apache.mahout.driver.MahoutDriver.addClass(MahoutDriver.java:237)
at org.apache.mahout.driver.MahoutDriver.main(MahoutDriver.java:128)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
17/04/28 20:09:16 WARN driver.MahoutDriver: No fpg.props found on classpath, will use command-line arguments only
Unknown program 'fpg' chosen.
对于mahout0.9及其以后版本,不能直接这么来干。
org.apache.mahout.fpm.pfpgrowth.FPGrowthDriver 等价于 fpg
得换成如下
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.fpm.pfpgrowth.FPGrowthDriver -i /user/hadoop/testdata/retail.dat -o /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
或者(自定义输入路径和输出路径)
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.fpm.pfpgrowth.FPGrowthDriver -i /user/hadoop/mahoutData/retail.dat -o /user/hadoop/output -method mapreduce -s 1000 -regex '[]'
[hadoop@djt002 ~]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.fpm.pfpgrowth.FPGrowthDriver -i /user/hadoop/testdata/retail.dat -o /user/hadoop/output --method mapreduce --s 200 --regex '[]' -k 20
现在开始使用mahout自带的kmeans算法来对我们的测数据retail.dat进行kmeans算法!
这里是用默认的输入路径/user/hadoop/testdata 和 默认的输出路径 /user/hadoop/output
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
或者,你可以用自定义的输入路径和输出路径
[hadoop@djt002 mahoutData]$ $HADOOP_HOME/bin/hadoop jar /usr/local/mahout/mahout-distribution-0.9/mahout-examples-0.9-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job -i /user/hadoop/mahoutData/retail.txt -o /user/hadoop/output
如果你在这一步,遇到这个问题,则见
Error: org.apache.mahout.math.CardinalityException: Required cardinality 10 but got 30问题解决办法
同样的,运行结果的数据要通过seqdumper来查看
$MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/data/part-m-00000 -o ~/retail_kmeans.txt
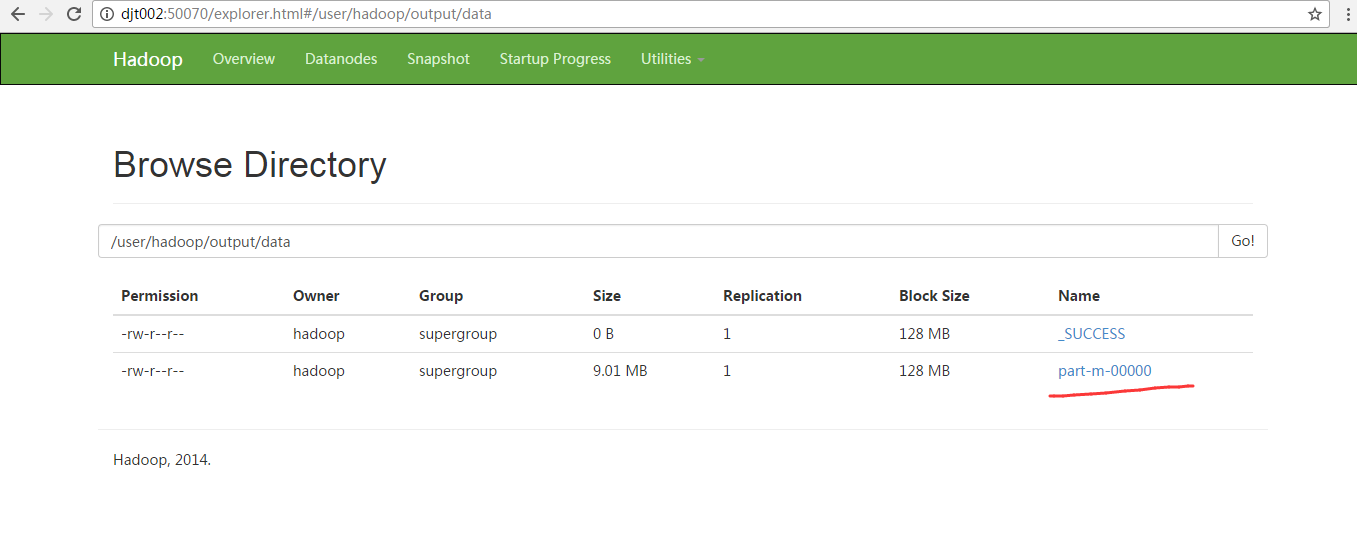
或者
$MAHOUT_HOME/bin/mahout seqdumper -i /user/hadoop/output/cluster-1/ -o ~/retail_kmeans.txt
这些都是自己弄的。
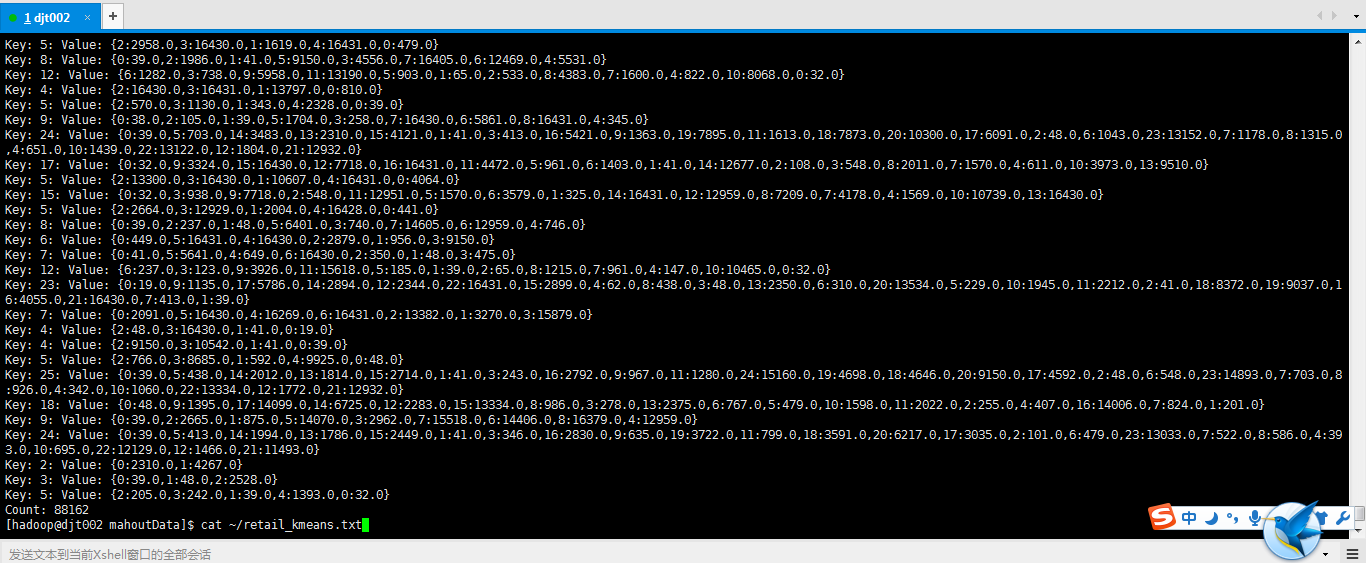
cat
~/retail_kmeans.txt
http://www.cnblogs.com/fengfenggirl/p/associate_mahout.html
http://book.51cto.com/art/201406/442565.htm