Git 、CVS、SVN比较
项目源代码的版本管理工具中,比较常用的主要有:CVS、SVN、Git 和 Mercurial (其中,关于SVN,请参见我的博客:SVN学习系列)
目前Google Code支持SVN、Git、Mercurial三种方式,例如: linux-kernel-source(Git 方式)、sdk-java(SVN方式),那么它们各有什么区别呢?
1、Git与CVS 的区别
- 分支更快、更容易。
- 支持离线工作;本地提交可以稍后提交到服务器上。
- Git 提交都是原子的,且是整个项目范围的,而不像 CVS 中一样是对每个文件的。
- Git 中的每个工作树都包含一个具有完整项目历史的仓库。
- 没有哪一个 Git 仓库会天生比其他仓库更重要。
2、Git与SVN 的区别
Git 不仅仅是个版本控制系统,它也是个内容管理系统(CMS)、工作管理系统等。如果你曾是一个使用过SVN背景的人,那么你可以很容易的做一定的思想转换,来适应Git提供的一些概念和特征。这篇文章的主要目的就是通过介绍Git能做什么,以及它和SVN在深层次上究竟有什么不同,通过比较来帮助你更好的认识Git。
(1)Git是分布式的,SVN不是
这是Git和其它非分布式的版本控制系统(SVN,CVS)最核心的区别。如果你能理解这个概念,那么你就已经上手一半了。需要做一点声明,Git并不是目前第一个或唯一的分布式版本控制系统。还有一些系统如 Bitkeeper, Mercurial 等也是运行在分布式模式上的,但Git在这方面做的更好,而且有更多强大的功能特征。
Git 跟SVN一样有自己的集中式版本库或服务器。但 Git 更倾向于被使用于分布式模式,也就是每个开发人员从中心版本库的服务器上chect out代码后会在自己的机器上克隆一个自己的版本库。可以这样说,如果你被困在一个不能连接网络的地方时,就像在飞机上,地下室,电梯里等,你仍然能够提交文件,查看历史版本记录,创建项目分支等。对一些人来说,这好像没多大用处,但当你突然遇到没有网络的环境时,这个将解决你的大麻烦。
同样,这种分布式的操作模式对于开源软件社区的开发来说也是个巨大的恩赐,你不必再像以前那样做出补丁包,通过email方式发送出去,你只需要创建一个分支,向项目团队发送一个推请求。这能让你的代码保持最新,而且不会在传输过程中丢失,一个这样的优秀案例就是: GitHub.com
有些谣言传出来说subversion将来的版本也会基于分布式模式。但至少目前还看不出来。
(2)Git 把内容按元数据方式存储,而SVN是按文件
所有的资源控制系统都是把文件的元信息隐藏在一个类似.svn、.cvs等的文件夹里。如果你把 .git 目录的体积大小跟.svn比较,你会发现它们差距很大。因为 .git 目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签、分支、版本记录等。
(3)Git 分支和SVN的分支不同
分支在SVN中一点不特别,就是版本库中的另外的一个目录。如果你想知道是否合并了一个分支,你需要手工运行像这样的命令svn propget svn:mergeinfo,来确认代码是否被合并。所以,经常会发生有些分支被遗漏的情况。
然而,处理Git 的分支却是相当的简单和有趣,你可以从同一个工作目录下快速的在几个分支间切换。你很容易发现未被合并的分支,你能简单而快捷的合并这些文件。
(4)Git 没有一个全局的版本号,而SVN有
目前为止这是跟SVN相比GIT缺少的最大的一个特征。你也知道,SVN的版本号实际是任何一个相应时间的源代码快照,它是从CVS进化到SVN的最大的一个突破。Git 可以使用SHA-1来唯一的标识一个代码快照,但这个并不能完全的代替SVN里容易阅读的数字版本号。
(5)Git 的内容完整性要优于SVN
Git 的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
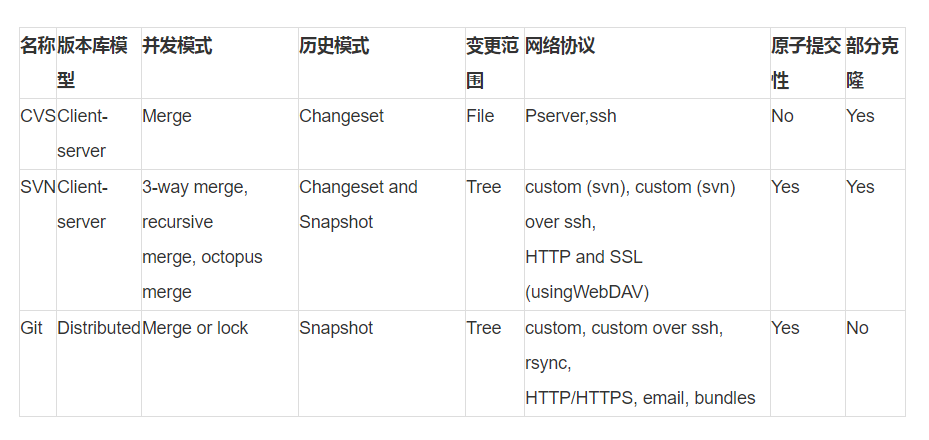
CVS-SVN-GIT综合比较
首先,介绍几个版本控制软件相互比较的重要依据:
(1)版本库模型(Repository model):描述了多个源码版本库副本间的关系,有客户端/服务器和分布式两种模式。在客户端/服务器模式下,每一用户通过客户端访问位于服务器的主版本库,每一客户机只需保存它所关注的文件副本,对当前工作副本(working copy)的更改只有在提交到服务器之后,其它用户才能看到对应文件的修改。而在分布式模式下,这些源码版本库副本间是对等的实体,用户的机器出了保存他们的工作副本外,还拥有本地版本库的历史信息。
(2)并发模式(Concurrency model):描述了当同时对同一工作副本/文件进行更改或编辑时,如何管理这种冲突以避免产生无意义的数据,有排它锁和合并模式。在排它锁模式下,只有发出请求并获得当前文件排它锁的用户才能对对该文件进行更改。而在合并模式下,用户可以随意编辑或更改文件,但可能随时会被通知存在冲突(两个或多个用户同时编辑同一文件),于是版本控制工具或用户需要合并更改以解决这种冲突。因此,几乎所有的分布式版本控制软件采用合并方式解决并发冲突。
(3)历史模式(History model):描述了如何在版本库中存贮文件的更改信息,有快照和改变集两种模式。在快照模式下,版本库会分别存储更改发生前后的工作副本;而在改变集模式下,版本库除了保存更改发生前的工作副本外,只保存更改发生后的改变信息。
(4)变更范围(Scope of change):描述了版本编号是针对单个文件还是整个目录树。
(5)网络协议(Network protocols):描述了多个版本库间进行同步时采用的网络协议。
(6)原子提交性(Atomic commit):描述了在提交更改时,能否保证所有更改要么全部提交或合并,要么不会发生任何改变。
(7)部分克隆(Partial checkout/clone):是否支持只拷贝版本库中特定的子目录。
Trunk、Branches、Tags 区别:
Trunk:软件开发过程中的主线,开发时版本存放的目录,即在开发阶段的代码都提交到该目录上,保存了从版本库建立到当前的信息。
Branches:软件开发过程中的分支,发布版本存放的目录,即项目上线时发布的稳定版本存放在该目录中,保存了从版本库的某一特定点(不一定是版本库建立时)到当前的信息。
tags:表示标签存放的目录,tags只可读,不可写
分支主要用于在不影响Trunk其它用户情况下进行一些关于新功能的探索性或实验性的开发,待新功能完善后它也可以合并到Trunk中。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
以及对应本平台的QQ群:161156071(大数据躺过的坑)