我们是如何记录声音的呢?
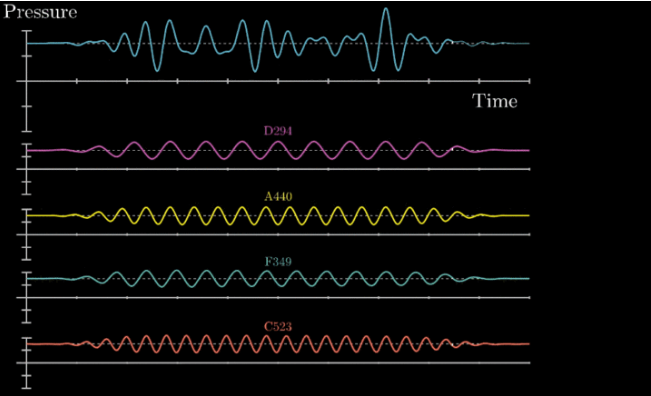
如果你测量的是扬声器旁的气压,那么它会是一个随时间以正弦函数形态不断震荡的图像,一个标准音 A(下图黄色),它的频率是440Hz,表示每秒钟振动440次,比它低一些的D(下图紫红),是294Hz,振动的慢一些。
如果这两个音同时发出,产生的气压随时间曲线怎么决定呢?如下图,其实就是把所有时间点的振幅加起来。

反过来,我们获得声音的波形,可以根据傅里叶变换分离出其中包含的所有频率的波形。
与声音有关的三个参数:
采样频率:
又称取样频率。是单位时间内的采样次数,决定了数字化音频的质量。采样频率越高,数字化音频的质量越好,还原的波形越完整,播放的声音越真实,当然所占的资源也越多。根据奎特采样定理,要从采样中完全恢复原始信号的波形,采样频率要高于声音中最高频率的两倍。人耳可听到的声音的频率范围是在16Hz-20kHz之间。因此,要将听到的原声音真实地还原出来,采样频率必须大于40kHz 。常用的采样频率有8kHz 、11.025kHz 、22.05kHz、44.1kHz、48kHz等几种。22.05kHz相当于普通FM广播的音质,44.1kHz理论上可达到CD的音质。对于高于48KHz的采样频率人耳很难分辨,没有实际意义。
采样位数:
也叫量化位数(单位:比特),是存储每个采样值所用的二进制位数。采样值反应了声音的波动状态。采样位数决定了量化精度。采样位数越长,量化的精度就越高,还原的波形曲线越真实,产生的量化噪声越小,回放的效果就越逼真。常用的量化位数有4、8、12、16、24。量化位数与声卡的位数和编码有关。如果采用PCM编码同时使用8 位声卡,可将音频信号幅度从上限到下限化分成256个音量等级,取值范围为0-255;使用16位声卡,可将音频信号幅度划分成了64K个音量等级,取值范围为-32768至32767。
声道数:
是使用的声音通道的个数,也是采样时所产生的声音波形的个数。播放声音时,单声道的WAV一般使用一个喇叭发声,立体声的WAV可以使两个喇叭发声。记录声音时,单声道每次产生一个波形的数据,双声道每次产生两个波形的数据,所占的存储空间增加一倍。
声音CD中使用的取样频率是每秒44,100个样本,或者称为44.1kHz。这个特有的数值是这样产生的:
- 人耳可听到最高20kHz的声音,因此要拦截人能听到的整个声音范围,就需要40kHz的取样频率。
- 然而,由于低通滤波器具有频率下滑效应,所以取样频率应该再高出大约百分之十才行。取样频率就达到了44kHz。
- 这时,我们要与视讯同时记录数字声音,于是取样频率就应该是美国、欧洲电视显示格速率的整数倍,这两种视讯格速率分别是30Hz和25Hz。这就使取样频率升高到了44.1kHz。