一、Hadoop是什么?
Hadoop是开源的分布式存储和分布式计算平台
二、Hadoop包含两个核心组成:
1、HDFS: 分布式文件系统,存储海量数据
a、基本概念
-块(block)
HDFS的文件被分成块进行存储,每个块的默认大小64MB
块是文件存储处理的逻辑单元
-NameNode
管理节点,存放文件元数据,包括:
(1)文件与数据块的映射表
(2)数据块与数据节点的映射表
-DataNode
是HDFS的工作节点,存放数据块
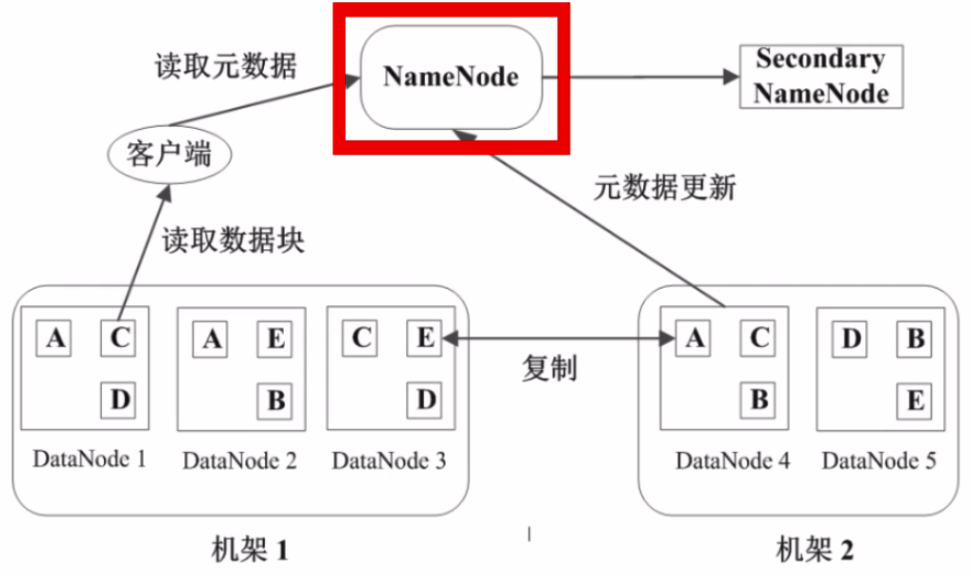
b、数据管理策略
11、数据块副本
每个数据块三个副本,分布在两个机架内的三个节点,以防数据故障丢失
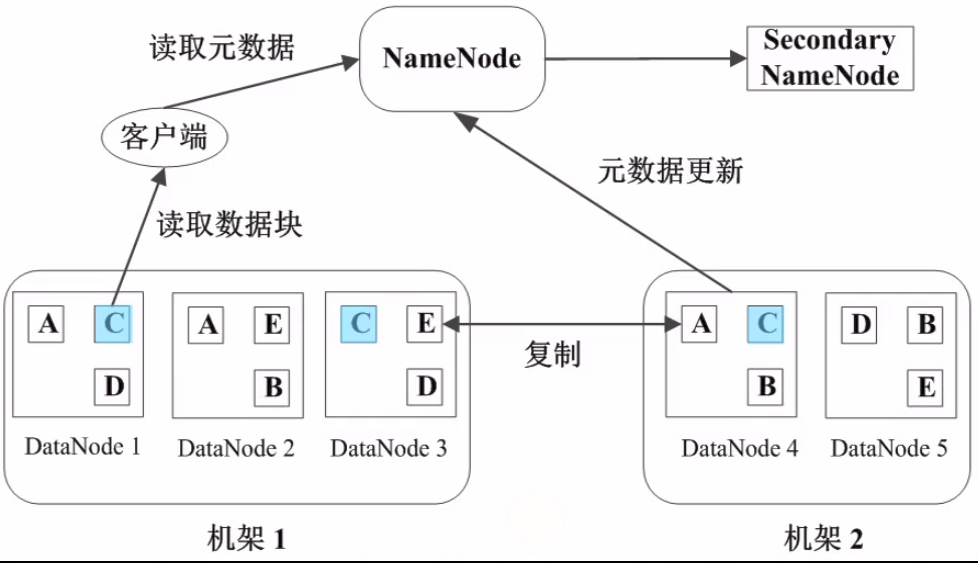
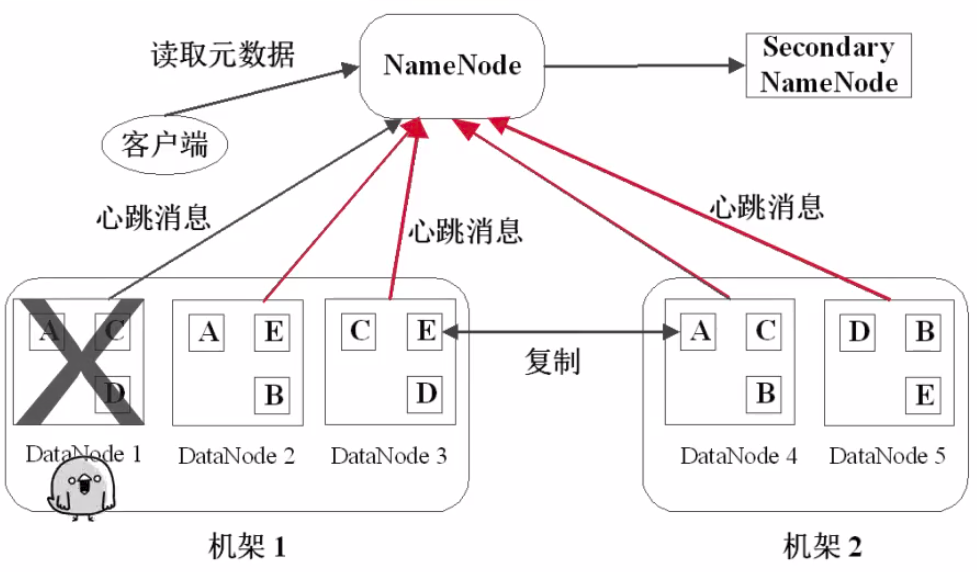
22、心跳检测:
DataNode定期向NameNode发送心跳信息
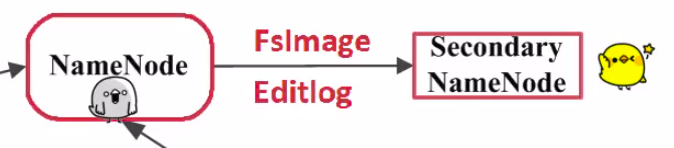
33、二级NameNode(Secondary NameNode)
二级NameNode定期同步元数据映像文件和修改日志,NameNode发生故障时,备胎转正
44、HDFS文件读取的流程
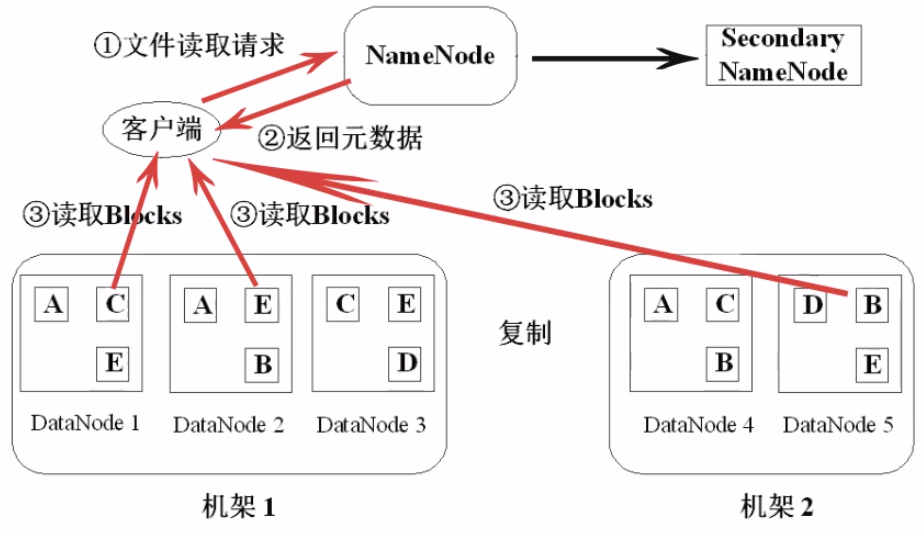
55、HDFS写入文件的流程
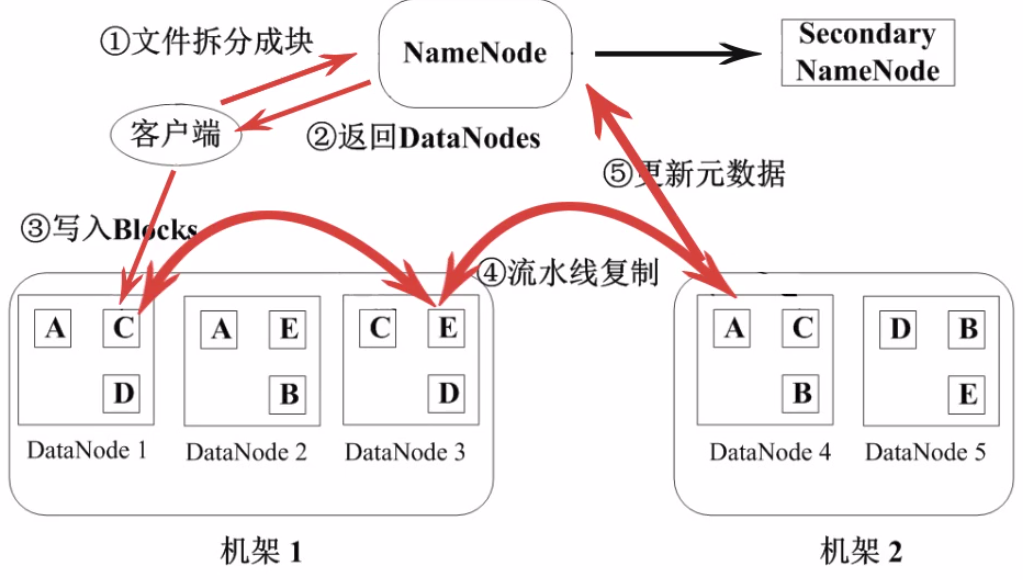
66、HDFS的特点
数据冗余,硬件容错
流式的数据访问,一次写入多次读取,一旦写入无法修改,要修改只有删除重写
存储大文件,小文件NameNode压力会很大
77、适用性和局限性
适合数据批量读写,吞吐量高
不适合交互式应用,低延迟很难满足
适合一次写入多次读取,顺序读写
不支持多用户并发写相同文件
2、Mapreduce:并行处理框架,实现任务分解和调度
a、Mapreduce的原理
分而治之,一个大任务分成多个小的子任务(map),由多个节点并行执行后,合并结果(reduce)
b、Mapreduce的运行流程
11、基本概念
- Job & Task
job → Task(maptask, reducetask)
- JobTracker
作业任务
分配任务、监控任务执行进度
监控TaskTracker的状态
- TaskTracker
执行任务
汇报任务状态
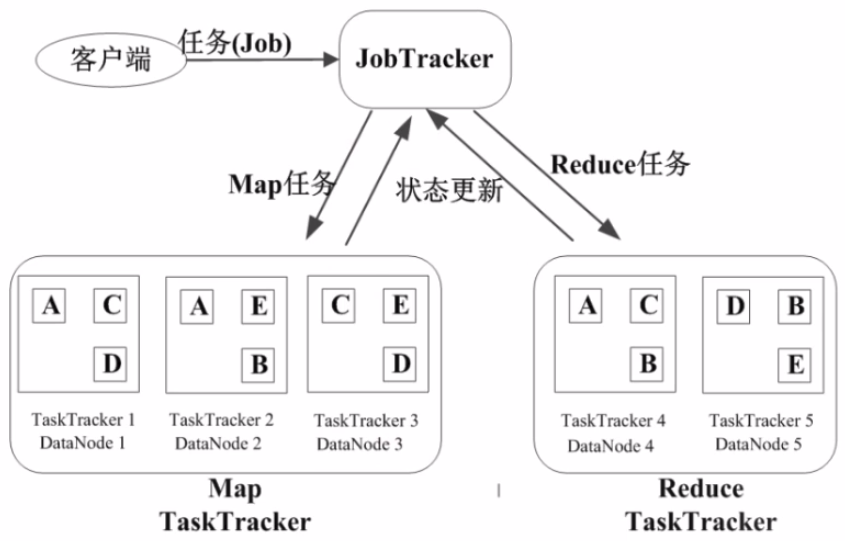
22、作业执行过程
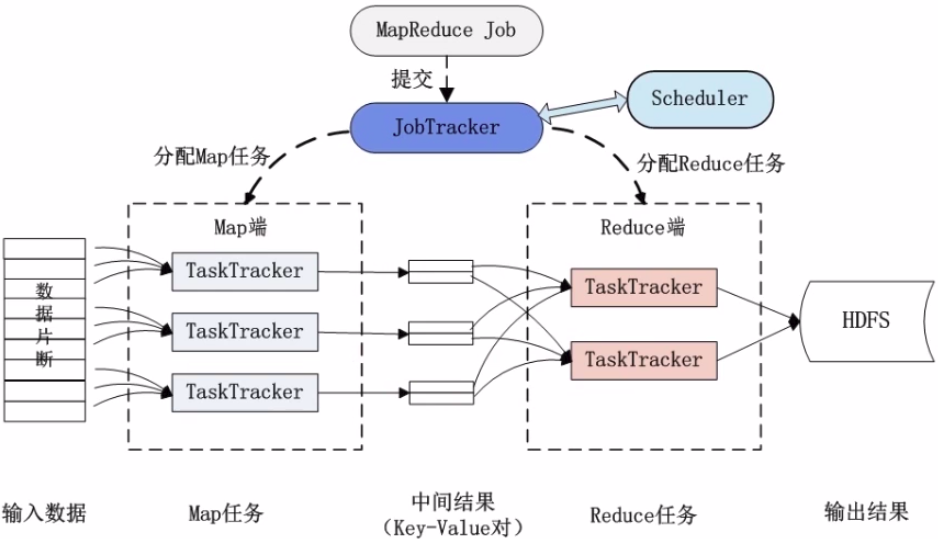
33、Mapreduce的容错机制
重复执行
推测执行
三、可用来做什么
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务
如:搜索引擎、商业智能、日志分析、数据挖掘
四、Hadoop优势
1、高扩展
可通过增加一些硬件,使得性能和容量提升
2、低成本
普通PC即可实现,堆叠系统,通过软件方面的容错来保证系统的可靠性
3、成熟的生态圈
如:Hive, Hbase
五、HDFS操作
1、shell命令操作
常用HDFS Shell命令:
类Linux系统:ls, cat, mkdir, rm, chmod, chown等
HDFS文件交互:copyFromLocal、copyToLocal、get(下载)、put(上传)
六、Hadoop生态圈
七、Mapreduce操作实战
本例中为了实现读取某个文档,并统计文档中各单词的数量
先建立hdfs_map.py用于读取文档数据
# hdfs_map.py import sys def read_input(file): for line in file: yield line.split() def main(): data = read_input(sys.stdin) for words in data: for word in words: print('{} 1'.format(word)) if __name__ == '__main__': main()
建立hdfs_reduce.py用于统计各单词数量
# hdfs_reduce.py import sys from operator import itemgetter from itertools import groupby def read_mapper_output(file, separator=' '): for line in file: yield line.rstrip().split(separator, 1) def main(): data = read_mapper_output(sys.stdin) for current_word, group in groupby(data, itemgetter(0)): total_count = sum(int(count) for current_word, count in group) print('{} {}'.format(current_word, total_count)) if __name__ == '__main__': main()
事先建立文档mk.txt,并编辑部分内容,然后粗如HDFS中
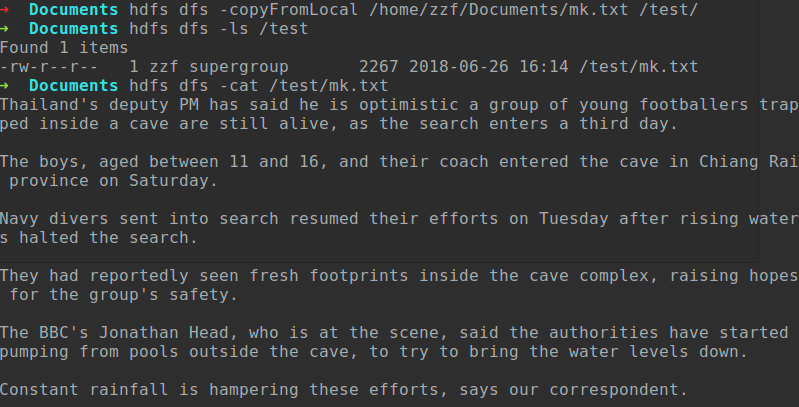
在命令行中运行Mapreduce操作
hadoop jar /opt/hadoop-2.9.1/share/hadoop/tools/lib/hadoop-streaming-2.9.1.jar -files '/home/zzf/Git/Data_analysis/Hadoop/hdfs_map.py,/home/zzf/Git/Data_analysis/Hadoop/hdfs_reduce.py' -input /test/mk.txt -output /output/wordcount -mapper 'python3 hdfs_map.py' -reducer 'python3 hdfs_reduce.py'
运行如下


1 ➜ Documents hadoop jar /opt/hadoop-2.9.1/share/hadoop/tools/lib/hadoop-streaming-2.9.1.jar -files '/home/zzf/Git/Data_analysis/Hadoop/hdfs_map.py,/home/zzf/Git/Data_analysis/Hadoop/hdfs_reduce.py' -input /test/mk.txt -output /output/wordcount -mapper 'python3 hdfs_map.py' -reducer 'python3 hdfs_reduce.py' 2 # 结果 3 18/06/26 16:22:45 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id 4 18/06/26 16:22:45 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId= 5 18/06/26 16:22:45 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized 6 18/06/26 16:22:46 INFO mapred.FileInputFormat: Total input files to process : 1 7 18/06/26 16:22:46 INFO mapreduce.JobSubmitter: number of splits:1 8 18/06/26 16:22:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local49685846_0001 9 18/06/26 16:22:46 INFO mapred.LocalDistributedCacheManager: Creating symlink: /home/zzf/hadoop_tmp/mapred/local/1530001366609/hdfs_map.py <- /home/zzf/Documents/hdfs_map.py 10 18/06/26 16:22:46 INFO mapred.LocalDistributedCacheManager: Localized file:/home/zzf/Git/Data_analysis/Hadoop/hdfs_map.py as file:/home/zzf/hadoop_tmp/mapred/local/1530001366609/hdfs_map.py 11 18/06/26 16:22:47 INFO mapred.LocalDistributedCacheManager: Creating symlink: /home/zzf/hadoop_tmp/mapred/local/1530001366610/hdfs_reduce.py <- /home/zzf/Documents/hdfs_reduce.py 12 18/06/26 16:22:47 INFO mapred.LocalDistributedCacheManager: Localized file:/home/zzf/Git/Data_analysis/Hadoop/hdfs_reduce.py as file:/home/zzf/hadoop_tmp/mapred/local/1530001366610/hdfs_reduce.py 13 18/06/26 16:22:47 INFO mapreduce.Job: The url to track the job: http://localhost:8080/ 14 18/06/26 16:22:47 INFO mapred.LocalJobRunner: OutputCommitter set in config null 15 18/06/26 16:22:47 INFO mapreduce.Job: Running job: job_local49685846_0001 16 18/06/26 16:22:47 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapred.FileOutputCommitter 17 18/06/26 16:22:47 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 18 18/06/26 16:22:47 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 19 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Waiting for map tasks 20 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Starting task: attempt_local49685846_0001_m_000000_0 21 18/06/26 16:22:47 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 22 18/06/26 16:22:47 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 23 18/06/26 16:22:47 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 24 18/06/26 16:22:47 INFO mapred.MapTask: Processing split: hdfs://localhost:9000/test/mk.txt:0+2267 25 18/06/26 16:22:47 INFO mapred.MapTask: numReduceTasks: 1 26 18/06/26 16:22:47 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 27 18/06/26 16:22:47 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 28 18/06/26 16:22:47 INFO mapred.MapTask: soft limit at 83886080 29 18/06/26 16:22:47 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 30 18/06/26 16:22:47 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 31 18/06/26 16:22:47 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 32 18/06/26 16:22:47 INFO streaming.PipeMapRed: PipeMapRed exec [/usr/bin/python3, hdfs_map.py] 33 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.work.output.dir is deprecated. Instead, use mapreduce.task.output.dir 34 18/06/26 16:22:47 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start 35 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 36 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 37 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 38 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir 39 18/06/26 16:22:47 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file 40 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 41 18/06/26 16:22:47 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length 42 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 43 18/06/26 16:22:47 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name 44 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 45 18/06/26 16:22:47 INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s] 46 18/06/26 16:22:47 INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s] 47 18/06/26 16:22:47 INFO streaming.PipeMapRed: Records R/W=34/1 48 18/06/26 16:22:47 INFO streaming.PipeMapRed: MRErrorThread done 49 18/06/26 16:22:47 INFO streaming.PipeMapRed: mapRedFinished 50 18/06/26 16:22:47 INFO mapred.LocalJobRunner: 51 18/06/26 16:22:47 INFO mapred.MapTask: Starting flush of map output 52 18/06/26 16:22:47 INFO mapred.MapTask: Spilling map output 53 18/06/26 16:22:47 INFO mapred.MapTask: bufstart = 0; bufend = 3013; bufvoid = 104857600 54 18/06/26 16:22:47 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26212876(104851504); length = 1521/6553600 55 18/06/26 16:22:47 INFO mapred.MapTask: Finished spill 0 56 18/06/26 16:22:47 INFO mapred.Task: Task:attempt_local49685846_0001_m_000000_0 is done. And is in the process of committing 57 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Records R/W=34/1 58 18/06/26 16:22:47 INFO mapred.Task: Task 'attempt_local49685846_0001_m_000000_0' done. 59 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Finishing task: attempt_local49685846_0001_m_000000_0 60 18/06/26 16:22:47 INFO mapred.LocalJobRunner: map task executor complete. 61 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Waiting for reduce tasks 62 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Starting task: attempt_local49685846_0001_r_000000_0 63 18/06/26 16:22:47 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1 64 18/06/26 16:22:47 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 65 18/06/26 16:22:47 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 66 18/06/26 16:22:47 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@257adccd 67 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10 68 18/06/26 16:22:47 INFO reduce.EventFetcher: attempt_local49685846_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 69 18/06/26 16:22:47 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local49685846_0001_m_000000_0 decomp: 3777 len: 3781 to MEMORY 70 18/06/26 16:22:47 INFO reduce.InMemoryMapOutput: Read 3777 bytes from map-output for attempt_local49685846_0001_m_000000_0 71 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 3777, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->3777 72 18/06/26 16:22:47 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning 73 18/06/26 16:22:47 INFO mapred.LocalJobRunner: 1 / 1 copied. 74 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 75 18/06/26 16:22:47 INFO mapred.Merger: Merging 1 sorted segments 76 18/06/26 16:22:47 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 3769 bytes 77 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: Merged 1 segments, 3777 bytes to disk to satisfy reduce memory limit 78 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: Merging 1 files, 3781 bytes from disk 79 18/06/26 16:22:47 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce 80 18/06/26 16:22:47 INFO mapred.Merger: Merging 1 sorted segments 81 18/06/26 16:22:47 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 3769 bytes 82 18/06/26 16:22:47 INFO mapred.LocalJobRunner: 1 / 1 copied. 83 18/06/26 16:22:47 INFO streaming.PipeMapRed: PipeMapRed exec [/usr/bin/python3, hdfs_reduce.py] 84 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address 85 18/06/26 16:22:47 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 86 18/06/26 16:22:47 INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s] 87 18/06/26 16:22:47 INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s] 88 18/06/26 16:22:47 INFO streaming.PipeMapRed: R/W/S=100/0/0 in:NA [rec/s] out:NA [rec/s] 89 18/06/26 16:22:47 INFO streaming.PipeMapRed: Records R/W=381/1 90 18/06/26 16:22:47 INFO streaming.PipeMapRed: MRErrorThread done 91 18/06/26 16:22:47 INFO streaming.PipeMapRed: mapRedFinished 92 18/06/26 16:22:47 INFO mapred.Task: Task:attempt_local49685846_0001_r_000000_0 is done. And is in the process of committing 93 18/06/26 16:22:47 INFO mapred.LocalJobRunner: 1 / 1 copied. 94 18/06/26 16:22:47 INFO mapred.Task: Task attempt_local49685846_0001_r_000000_0 is allowed to commit now 95 18/06/26 16:22:47 INFO output.FileOutputCommitter: Saved output of task 'attempt_local49685846_0001_r_000000_0' to hdfs://localhost:9000/output/wordcount/_temporary/0/task_local49685846_0001_r_000000 96 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Records R/W=381/1 > reduce 97 18/06/26 16:22:47 INFO mapred.Task: Task 'attempt_local49685846_0001_r_000000_0' done. 98 18/06/26 16:22:47 INFO mapred.LocalJobRunner: Finishing task: attempt_local49685846_0001_r_000000_0 99 18/06/26 16:22:47 INFO mapred.LocalJobRunner: reduce task executor complete. 100 18/06/26 16:22:48 INFO mapreduce.Job: Job job_local49685846_0001 running in uber mode : false 101 18/06/26 16:22:48 INFO mapreduce.Job: map 100% reduce 100% 102 18/06/26 16:22:48 INFO mapreduce.Job: Job job_local49685846_0001 completed successfully 103 18/06/26 16:22:48 INFO mapreduce.Job: Counters: 35 104 File System Counters 105 FILE: Number of bytes read=279474 106 FILE: Number of bytes written=1220325 107 FILE: Number of read operations=0 108 FILE: Number of large read operations=0 109 FILE: Number of write operations=0 110 HDFS: Number of bytes read=4534 111 HDFS: Number of bytes written=2287 112 HDFS: Number of read operations=13 113 HDFS: Number of large read operations=0 114 HDFS: Number of write operations=4 115 Map-Reduce Framework 116 Map input records=34 117 Map output records=381 118 Map output bytes=3013 119 Map output materialized bytes=3781 120 Input split bytes=85 121 Combine input records=0 122 Combine output records=0 123 Reduce input groups=236 124 Reduce shuffle bytes=3781 125 Reduce input records=381 126 Reduce output records=236 127 Spilled Records=762 128 Shuffled Maps =1 129 Failed Shuffles=0 130 Merged Map outputs=1 131 GC time elapsed (ms)=0 132 Total committed heap usage (bytes)=536870912 133 Shuffle Errors 134 BAD_ID=0 135 CONNECTION=0 136 IO_ERROR=0 137 WRONG_LENGTH=0 138 WRONG_MAP=0 139 WRONG_REDUCE=0 140 File Input Format Counters 141 Bytes Read=2267 142 File Output Format Counters 143 Bytes Written=2287 144 18/06/26 16:22:48 INFO streaming.StreamJob: Output directory: /output/wordcount
查看结果
1 ➜ Documents hdfs dfs -cat /output/wordcount/part-00000 2 # 结果 3 "Even 1 4 "My 1 5 "We 1 6 (16ft) 1 7 11 1 8 16, 1 9 17-member 1 10 25-year-old 1 11 5m 1 12 AFP. 1 13 BBC's 1 14 Bangkok 1 15 But 1 16 Chiang 1 17 Constant 1 18 Deputy 1 19 Desperate 1 20 Head, 1 21 How 1 22 I'm 1 23 Jonathan 1 24 June 1 25 Luang 2 26 Minister 1 27 Myanmar, 1 28 Nang 2 29 Navy 2 30 Non 2 31 October. 1 32 PM 1 33 Post, 1 34 Prawit 1 35 Prime 1 36 Rai 1 37 Rescue 2 38 Royal 1 39 Saturday 2 40 Saturday. 1 41 Thai 1 42 Thailand's 2 43 Tham 2 44 The 6 45 They 2 46 Tuesday 1 47 Tuesday. 2 48 Wongsuwon 1 49 a 8 50 able 1 51 according 2 52 after 2 53 afternoon. 1 54 aged 1 55 alive, 1 56 alive," 1 57 all 1 58 along 1 59 and 6 60 anything 1 61 are 5 62 areas 1 63 as 1 64 at 2 65 attraction 1 66 authorities 1 67 be 1 68 been 2 69 began 1 70 believed 1 71 between 1 72 bicycles 1 73 border 1 74 boys 1 75 boys, 1 76 briefly 1 77 bring 1 78 but 1 79 by 1 80 camping 1 81 can 1 82 case 1 83 cave 9 84 cave, 3 85 cave. 1 86 cave.According 1 87 ceremony 1 88 chamber 1 89 child, 1 90 coach 3 91 completely 1 92 complex, 1 93 correspondent. 1 94 cross 1 95 crying 1 96 day. 1 97 deputy 1 98 dive 1 99 divers 2 100 down. 1 101 drink."The 1 102 drones, 1 103 during 1 104 early 1 105 eat, 1 106 efforts 1 107 efforts, 2 108 enter 1 109 entered 2 110 enters 1 111 equipment 1 112 extensive 1 113 flood 1 114 floods. 1 115 footballers 1 116 footprints 1 117 for 4 118 found 1 119 fresh 1 120 from 2 121 gear, 1 122 get 1 123 group 1 124 group's 1 125 had 2 126 halted 2 127 hampered 1 128 hampering 1 129 has 1 130 have 6 131 he 1 132 here 1 133 holding 1 134 hopes 1 135 if 1 136 in 3 137 inaccessible 1 138 include 1 139 inside 3 140 into 1 141 is 4 142 it 1 143 kilometres 1 144 levels 1 145 lies 1 146 local 1 147 making 1 148 many 1 149 may 1 150 missing. 1 151 must 1 152 navy 1 153 near 1 154 network. 1 155 night 1 156 not 1 157 now," 1 158 of 4 159 officials. 1 160 on 5 161 one 1 162 optimistic 2 163 our 1 164 out 2 165 outside 2 166 parent 1 167 pools 1 168 poor 1 169 prayer 1 170 preparing 1 171 province 1 172 pumping 1 173 rainfall 1 174 rainy 1 175 raising 1 176 re-enter 1 177 relatives 1 178 reported 1 179 reportedly 1 180 rescue 1 181 resumed 1 182 return. 1 183 rising 2 184 runs 2 185 safe 1 186 safety. 1 187 said 3 188 said, 1 189 says 1 190 scene, 1 191 scuba 1 192 search 3 193 search. 1 194 searching 1 195 season, 1 196 seen 1 197 sent 1 198 should 1 199 small 1 200 sports 1 201 started 1 202 still 2 203 stream 2 204 submerged, 1 205 team 3 206 teams 1 207 the 23 208 their 5 209 them 1 210 these 1 211 they 5 212 third 1 213 though 1 214 thought 1 215 through 1 216 to 17 217 tourist 1 218 train 1 219 trapped 1 220 trapped? 1 221 try 1 222 underground. 1 223 underwater 1 224 unit 1 225 up 1 226 use 1 227 visibility 1 228 visitors 1 229 was 2 230 water 2 231 waters 2 232 were 4 233 which 5 234 who 1 235 with 2 236 workers 1 237 you 1 238 young 1
八、思考一: 如何通过Hadoop存储小文件?
1、应用程序自己控制
2、archive
3、Sequence
File / Map
File
4、CombineFileInputFormat***
5、合并小文件,如HBase部分的compact
思考二:当有节点故障时,Hadoop集群是如何继续提供服务的,如何读和写?
思考三:哪些时影响Mapreduce性能的因素?