版权声明:本文为博主原创文章,未经博主允许不得转载。
Kintinuous是Thomas Whelan在National University of Ireland Maynooth读博期间的工作,有四篇相关的论文(RSS RGB-D Workshop 2012,ICRA 2013,IROS 2013,IJRR 2014)。合作作者Michael Kaess来自CMU,是iSAM的作者(Kintinuous的后端优化用到了iSAM)。Thomas Whelan的另一项主要贡献是ElasticFusion,这是他在帝国理工大学Andrew Davison的实验室做博士后期间的工作。Kintinuous和ElasticFusion的区别在于,Kintinuous侧重于大范围(轨迹可以达到几百米)的三维重建,而ElasticFusion侧重于小范围(房间大小)的三维重建。其次,Kintinuous不支持来回扫描同一片区域并做融合,会出现层层叠叠、重复建模的现象,而ElasticFusion解决了这个问题。
Kintinuous基于KinectFusion做出了三点改进:1)KinectFusion只在固定大小的空间做三维重建,而Kintinuous则把TSDF随着相机运动做平移,从而实现大范围的三维重建;2)KinectFusion在求解相机位置姿态时只利用了点云信息(Depth),而Kintinuous综合使用了点云信息和photometric信息(RGB),更加鲁棒;3)Kintinuous用DBoW实现了回环检测,并根据回环的约束优化三维重建。
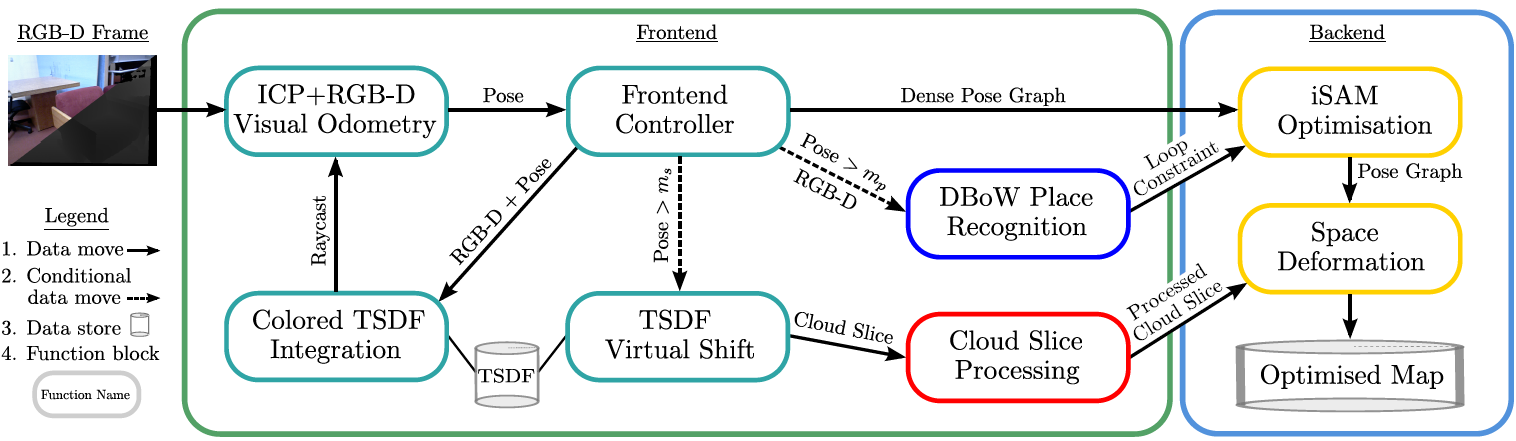
下图展示了Kintinuous的算法流程,它借鉴了PTAM的双线程架构,前端包含四部分内容:1)求解相机的位置姿态;2)TSDF融合,这部分是和KinectFusion一样的;3)如果相机运动超过阈值$m_s$,则平移TSDF,扩大三维重建的范围;4)如果相机运动超过阈值$m_p$,则提取SURF描述子,用DBoW找回环。后端包含两部分内容:1)基于iSAM对pose graph进行优化;2)利用优化后的pose graph,对三维重建进行调整。
1. 相机位置姿态的估计
求解相机位置姿态的cost funcion包含两部分内容:
$$E=E_{icp}+w_{rgbd}E_{rgbd}$$
其中$E_{icp}$对应用ICP处理点云,$E_{rgbd}$对应photometric error,$w_{rgbd}$经验性地被设置为0.1($E_{icp}$单位是米,$E_{rgbd}$是256阶的灰度值)。
$$E_{icp}=sum_k||(v^k-exp(hat{xi})Tv_n^k)cdot n^k||^2$$
其中$v_n^k$表示第$n$帧图片的第$k$个vertex,$v^k$和$n^k$是对应的model上的vertex和normal,$T$是当前估计的相机位置姿态,$hat{xi}$是被估计的微调$T$的量。这部分的处理和KinectFusion一模一样,也是point-to-plane error,对应点之间的关系也是用投影的方式得到的,也是用三层的corse-to-fine的计算策略。
$$E_{rgbd}=sum_{pin{mathscr{L}}}||I_n(p)-I_{n-1}(Pi_{n-1}(exp(hat{xi})TV_n(p)))||^2$$
其中$p$是像素点反投影得到的三维坐标的空间点,$mathscr{L}$是$I_{n-1}$和$I_{n}$两帧图片之间跟踪到的点的集合,$V_n(p)$是把点$p$投影到第$n$帧图片,$Pi$是从homogeneous坐标得到二维的图像坐标。为了计算$E_{rgbd}$,在预处理阶段会先从RGB图像得到灰度图,然后用Gaussian kernel降采样成三层金字塔(KinectFusion是均值降采样)
整个求解相机位置姿态的公式和ElasticFusion几乎一模一样,唯一的区别是,Kintinuous中$E_{icp}$是frame-to-model,$E_{rgbd}$是frame-to-frame,而在ElasticFusion中二者都是frame-to-model。论文[1]中解释photometric error为什么要用frame-to-frame而不是frame-to-model:因为作者发现在室内环境开着自动曝光和自动白平衡效果更好,而一旦曝光和白平衡变化,frame-to-model就不现实了,只能考虑短时间内frame-to-frame的photometric consistency。但这段解释不是很有道理,因为ElasticFusion完全是针对室内环境却没有采用同样的策略。
2. 大范围的TSDF融合
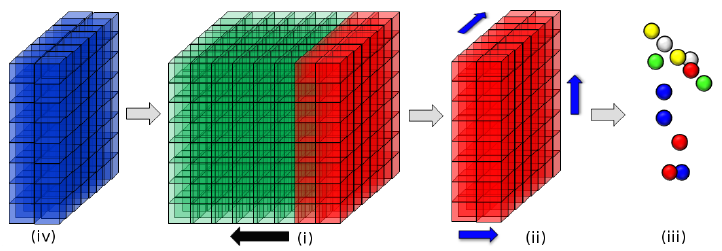
TSDF的概念和融合方式就不再赘述了,可以参考KinectFusion解析。Kintinuous也是把一个立方体空间分割成$512 imes512 imes512$个voxel,每个voxel存储TSDF值(float16)、权重(1 byte)、RGB($1 imes3$ bytes),所以为了维持这么多的voxel需要768MB($512^3 imes6$ bytes)的内存。这里可以看出用voxel描述三维空间的一个非常大的问题:耗内存。所以为了实现大范围的三维重建,没办法过分增加voxel的数量,只能跟着相机的运动平移固定数量的voxel,而一旦voxel移出某个空间,这个空间的三维重建就定型了,没办法继续做融合。这也是为什么Kintinuous不支持来回扫描同一片区域,会重复建模。如下图所示,(i)中的每个小立方体是一个voxel,小立方体组成的大立方体是Kintinuous在GPU上管理的固定数量的voxel,这部分GPU内存被称为“循环缓冲区”(cyclical buffer),当相机沿着黑色箭头运动超过阈值$m_s$的距离,红色部分的voxel移出;(ii)沿三个轴(蓝色箭头)raycast出表面;(iii)展示的是重建出的点云;(iv)蓝色部分是新纳入三维重建的空间,这部分voxel就是红色部分空出来的voxel。
但说实在的,我个人觉得这样的处理方式不是非常好,因为KinectFusion这套基于voxel的描述方式的最大问题在于大量voxel都是没有用的,只有物体表面的区域才需要voxel描述,Kintinuous看起来实现了大范围的三维重建,但是治标不治本,voxel的使用依然非常低效。相比而言,voxel hashing[2]和基于surfel[3]的方法更优雅。另一方面,不支持来回扫描同一片区域实在是个很大的缺点,RGBD相机的优点在于小范围的精细重建,应该做到反复扫描同一区域有更多的观测效果更好。如果单纯为了几百米范围的大规模三维重建,SfM可能是更好的处理方式。
3. 重定位
Kintinuous的重定位方式和ORB-SLAM相似,都是对图片提取描述子,然后用DBoW找回环。差别在于ORB-SLAM用的是ORB描述子,而Kintinuous用的是SURF描述子。如果对每一帧图片都提取描述子,非常耗时而且没有必要。对于当前帧a和最近执行回环检测的那一帧b,Kintinuous经验性地设计了一个评价相对运动大小的量:
$$m_{ab}=||r(R_a^{-1}R_b)||_2+||t_a-t_b||_2$$
其中$r(R)$把旋转矩阵转换为3*1的轴角,Kintinuous只有在$m_{ab}$超过阈值$m_p=0.3$时才会执行回环检测。
回环检测具体分三步:
1)在RGB图提取SURF描述子,存入内存,为之后的查询做准备;
2)把深度图存入内存,为了降低内存使用,会对深度图做压缩;
3)在DBoW库中查询匹配,如果找到匹配则执行回环优化。判断匹配的标准:
-
- 一旦有了候选的两帧匹配图像,用FLANN的k近领域的方法找图像上的匹配SURF特征,经验表明,少于35个就算没匹配上。
- 候选的两个匹配图像,把其中一帧的图像的SURF特征点反投影成三维坐标,然后投影到另一帧,重投影误差小于2像素算内点。至少25%的匹配点是内点,否则舍弃回环。
- 前两步已经筛掉了好多错误的回环匹配。现在继续用ICP再筛一遍。为了加速计算,会对深度图降采样。从两帧深度图得到各自的点云,然后计算点云的差别。小于阈值0.01,则被认为是可以的。
4. Space Deformation
TODO
参考文献:
[1] Whelan T, Kaess M, Johannsson H, et al. Real-time large-scale dense RGB-D SLAM with volumetric fusion[J]. The International Journal of Robotics Research, 2015, 34(4-5): 598-626.
[2] Nießner M, Zollhöfer M, Izadi S, et al. Real-time 3D reconstruction at scale using voxel hashing[J]. ACM Transactions on Graphics (ToG), 2013, 32(6): 169.
[3] Keller M, Lefloch D, Lambers M, et al. Real-time 3d reconstruction in dynamic scenes using point-based fusion[C]//3D Vision-3DV 2013, 2013 International Conference on. IEEE, 2013: 1-8.