Solr简介及安装
简介
Solr
Solr是一个高性能,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
lucene
Lucene是apache jakarta项目的一个子项目,是一个开放源代码的全文检索引擎开发工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
倒排索引
我们一般情况下,先找到文档,再在文档中找出包含的词;
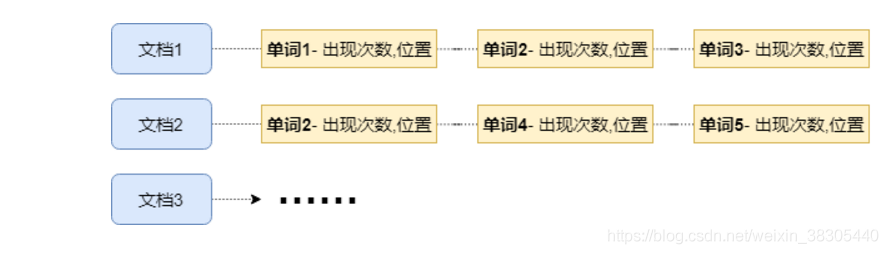
倒排索引则是这个过程反过来,用词,来找出它出现的文档.
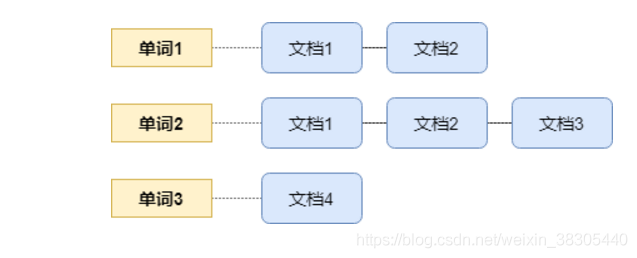
实际举例
| 文档编号 | 文档内容 |
|---|---|
| 1 | 全文检索引擎工具包 |
| 2 | 全文检索引擎的架构 |
| 3 | 查询引擎和索引引擎 |
分词结果
| 文档编号 | 分词结果集 |
|---|---|
| 1 | {全文,检索,引擎,工具,包} |
| 2 | {全文,检索,引擎,的,架构} |
| 3 | {查询,引擎,和,索引,引擎} |
倒排索引
| 编号 | 单词 | 文档编号列表 |
|---|---|---|
| 1 | 全文 | 1,2 |
| 2 | 检索 | 1,2 |
| 3 | 引擎 | 1,2,3 |
| 4 | 工具 | 1 |
| 5 | 包 | 1 |
| 6 | 架构 | 2 |
| 7 | 查询 | 3 |
| 8 | 索引 | 3 |
Centos安装Solr
1. 安装前提
Solr依赖于JDK, 索引要先配置好JDK的环境 [linux配置JDK]
2. 下载
下载地址: https://lucene.apache.org/solr/downloads.html
然后上传到你的服务器, 使用tar -xvf命令解压到/usr/local/目录下
3. 启动Solr
启动后的默认端口是 8938
进入解压后Solr的目录, 然后进入bin目录中
# 启动Solr, 默认端口是8938
/solr start -force
# 开放 8983 端口
firewall-cmd --zone=public --add-port=8983/tcp --permanent
firewall-cmd --reload
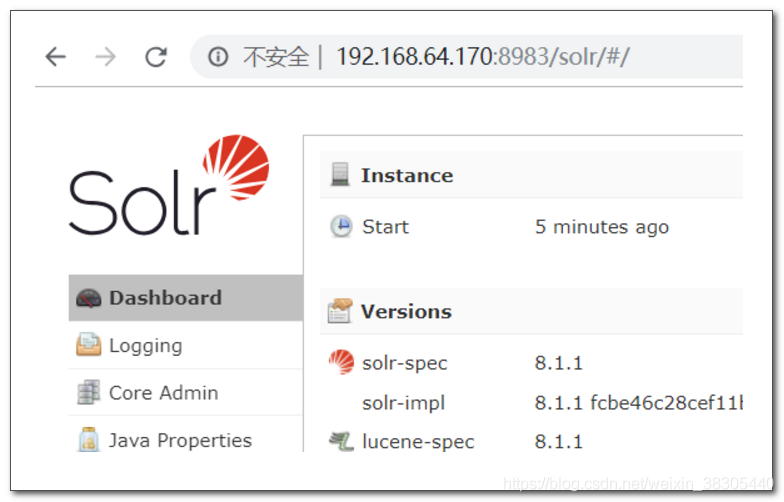
4. 浏览器访问 solr 控制台
http://192.168.64.170:8983 , ip改为你自己服务器的ip
出现如下页面表示成功
lucene API 介绍
我们使用一个测试案例, 来了解一下lucene的API
1. 创建maven项目导入依赖
依赖和构建如下
<dependencies>
<!--lucene 核心API-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.1.1</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--lucene 中文分词器-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>8.1.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
2. 编写代码
package test;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.io.File;
public class Test1 {
String[] a = {
"3, 华为 - 华为电脑, 爆款",
"4, 华为手机, 旗舰",
"5, 联想 - Thinkpad, 商务本",
"6, 联想手机, 自拍神器"
};
@Test
public void test1() throws Exception {
// 文件夹
FSDirectory d = FSDirectory.open(new File("D:/temp/abc/").toPath());
// 配置工具, 配置中文分词器
IndexWriterConfig conf = new IndexWriterConfig(new SmartChineseAnalyzer());
// 索引输出工具
IndexWriter writer = new IndexWriter(d, conf);
// 循环处理四篇文档, 输出索引
for (String s : a) {
// id, 名称, 买点
// 0 1 2
String[] arr = s.split("\s*,\s*");
// 商品的三项数据封装成 Document 对象
Document doc = new Document(); // lucene 包下的Document类
doc.add(new LongPoint("id", Long.parseLong(arr[0])));
doc.add(new StoredField("id", Long.parseLong(arr[0]))); // 存储摘要
doc.add(new TextField("title", arr[1], Field.Store.YES)); // 直接使用Store.YES参数存储摘要
doc.add(new TextField("sellPoint", arr[2], Field.Store.YES));
writer.addDocument(doc); // 添加到输出工具
}
writer.flush(); // 刷出, 存储到指定的文件夹下
writer.close();
}
}
3. 运行
运行后没有任何输出, 然后进入到代码中声明的文件夹中, 可以看到如下文件
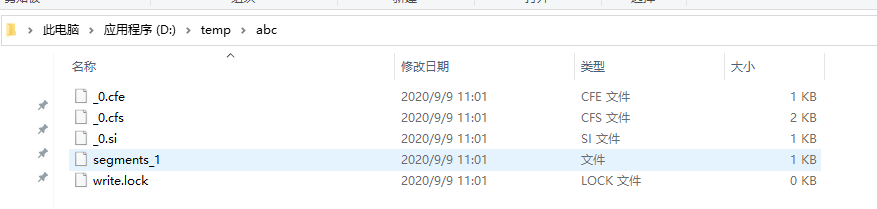
表示执行成功
使用lucene工具查看索引
1. 下载lucene工具
下载地址: https://www.apache.org/dyn/closer.lua/lucene/java/8.6.2/lucene-8.6.2.tgz
然后解压到你的系统中, (windows或桌面版linux)
找到里面的luke文件夹, 然后运行luke.bat (Windows)或luke.sh (Linux)
然后稍等片刻会出现如下界面: 选择自己的索引目录即可, 我的是D:/temp/abc
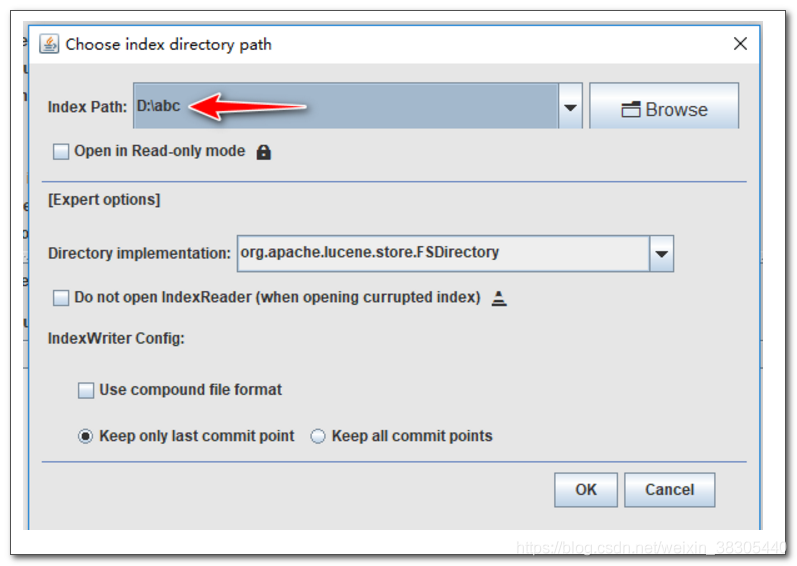
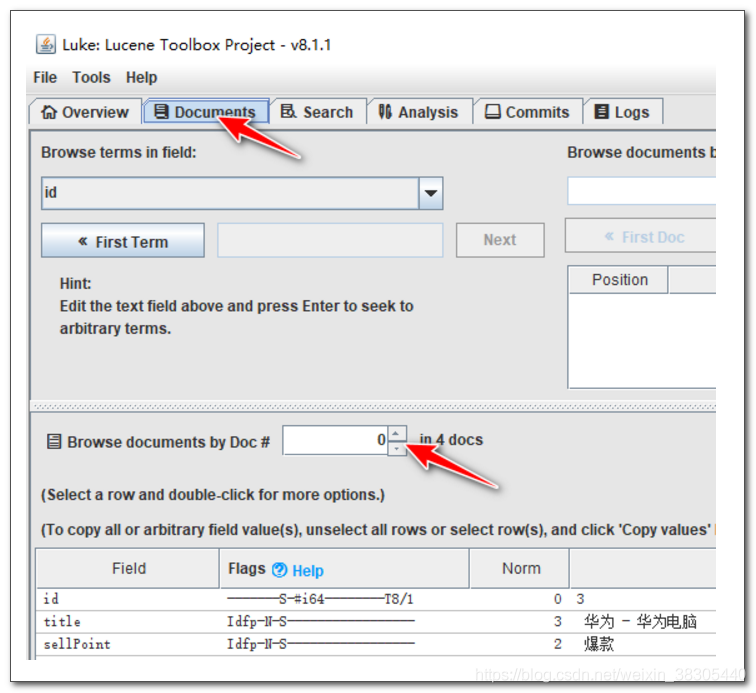
2. 查看文档
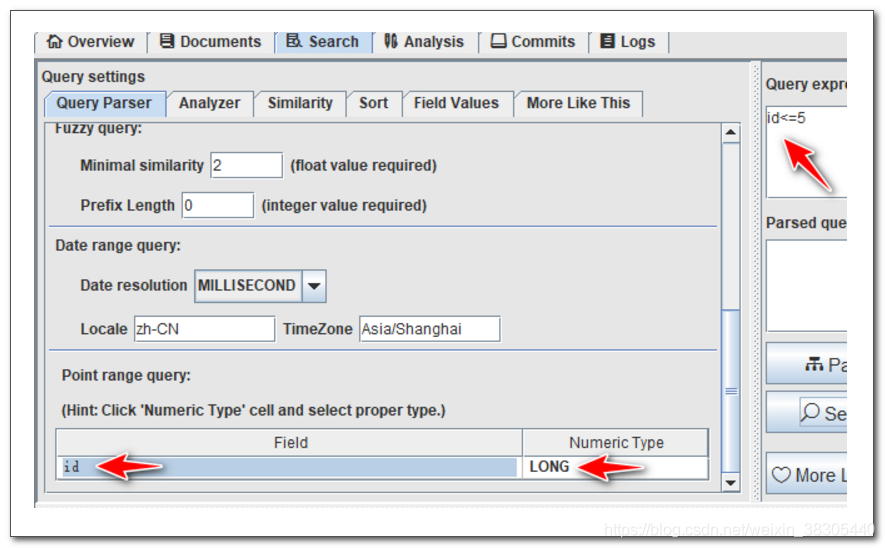
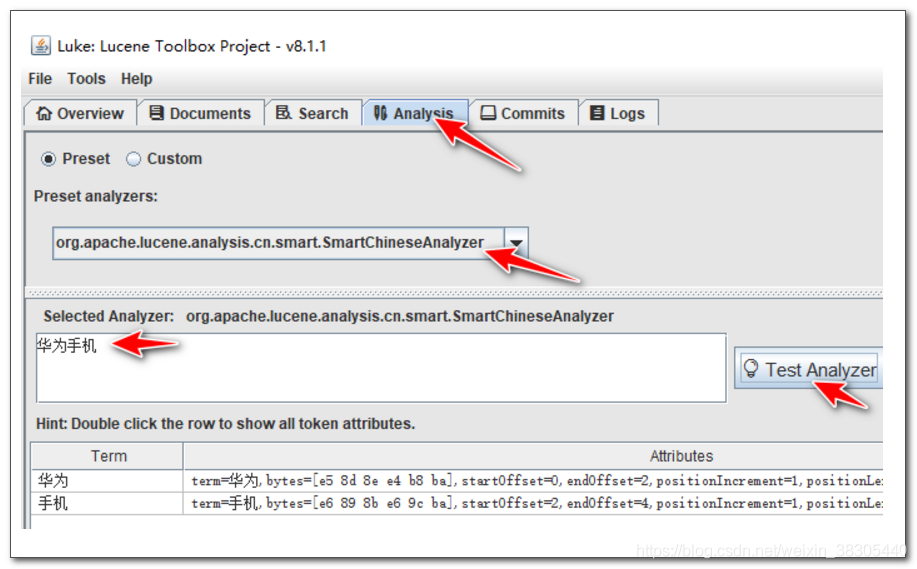
3. 指定分词器,并测试分词
4. 查询测试
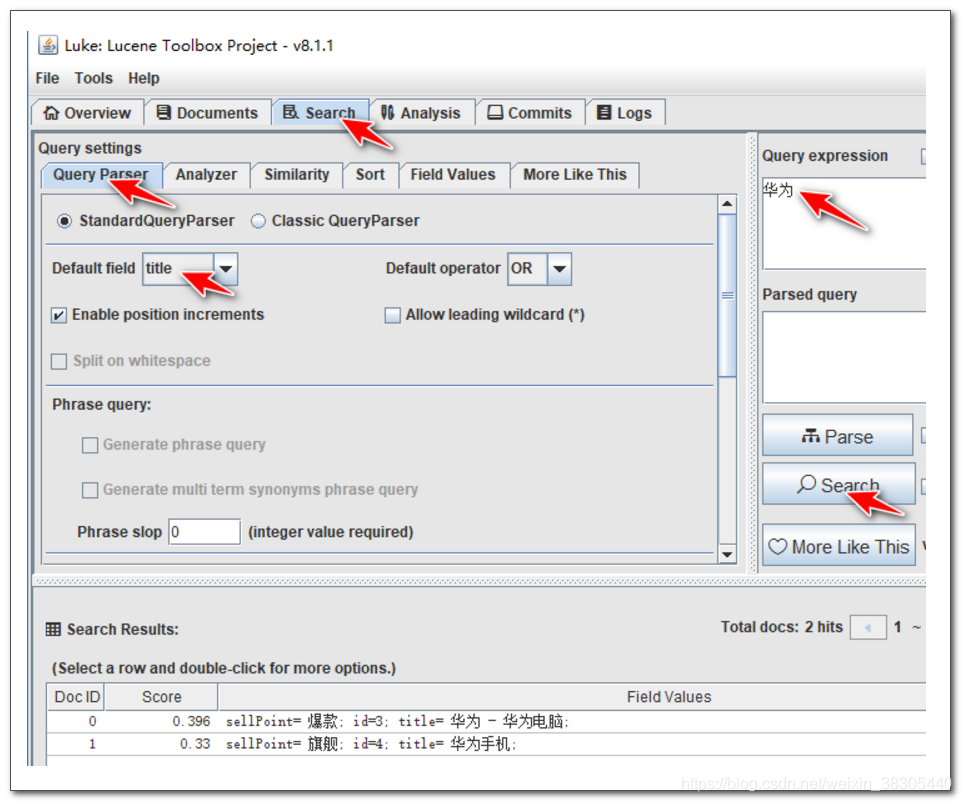
5. id的查询