数据是如何存储的?
JavaScript中的数据类型共8种:
原始类型:Boolean、Null、Undefined、Number、BigInt、String、Symbol
引用类型:Object
JavaScript内存模型:代码空间、栈空间、堆空间
原始数据类型存储在栈空间,引用类型的数据存储在堆空间,在栈空间只是保留了对象的引用地址
通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。
垃圾是如何回收的?
垃圾数据回收分为手动回收和自动回收两种策略。
如 C/C++ 就是使用手动回收策略,何时分配内存、何时销毁内存都是由代码控制的。
// 在堆中分配内存
char* p = (char*)malloc(2048);
// 在堆空间中分配 2048 字节的空间,并将分配后的引用地址保存
// 使用 p 指向的内存
{ //.... }
// 使用结束后,销毁这段内存
free(p);
p = NULL;
另外一种使用的是自动垃圾回收的策略,如 JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。
调用栈中的数据回收机制
当一个函数执行结束之后,JavaScript引擎会通过向下移动ESP来销毁该函数保存在栈中的执行上下文。
堆中的数据回收机制
回收堆中的垃圾数据,需要使用到JavaScript中的垃圾回收器。
垃圾回收的策略都是建立在代际假说的基础之上。
代际假说有以下两个特点:
-
不死的对象,会活的更久。
-
大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问
通常,垃圾回收算法有很多种,但是并没有哪一种能胜任所有的场景,需要权衡各种场景,根据对象的生存周期的不同而使用不同的算法,以便达到最好的效果。
所以,在V8中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的是生存时间久的对象。
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收
副垃圾回收器,主要负责新生代的垃圾回收。
主垃圾回收器,主要负责老生代的垃圾回收。
不论什么类型的垃圾回收器,它们都有一套共同的执行流程
1、标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象是可以进行垃圾回收的对象。
2、回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象
3、做内存整理。(整理内存碎片--频繁回收对象后所产生的大量不连续空间)
注:第三步可选。因为有的垃圾回收器不会产生内存碎片,比如副垃圾回收器。
副垃圾回收器
副垃圾回收器主要负责新生区的垃圾回收。新生代中用Scavenge算法来处理。所谓Scavenge算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。如图所示:

新加入的对象会存放到对象区域,当对象区域快被写满时,执行垃圾清理操作。
在垃圾回收过程中,首先对对象区域的垃圾进行标记,标记后进入垃圾清理阶段,副垃圾回收器将这些存活的对象复制到空闲区域中,同时将这些对象有序地排列起来,因此,这个复制过程,就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
完成复制后,将对象区域与空闲区域进行角色翻转,这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去。同时,为了执行效率,一般新生区的空间会设置的比较小。这样就会造成新生区的空间很容易被存活的对象装满整个区域,为了解决这个问题,JavaScript引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象就会被移动到老生区中。
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。它有两个特点:
- 对象占用空间大
- 对象存活时间长
因此主垃圾回收器是采用标记-清除的算法进行垃圾回收的。
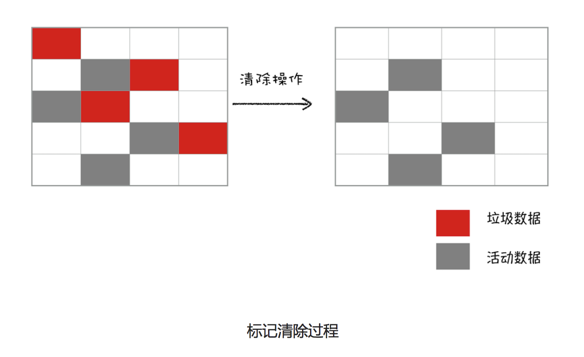
标记-清除
- 标记
首先是标记过程阶段。标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素判断为垃圾数据。
- 清除
它和副垃圾清除过程完全不同,它是将标记为垃圾数据的数据清除掉。
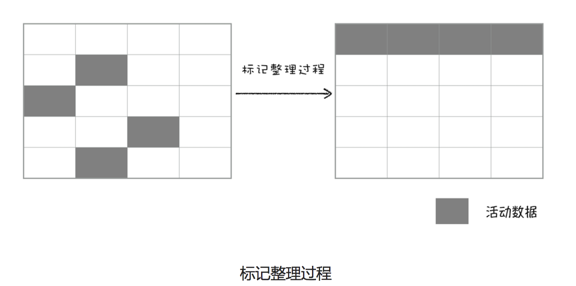
标记-整理
上面的标记过程和清除过程就是标记-清除算法。不过对一块内存多次执行标记-清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,因此有了标记-整理,标记的过程和上面一样,而整理是让所有存活的对象都向一端移动,然后直接清理掉段边界意外的内存。