描述:
在Linux环境下实现高速的全文检索
一、当前环境:
CentOS (Linux) 6.3 64 bit
二、所需软件
1、Java的JDK
Java jdk 1.7.0【注意:solr5.x版本必须安装java 1.7及以上版本】
2、Solr最新稳定版Solr-5.1.0
3、Tomcat最新稳定版Tomcat-7.0.72【也可以进入到solr的安装目录下,执行bin/solr start命令即可启动solr自带的服务器jetty】
4、IK Analyzer最新稳定版分词器IKAnalyzer2012
三、Tomcat安装
1、 安装jdk
yum install java-1.7.0-openjdk
2、 下载Tomcat
http://mirror.bit.edu.cn/apache/tomcat/tomcat-7/v7.0.72/bin/
(如果找不到请到http://mirror.bit.edu.cn/ 官网点击”apache”进入选择相应版本下载)
3、解压tomcat并且放到指定目录下
#tar zxvf apache-tomcat-7.0.72.tar.gz
#mv apache-tomcat-7.0.72/ /usr/local/tomcat
4、删除tomcat下无用的文件,避免安全问题
#cd /usr/local/tomcat/webapps/
#rm -rf *
(如果想测试是否安装成功,那么就新建一个test
目录,在下面放一个index.html文件进行测试)
5、启动tomcat
#/usr/local/tomcat/bin/startup.sh
6、关闭tomcat
#/usr/local/tomcat/bin/shutdown.sh
四、Solr配置
1、 下载Solr
http://mirror.bit.edu.cn/apache/lucene/solr/
2、 解压并且配置Solr
#tar zxvf solr-5.1.0.tgz
a. 将solr-5.1.0/server/webapps/solr.war目录下的solr.war拷贝到tomcat安装目录的webapps下(如:/usr/local/tomcat/webapps/),启动tomcat解压“solr.war”,tomcat会自动解压solr.war;
b. 新建solr索引目录:/home/solr;
c. 把官网下载的solr(本文为:solr-5.1.0.tgz)解压目录中的"solr-5.1.0/server/solr"目录下的所有内容复制到/home/solr中。
3、配置/home/solr
修改tomcat/webapps/solr/WEB-INF/web.xml,,取消注释,配置“env-entry-value”的值为自定义的solr索引目录


1 <env-entry> 2 3 <env-entry-name>solr/home</env-entry-name> 4 5 <env-entry-value>/home/solr</env-entry-value> 6 7 <env-entry-type>java.lang.String</env-entry-type> 8 9 </env-entry>
4、配置日志
将solr目录下server/lib/ext中的jar包copy到tomcat的solr/WEB-INF/lib下。这时候虽然添加jar包,但是没有对应的日志配置,需要将solr-5.1.0/server/resources下的log4j.properties也放到solr/WEB-INF/classes/下,如果没有classes文件夹则新建一个。
5.添加一个核core0
在/home/solr文件夹下:
1)创建core0
mkdir core0
2)复制/home/solr/configsets/basic_configs/conf到core0中
cp -rp ./configsets/basic_configs/conf core0/ 【建议:为缩短目录深度,将basic_configs/conf/*目录直接复制到/hom/solr/conf中】
3)在http://localhost:8080/solr管理页面添加core0
a.第一步:
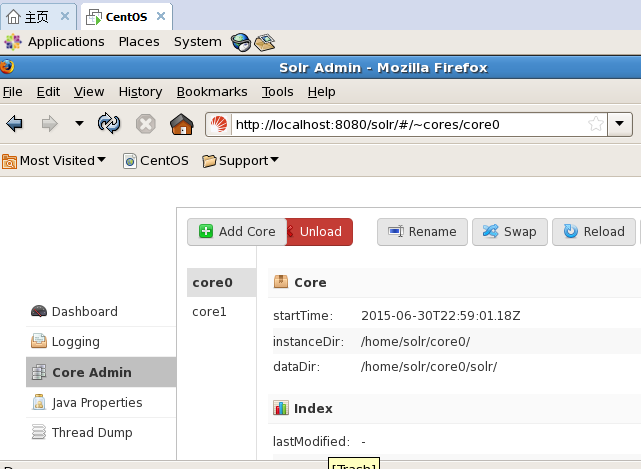
b.第二步:dataDir可以自己命名

6、 重新关闭再开启tomcat
7、浏览器打开 http://localhost:8080/solr
验证是否安装成功。出现solr管理界面的则表示成功!
到这里基本上Solr和Tomcat结合已经完成了,那么下面配置分词。
五、配置IK Analyzer中文分词器
这里说下分词器:
常用的开源分词器有庖丁、MMseg4j,另外还有IKAnalyzer。之前在项目中一直MMseg4j,它有个缺点就是自定义词库的时候比较麻烦。三个中选IK Analyzer是因为它自定义词库简单以及效率非常卓越。
1、 下载分词器
https://code.google.com/p/ik-analyzer/downloads/list
这里选择的是 IKAnalyzer2012_u1.zip (因为比这个版本新的其他的几款在测试的时候都出现问题)
2、 解压并且放置到所需位置
#unzip IKAnalyzer2012_u1.zip
解压之后里面只有三个文件 一个jar 一个stopword.dic还有一个配置文件IKAnalyzer.cfg.xml
a、 将jar放置到tomcat下的solr的WEB-INF下的lib中
#cp IKAnalyzer2012FF_u1.jar /usr/local/tomcat/webapps/solr/WEB-INF/lib/
b、 在tomcat下的solr的WEB-INF下创建一个目录classes
然后将stopword.dic及配置文件IKAnalyzer.cfg.xml
c、 修改Solr中core下的配置文件schema.xml需要指定所需分词的字段,例如:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
这里需要注意的是:这段代码需要在<types></types> 之间添加,还有就是name=”text_ik”指定的类型需要是下面的field中所有的(具体可以搜索下”solr schema.xml”配置详解)
注:在需要使用中文索引的字段上加上type="text_ik"
参考:http://www.cnblogs.com/likehua/archive/2012/12/26/2834650.html
截图:

d、 重启Tomcat并且进行测试
我这里以core0为例子,(在实际生产环境中,每个core都需要修改配置文件进行上述的配置的)

六、自定义词库(添加词、去掉排除词)
在实际生产环境中,可能会需要添加一些特定的行业词,IKAnalyzer的配置文件可以很好的解决这个问题。
1、 添加行业词

打开IKAnalyzer.cfg.xml 然后会看到配置文件写的很清楚,只要安装stopword.dic的格式自定义一个名字,例如xxx.dic 放在当前的同一级目录下,并且在配置文件IKAnalyzer.cfg.xml中指定可以访问到即可了。(这里需要注意的是词库文件编码格式必须为UTF-8无BOM头)
例如我自定义了一个叫:yanglei.dic的,里面写了一个词:杨磊,那么分词结果出来的就完全不一样了
(下面是未配置自定义添加词前的分词结果)

(配置自定义添加词后的分词结果)

2、 添加排除词
这个就简单了,直接编辑stopword.dic 接着之前的排除词添加就可以了
参考:
Solr core配置文件(schema.xml、solrconfig.xml)配置项说明参考网址如下:
http://www.blogjava.net/conans/articles/379545.html
http://www.cnblogs.com/chenying99/archive/2012/04/19/2457195.html
http://www.360doc.com/content/12/1122/10/11098634_249482489.shtml