集群的概念
计算机集群通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。
比如单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给用户,系统处理能力得到大幅度提高。一般分为几种:
- 高可用性集群:一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行。
- 负载均衡集群:负载均衡集群运行时,一般通过一个或者多个前端负载均衡器,将工作负载分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性。
- 高性能计算集群:高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域。
分布式
集群:同一个业务,部署在多个服务器上。分布式:一个业务分拆成多个子业务,或者本身就是不同的业务,部署在不同的服务器上。
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个均衡服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成,并且一台服务器垮了,其它的服务器可以顶上来。分布式的每一个节点,都完成不同的业务,一个节点垮了,那这个业务可能就失败了。
负载均衡
概念
随着业务量的提高,现有网络的各个核心部分访问量和数据流量的快速增长,其处理能力和计算强度也相应地增大,使得单一的服务器设备根本无法承担。在此情况下,如果扔掉现有设备去做大量的硬件升级,这样将造成现有资源的浪费,而且如果再面临下一次业务量的提升时,这又将导致再一次硬件升级的高额成本投入,甚至性能再卓越的设备也不能满足当前业务量增长的需求。
负载均衡技术通过设置虚拟服务器IP(VIP),将后端多台真实服务器的应用资源虚拟成一台高性能的应用服务器,通过负载均衡算法,将用户的请求转发给后台内网服务器,内网服务器将请求的响应返回给负载平衡器,负载平衡器再将响应发送到用户,这样就向互联网用户隐藏了内网结构,阻止了用户直接访问后台(内网)服务器,使得服务器更加安全,可以阻止对核心网络栈和运行在其它端口服务的攻击。并且负载均衡设备(软件或硬件)会持续的对服务器上的应用状态进行检查,并自动对无效的应用服务器进行隔离,实现了一个简单、扩展性强、可靠性高的应用解决方案,解决了单台服务器处理性能不足,扩展性不够,可靠性较低的问题。
服务器负载均衡有三大基本Feature:负载均衡算法,健康检查和会话保持,这三个Feature是保证负载均衡正常工作的基本要素。其他一些功能都是在这三个功能之上的一些深化。
在没有部署负载均衡设备之前,用户直接访问服务器地址(中间或许有在防火墙上将服务器地址映射成别的地址,但本质上还是一对一的访问)。当单台服务器由于性能不足无法处理众多用户的访问时,就要考虑用多台服务器来提供服务,实现的方式就是负载均衡。负载均衡设备的实现原理是把多台服务器的地址映射成一个对外的服务IP(我们通常称之为VIP,关于服务器的映射可以直接将服务器IP映射成VIP地址,也可以将服务器IP:Port映射成VIP:Port,不同的映射方式会采取相应的健康检查,在端口映射时,服务器端口与VIP端口可以不相同),这个过程对用户端是不可见的,用户实际上不知道服务器是做了负载均衡的,因为他们访问的还是一个目的IP,那么用户的访问到达负载均衡设备后,如何把用户的访问分发到合适的服务器就是负载均衡设备要做的工作了,具体来说用到的就是上述的三大Feature。
详细的访问流程分析:
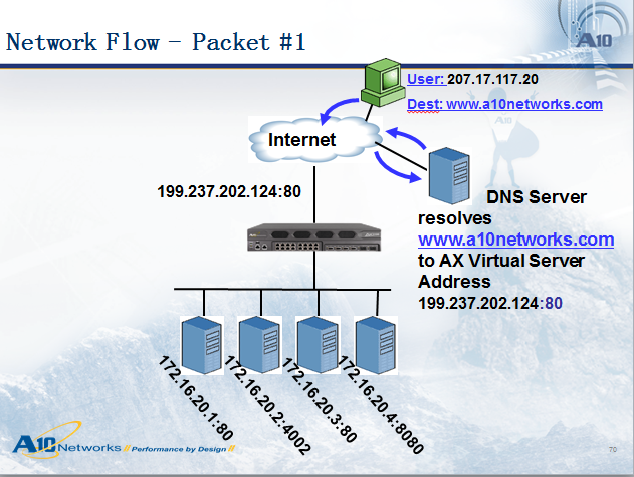
用户(IP:207.17.117.20)访问域名www.a10networks.com,首先会通过DNS查询解析出这个域名的公网地址:199.237.202.124,接下来用户207.17.117.20会访问199.237.202.124这个地址,因此数据包会到达负载均衡设备,接下来负载均衡设备会把数据包分发到合适的服务器,看下图:
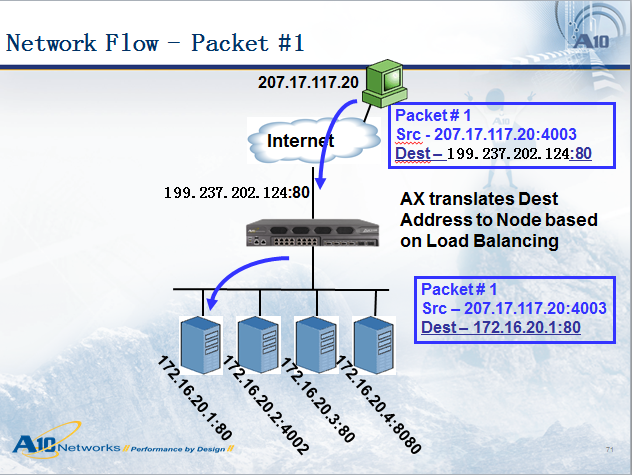
负载均衡设备在将数据包发给服务器时,数据包是做了一些变化的,如上图所示,数据包到达负载均衡设备之前,源地址是:207.17.117.20,目的地址是:199.237.202.124,当负载均衡设备将数据包转发给选中的服务器时,源地址还是:207.17.117.20,目的地址变为172.16.20.1,我们称这种方式为目的地址NAT(DNAT,目的地址转换)。一般来说,在服务器负载均衡中DNAT是一定要做的(还有另一种模式叫做服务器直接返回-DSR,是不做DNAT的,我们将另行讨论),而源地址根据部署模式的不同,有时候也需要转换成别的地址,我们称之为:源地址NAT(SNAT),一般来说,旁路模式需要做SNAT,而串接模式不需要,本示意图为串接模式,所以源地址没做NAT。
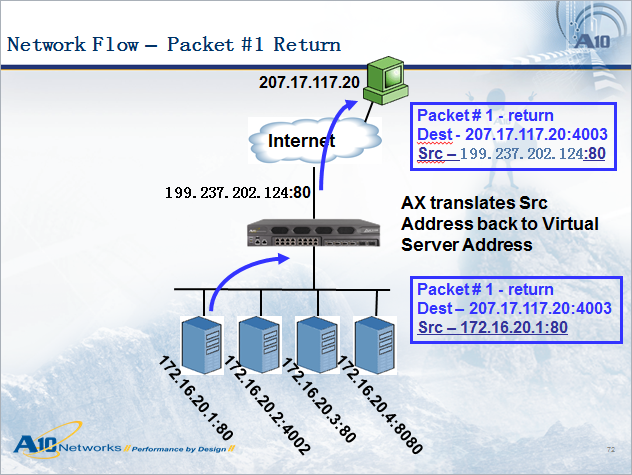
我们再看服务器的返回包,如下图所示,也经过了IP地址的转换过程,不过应答包中源/目的地址与请求包正好对调,从服务器回来的包源地址为172.16.20.1,目的地址为207.17.117.20,到达负载均衡设备后,负载均衡设备将源地址改为199.237.202.124,然后转发给用户,保证了访问的一致性。
负载均衡算法
一般来说负载均衡设备都会默认支持多种负载均衡分发策略,例如:
- 轮询(RoundRobin)将请求顺序循环地发到每个服务器。当其中某个服务器发生故障,AX就把其从顺序循环队列中拿出,不参加下一次的轮询,直到其恢复正常。
- 比率(Ratio):给每个服务器分配一个加权值为比例,根椐这个比例,把用户的请求分配到每个服务器。当其中某个服务器发生故障,AX就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
- 优先权(Priority):给所有服务器分组,给每个组定义优先权,将用户的请求分配给优先级最高的服务器组(在同一组内,采用预先设定的轮询或比率算法,分配用户的请求);当最高优先级中所有服务器或者指定数量的服务器出现故障,AX将把请求送给次优先级的服务器组。这种方式,实际为用户提供一种热备份的方式。
- 最少连接数(LeastConnection):AX会记录当前每台服务器或者服务端口上的连接数,新的连接将传递给连接数最少的服务器。当其中某个服务器发生故障,AX就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
- 最快响应时间(Fast Reponse time):新的连接传递给那些响应最快的服务器。当其中某个服务器发生故障,AX就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
- 哈希算法( hash): 将客户端的源地址,端口进行哈希运算,根据运算的结果转发给一台服务器进行处理,当其中某个服务器发生故障,就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。
- 基于数据包的内容分发:例如判断HTTP的URL,如果URL中带有.jpg的扩展名,就把数据包转发到指定的服务器。
健康检查
健康检查用于检查服务器开放的各种服务的可用状态。负载均衡设备一般会配置各种健康检查方法,例如Ping,TCP,UDP,HTTP,FTP,DNS等。Ping属于第三层的健康检查,用于检查服务器IP的连通性,而TCP/UDP属于第四层的健康检查,用于检查服务端口的UP/DOWN,如果要检查的更准确,就要用到基于7层的健康检查,例如创建一个HTTP健康检查,Get一个页面回来,并且检查页面内容是否包含一个指定的字符串,如果包含,则服务是UP的,如果不包含或者取不回页面,就认为该服务器的Web服务是不可用(DOWN)的。比如,负载均衡设备检查到172.16.20.3这台服务器的80端口是DOWN的,负载均衡设备将不把后面的连接转发到这台服务器,而是根据算法将数据包转发到别的服务器。创建健康检查时可以设定检查的间隔时间和尝试次数,例如设定间隔时间为5秒,尝试次数为3,那么负载均衡设备每隔5秒发起一次健康检查,如果检查失败,则尝试3次,如果3次都检查失败,则把该服务标记为DOWN,然后服务器仍然会每隔5秒对DOWN的服务器进行检查,当某个时刻发现该服务器健康检查又成功了,则把该服务器重新标记为UP。健康检查的间隔时间和尝试次数要根据综合情况来设置,原则是既不会对业务产生影响,又不会对负载均衡设备造成较大负担。
会话保持
如何保证一个用户的两次http请求转发到同一个服务器,这就要求负载均衡设备配置会话保持。
会话保持用于保持会话的连续性和一致性,由于服务器之间很难做到实时同步用户访问信息,这就要求把用户的前后访问会话保持到一台服务器上来处理。举个例子,用户访问一个电子商务网站,如果用户登录时是由第一台服务器来处理的,但用户购买商品的动作却由第二台服务器来处理,第二台服务器由于不知道用户信息,所以本次购买就不会成功。这种情况就需要会话保持,把用户的操作都通过第一台服务器来处理才能成功。当然并不是所有的访问都需要会话保持,例如服务器提供的是静态页面比如网站的新闻频道,各台服务器都有相同的内容,这种访问就不需要会话保持。
绝大多数的负载均衡产品都支持两类基本的会话保持方式:源/目的地址会话保持和cookie会话保持,另外像hash,URL Persist等也是比较常用的方式,但不是所有设备都支持。基于不同的应用要配置不同的会话保持,否则会引起负载的不均衡甚至访问异常。我们主要分析B/S结构的会话保持。
NAT(Network Address Translation,网络地址转换):当在专用网内部的一些主机本来已经分配到了本地IP地址(即仅在本专用网内使用的专用地址),但现在又想和因特网上的主机通信(并不需要加密)时,可使用NAT方法。这种方法需要在专用网连接到因特网的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器,它至少有一个有效的外部全球IP地址。这样,所有使用本地地址的主机在和外界通信时,都要在NAT路由器上将其本地地址转换成全球IP地址,才能和因特网连接。
负载均衡的其他好处
-
高扩展性
通过添加或减少服务器数量,可以更好的应对高并发请求。
-
(服务器)健康检查
负载均衡器可以检查后台服务器应用层的健康状况并从服务器池中移除那些出现故障的服务器,提高可靠性。
-
HTTP缓存
-
入侵阻止功能
链路层(OSI 第二层)负载均衡
在通信协议的数据链路层修改mac地址,进行负载均衡。
数据分发时,不修改ip地址(因为还看不到ip地址),只修改目标mac地址,并且配置所有后端服务器虚拟ip和负载均衡器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。如下图:
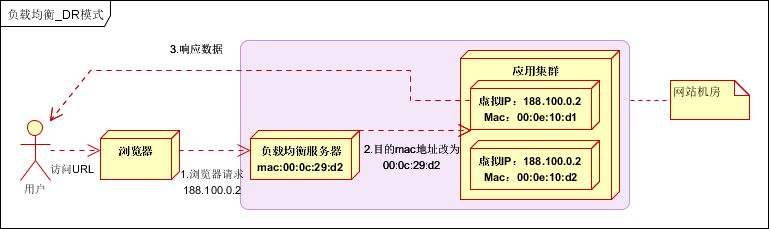
性能很好,但是配置复杂,目前应用比较广泛。
传输层(OSI 第四层)负载均衡
传输层是 OSI 第四层,包括 TCP 和 UDP。流行的传输层负载均衡器有 HAProxy(这个也用于应用层负载均衡)和 IPVS。
主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
以常见的TCP为例,负载均衡设备在接收到第一个来自客户端的SYN 请求时,即通过上述方式选择一个最佳的服务器,并对报文中目标IP地址进行修改(改为后端服务器IP),直接转发给该服务器。TCP的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改。
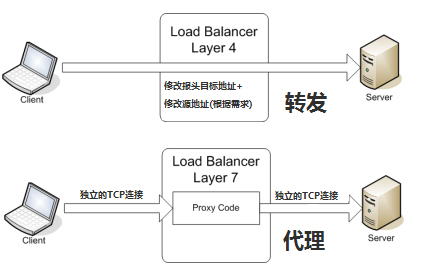
应用层(OSI 第七层)负载均衡
应用层是 OSI 第七层。它包括 HTTP、HTTPS 和 WebSockets。一款非常流行又久经考验的应用层负载均衡器就是 Nginx[恩静埃克斯 = Engine X]。
所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。注意此时可以看到具体的http请求的完整url,因此可以实现下图所示的分发:
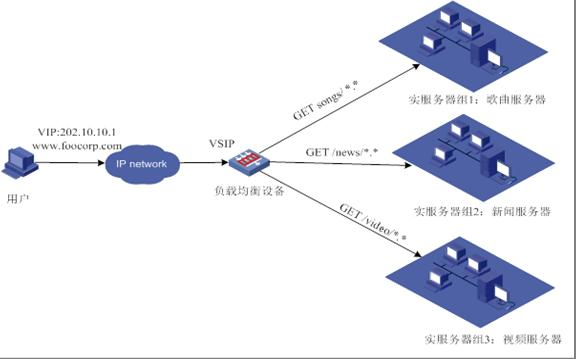
在集群的类型通常有3种:LB:Load Banlancing(负载)、HA:High Availability(高可用)、HP:High Performace(高性能)。LB:负载均衡集群中有一个分发器或者叫调度器,我们将其称之为Director,它处在多台服务器的上面,分发器根据内部锁定义的规则或调度方式从下面的服务器群中选择一个以此来响应客户端发送的请求,从而解决高并发的问题。在扩展中可非常容易的使用scale out扩展,从而实现集群的伸缩性,在业内常见开源解决方案有lvs、haprox、nginx、ats;HA:高可用集群是服务的可用性比较高,当我们某台服务器死机后不会造成我们的服务不可用。其工作模式则是将一个具有故障的服务转交给一个正常工作的服务器,从而达到服务不会中断。一般来说我们集群中工作在前端(分发器)的服务器都会对我们的后端服务器做一个健康检查,如果发现我们服务器当机就不会对其在做转发,衡量标准:可用性=在线时间/(在线时间+故障处理时间),就是通常我们说的可用性99%、99.9%、99.99%等等,在业内常见开源解决方案有heartbeat、keepalived等等;HP:高性能的集群是当某一个任务量非常大的时候,我们做一个集群共同来完成这一个任务。这种处理方式我们称为并行处理集群,并行处理集群是将大任务划分为小任务,分别进行处理的机制,常常用于大数据分析,海量资源整合,目前比较出名的就是Hadoop。
总之,在实际生产环境中我们都可以根据实际情况来挑选合适的集群解决方案,3种集群的侧重各有不同,LB集群着重在于提供服务并发处理能力,HA集群以提升服务在线的能力实现服务不间断,HP集群着重用于处理一个海量任务。