E(elasticsearch,数据库)
L(logstash,收集web日志数据)
K(Kibana,用web的形式展示elasticsearch的数据)
一、1. 安装elasticsearch集群
配置java环境 下载elasticsearch
2. vim /etc/elasticsearch/elasticsearch.yml 文件中 修改(前面的数字代表行数,修改配置文件时 把前面的#删除之后 后面的文字必须定格)
17 cluster.name: myelk //配置集群名字
23 node.name: es1 //当前主机名称
54 network.host: 0.0.0.0 // 0.0.0.0(监听所有地址)
68 discovery.zen.ping.unicast.hosts: ["es1", "es2", "es3"]
//声明集群里的主机成员有谁,不需要全部写进去 但是在启动主机的时候先启动这几台,
启动其他的话其他的会自动组成集群
集群配置完成之后,可以直接访问 http://任意一台:9200/_cluster/health?pretty 查看集群信息
?pretty 这个是把数据竖着显示能更好的 看清信息
3. 插件使用(装在那台上只能在那台机器上使用 ./plugin install file:///插件的绝对路径)
访问这些插件 http://ip:9200/_plugin/插件名
(1)head
展现几区的拓扑结构,通过这个插件可以进行 索引 和 节点 级别的操作
提供一组针对集群的查询API
(2)kopf
elasticsearch的 管理工具
(3)bigbesk
ES集群的监控工具
可以通过他跨查看ES集群的各种状态,如:CPU 、内存
提供对ES集群操作API
插件 head 创建索引
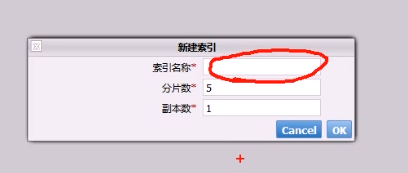
命令行创建索引,插入数据(json 格式)
curl -X PUT "http://192.168.1.55:9200/index" -d '
> {
> "settings":{
> "index":{
> "number_of_shards":5, //分片数
> "number_of_replicas":1 //副本数
> }
> }
> }'
curl -X PUT "http://192.168.1.55:9200/tedu/teacher/1" -d '{
"职业":"诗人",
"名字":"李白",
"称号":"诗仙",
"年代":"唐"}'
tedu是索引名字 teacher为表名 1为id(第一行的意思)
4. 导入数据(导入数据的时候如果里面没有索引,表名在_bulk 前面加上 索引,表名)
curl -X POST "http://ip:9200/_bulk" --data-binary @logs.jsonl(导入的数据必须是json格式的)
二、安装kibana
数据可视化平台工具
vim /opt/kibana/config/kibana.yml

指定集群中的机器任意一台都可以 其他的需要把注释去掉就行
访问地址 http://ip:5601打开之后


全绿说明安装成功
discover 查看数据信息 visualize中可以做饼图
例子访问量排名

三、logstash
安装logstash
1.安装Java环境
2. logstash 没有配置文件需要自己手写
3. 
4.logstash工作结构

(1)数据源(web日志)
(2)input(收集数据)
(3)filter(把数据转换,过滤)
(4)output(把数据输出,给elasticsearch)
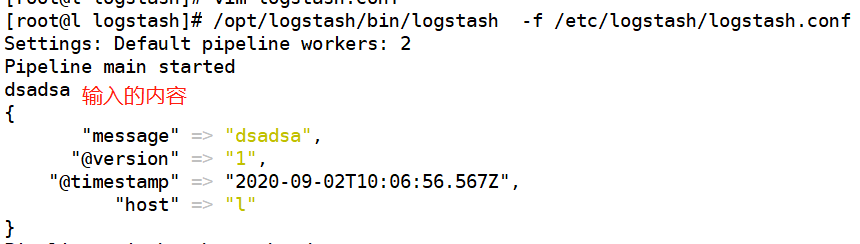
(5)测试

rubydebug输出内容的时候 会竖着显示 比较友好
5.https://github.com/logstash-plugins (logstash的插件地址)
(1)使用input里面的file插件

最后一项是否 必须填写(NO 可以不填)
我们往下拉找 最后一项是yes的


数组中可以填写多个路径

创建 两个log文件 并开启 logstash 程序
logstash 在每次读取文件的时候 都会做一个记录(记录读到日志文件的什么位置)

我们可以自己设置记录文件的位置(生产环境中如果有2个以上的用户维护logstrash,这个记录文件在root下 那么维护起来比较麻烦)

sincedb_path 指定读取记录文件的位置
start_position 有两个参数 beginning 和 end 默认是end,在重启logstash的时候 如果有记录文件那么会从记录文件的位置开始继续读取,如果没有beginning是从文件的开头读取,end是从文件的结尾读取最新的数据(如果是end那么原来的数据会读不到)
type 标签 可以随便写
(2)使用 filter grok插件 我们可以自己编写正则表达式 或者 用宏表达式(自己有的)

正则表达式有匿名分组和命名分组
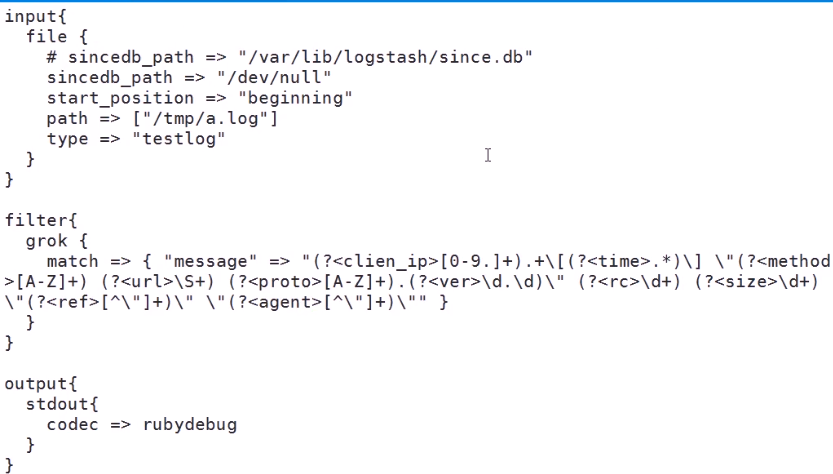
命名正则(?<正则的名字>匹配的内容)固定格式
上面的是手动写的 ,logstash 中有提前准备好的表达式

这个文档里写的是 提前准备好的宏表达式
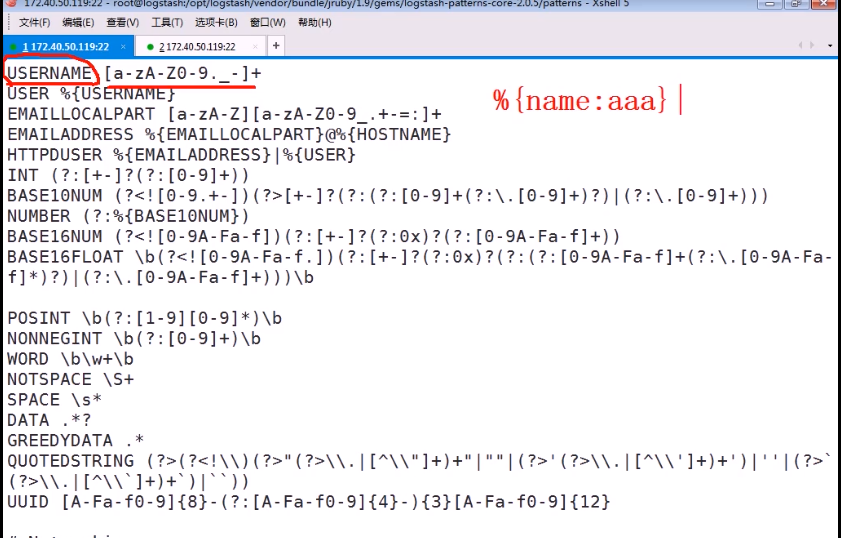
该文档分为两列 第一列为宏的名字 第二列为正则表达式匹配的方法
调用的话%{宏的名字:自己的命名} (也可以不用自己命名 只写宏的名字调用)

直接调用 上面的宏和手写的是一样的
(3)使用putput中的elasticsearch插件
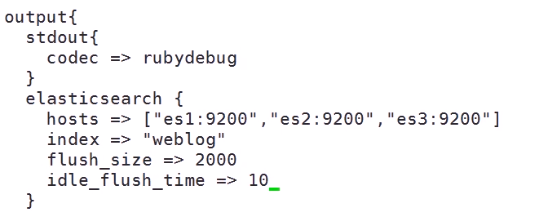
下面 fiush_size是 当大小达到2000字节之后 就像elasticsearch 中写入 数据
idle_flush_time是 10秒 写入一次 防止还没到达2000字节 不向elasticsearch中写入数据
指定 elasticsearch的机器 和 指定创建的库的库名(其实可以不用写 hosts,index(库名) 参数都是默认有参数 hosts 默认的是 127.0.0.1 本机 index默认的是 logshtash-yyy-mmm-ddd 如果elasticsearch和logstash安装在同一台机器那么 hosts 就不用修改)
6. 企业中web服务器多 每台都配置logstash 比较麻烦。 可以用filebeat + logstash,filebeat负责把日志数据传输给logstash中

在logstash配置文件中只需要加上一个端口号,在启动时,logstash会自动检测5044端口
(1)在web服务器安装filebeat
yum -y install filebeat
(2)修改 filebeat的配置文件(/etc/filebeat/filebeat.yaml)
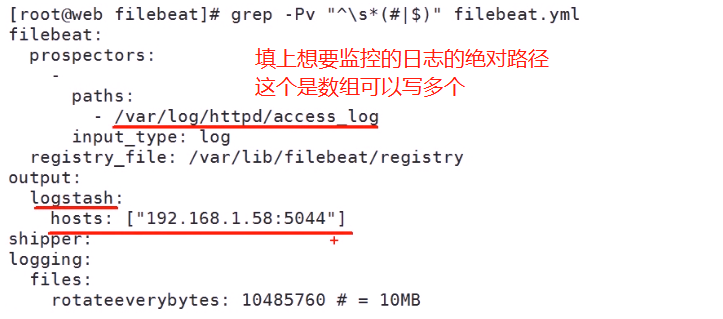
默认的是logstash是注释的 elasticsearch 没有注释 我们把elasticsearch的行给注释了 把logstash的行注释去掉
需要标签(分辨是什么服务的日志)的话可以再 filebeat配置文件中

大约在72行 标记类型
配置完filebeat之后可以在logstash配置文件中 加上 if 判断

四、综合运用
思路
在web服务器中安装 filebeat,filebeat负责把数据传输给logstash,logstash把数据传给elasticsearch,kibana把数据用web方式展现给用户