一、HDFS节点
(一) 添加节点
(1)设置ssh免密登录
(2)修改所有的节点的/etc/hosts
(3)安装java环境
(4)修改NameNode的Slave文件增加该节点
(5)拷贝NameNode节点Hadoop下的文件到新增节点下
(6)启动该节点DateNode
./sbin/hadoop-daemin.sh start datenode
(7)数据恢复(在执行上面的命令之后新增加的设备是没有数据的进行数据恢复)

(二)删除节点
再删除节点的时候 必须要把数据迁移到其他机器上
在删除前 先配置 Hadoop的核心文件
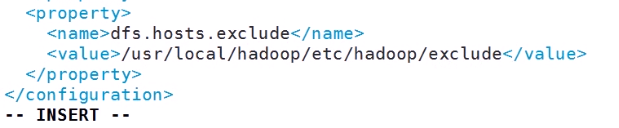
加上上面的参数,清除主机 路径下的exclude文件是不存在的创建这个文件 并且把需要删除的主机名称写入,一行一个主机名
查看状态

这个是正常的状态
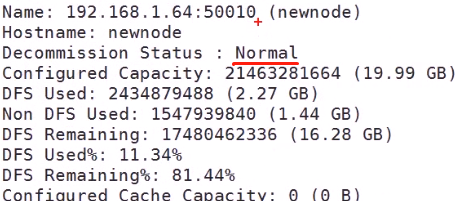
删除之前 刷新数据节点

执行之后在后台会有数据迁移
这个状态是 数据正在进行迁移

迁移之后的状态
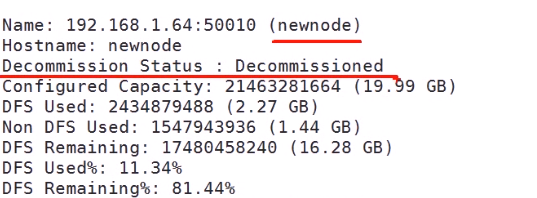
删除节点
直接关机 或者把服务关闭
二、Yran节点
(一)增加/删除节点
只需要把原来节点下Hadoop的配置文件 复制到新增节点 启动就可以了(1.ssh 2.hosts 3.jdk 都需要配置)
增加
./sbin/yarn-daemon.sh start nodemanager
删除
./sbin/yarn-daemon.sh stop nodemanager
查看节点
./bin/yarn node -list