备份和还原,为什么elasticsearch还需要备份呢,明明可以设置副本做到高可用,那怕啥呢?
其实在实际的生产环境中,一般最终的结果数据都是要备份的,这样的做的目的,就是能够以最快的速度还原数据,找回数据。明明mysql可以有主从,es有副本,备份干啥呢?不就是为了万无一失吗,生产环境有时候压力会很大,像mysql频繁的插入和删除数据也会导致binlog日志同步延迟,有时候就不一定能够做到同步,还有就是误操作删除了一些有用的数据呢,对吧,这个叫做有备无患。es也同样,万一一波操作猛如虎,一把把某个索引删除了呢,没有备份,到时候怎么死的都不知道呢,所以呢,从集群的角度去思考,权限,数据备份,高可用,节点拓展等都很重要。elasticsearch备份数据有很多选择,本地呀,Amazon S3, HDFS, Microsoft Azure, Google Cloud Storage这些都可以,但是我这里选择了hdfs,因为做大数据的熟悉呀,还有就是hdfs就是一个分布式的存储系统,也是数据高可用的呀,只要集群不椡,我数据依然完整,所以一点都不方了,所以这篇文章是基于HDFS的Elasticsearch的数据备份和还原。
一、了解下
如何存储:可以存储在本地,或者远程的存储库:Amazon S3, HDFS, Microsoft Azure, Google Cloud Storage等
操作步骤:第一步:需要注册快照存储库,第二步:才能进行创建快照
快照原则:快照属于增量快照,每个快照只存储上一个快照没有的数据,但是都可以通过制定参数进行制定索引进行快照备份
恢复原则:默认恢复全部, 也可以根据需求指定恢复自己需要的索引或者数据流,可以指定索引就行单独还原
注意点:可以使用快照的生命周期来自动的创建和管理快照,备份的时候不能直接通过复制数据进行备份,因为复制的过程中es可能会改变数据的内容,会导致数据不一致的问题
具体的备份和还原细节就交给下文了,看下版本是否支持,如果不支持通过备份还原迁移数据的,可以使用_reindex做跨集群的数据迁移:elasticsearch跨集群数据迁移

二、hdfs插件安装
本地安装hdfs的插件(每一个es节点都需要安装):
下载:https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-7.8.1.zip
安装文档:https://www.elastic.co/guide/en/elasticsearch/plugins/7.9/plugin-management-custom-url.html #7.9的文档不影响哈
具体执行:./bin/elasticsearch-plugin install file:///data/hd07/car/repository-hdfs-7.8.1.zip #这里不要忘记加file:///
然后需要重启ES的集群

cd elasticsearch-7.8.1/plugins && ll

一看,没毛病,一个hdfs插件就这么装好了,接下来我们在hdfs上创建用来存储elasticsearch备份的文件目录(注:这里我们的hadoop是3.x的,chh6.3.2的,虽然官方说是hadoop2.7(2.x),好像也没什么影响)
hadoop fs -mkdir /es_bak hadoop fs -chmod 777 /es_bak #这里我就简单了,免得其他用户没权限写
这里我们就完成了hdfs的设置了,接下来就是elasticsearch的备份和还原操作了
三、备份和还原
3.1、备份
elasticsearch的备份分为两步,第一步:需要注册快照存储库,第二步:才能进行创建快照
3.1.1、注册快照存储库
快照存储库可以包含同一个集群的多个快照。快照是通过集群中的唯一名称标识的,接下来我们就看看基于hdfs的快照存储库的创建:
put _snapshot/my_snapshot { "type": "hdfs", "settings": { "uri": "hdfs://ip:8020/", "path": "/es_bak", "conf.dfs.client.read.shortcircuit": "true", #其实这个参数是hdfs的一个dfs.client.read.shortcircuit,用来做节点移动计算,而不是移动数据的理念,数据本地化 "conf.dfs.domain.socket.path": "/var/run/hdfs-sockets/dn" #配置了上面那个参数,如果hdfs集群没这参数dfs.domain.socket.path就会报错 } }
其实CDH版本的hadoop的HDFS默认这两个都是配置了的

所以上面的两个参数是可以不配置的,因为主机HDFS默认都有配置了的呢
现在我们查看下我们创建好了的快照存储库:
get _snapshot/
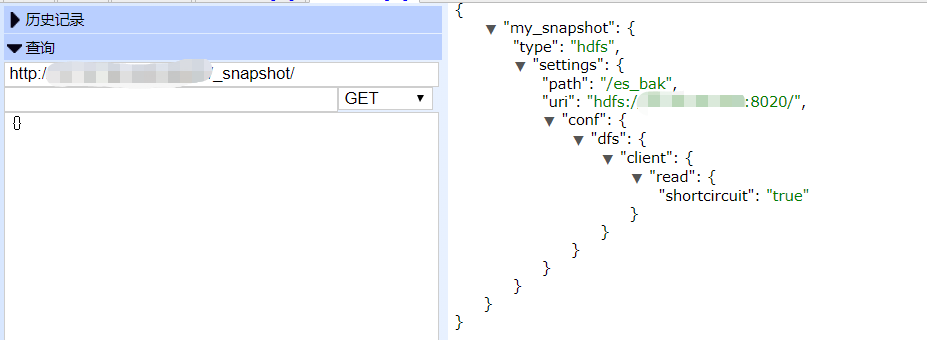
有图有证据,这个快照存储库就创建好了,接下来我们看看创建快照存储库的时候参数设置:
uri #hdfs的地址hdfs://<host>:<port> #这里需要注意一点,一般公司的hadoop都是高可用集群,这里要配置高可用的地址,不能写死了 path #快照需要存储在hdfs上的目录/es_bak (必填) conf.<key> #这个是用来添加hadoop的一些配置的,比如上面例子"conf.dfs.client.read.shortcircuit": "true" load_defaults #是否加载hadoop的配置,默认加载 compress #是否压缩元数据,默认false max_restore_bytes_per_sec #每个节点的恢复速率。默认为无限 max_snapshot_bytes_per_sec #每个节点快照速率。默认值为每秒40mb readonly #设置快照存储库为只读,默认false chunk_size #覆盖块大小,默认disabled security.principal #连接到安全的HDFS集群时使用的Kerberos主体
这部分就说到这里了,这个是官方文档:https://www.elastic.co/guide/en/elasticsearch/plugins/7.9/repository-hdfs-config.html
3.1.2、创建快照
官方网址:https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshots-take-snapshot.html
使用格式:
PUT /_snapshot/<repository>/<snapshot>
POST /_snapshot/<repository>/<snapshot>
快照创建细节:
- 默认情况下,快照包括群集中的所有数据流和打开的索引,以及群集状态。可以通过指定要备份在快照请求正文中的数据流和索引列表来更改
- 快照是增量的快照备份。在创建快照的过程中,Elasticsearch将分析存储库中已经存储的数据流和索引文件的列表,并仅复制自上次快照以来创建或更改的文件。这个过程允许多个快照以紧凑的形式保存在存储库中。
- 快照进程以非阻塞方式执行。所有索引和搜索操作都可以继续针对快照中的数据流或索引运行。但是,快照表示创建快照时的时间点视图,因此在快照进程启动后添加到数据流或索引的记录不会包含在快照中
- 对于已经启动且目前没有重新定位的主分片,快照进程将立即启动。Elasticsearch在快照之前等待分片的重新定位或初始化完成
- 除了创建每个数据流和索引的副本外,快照过程还可以存储全局集群元数据,其中包括持久的集群设置和模板。暂态设置和注册快照存储库不作为快照的一部分存储
先来个例子:
PUT /_snapshot/my_snapshot/snapshot_1?wait_for_completion=true { "indices": "index_name_word", "ignore_unavailable": true, "include_global_state": false, "metadata": { "taken_by": "lgh", "taken_because": "backup test" } }
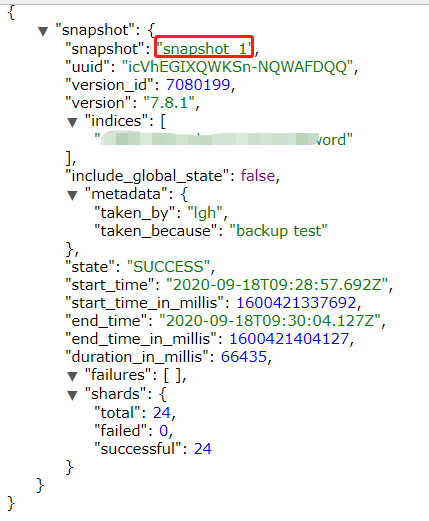
然后我们看看hdfs上面:
hadoop fs -ls /es_bak

hadoop fs -ls /es_bak/indices

单独的索引算是备份完成了,接下来我们看看参数:
ignore_unavailable #默认false,表示对于任何的请求丢失或关闭的数据流或索引,返回一个错误 indices #默认情况下,快照包括集群中的所有数据流和索引,要来设置需要备份的索引,多个之间用逗号(,)分隔,支持正则est* or *test or te*t or *test*或者使用(-)减号排除-test3 include_global_state #快照中包含当前集群状态。默认值为true,主要包括这些元数据:Persistent cluster settings,Index templates,Legacy index templates,Ingest pipelines,ILM lifecycle policies master_timeout #指定等待连接到主节点的时间。如果在超时到期前没有收到响应,则请求失败并返回错误。默认为30秒 metadata #可添加一些备注信息,如上个例子所示 partial #默认false,表示如果快照中包含的一个或多个索引没有所有的主分片可用,则整个快照将失败 wait_for_completion #默认false,请求在快照初始化时返回响应,否则要等待完成才返回
官网还提供了根据时间后缀来创建快照名:

但是实验了一下,失败了:

不过稍微修改下就好了:
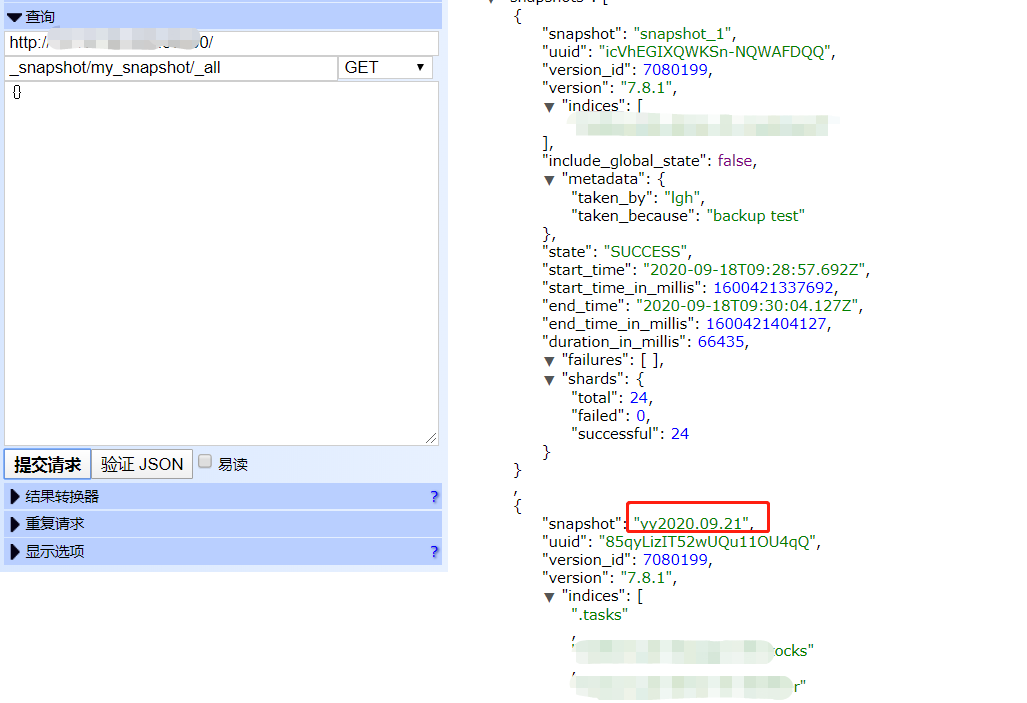
put _snapshot/my_snapshot/<yy{now{yyyy.MM.dd}}> #参考https://www.elastic.co/guide/en/elasticsearch/reference/current/date-math-index-names.html
get _snapshot/my_snapshot/_all
3.2、还原
官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshots-restore-snapshot.html
还原语法:POST /_snapshot/my_backup/snapshot_1/_restore
默认情况下,快照中的所有数据流和索引都将恢复,但不会恢复集群状态。不过可以使用indices参数指定索引进行还原恢复。
注意1:每个数据流都需要一个匹配的索引模板。使用此模板创建新的索引。如果不存在可以创建一个匹配的索引模板,或者恢复集群的元数据。不然的话,数据流不能滚动的创建新的索引
注意2:恢复索引时,如果索引名存在是不会被还原的,除非该索引被关闭了,还要保证分片数相同,才会进行还原,还原的过程中会自动打开已经关闭的索引,如果索引不存在则会创建新的索引
看下具体的参数:
ignore_unavailable #默认false,表示对于任何的请求丢失或关闭的数据流或索引,返回一个错误 ignore_index_settings #一个逗号分隔的索引设置列表,忽略不需要恢复的索引 include_aliases #默认true,恢复时是否恢复别名 include_global_state #是否恢复集群的状态,元数据信息,默认false index_settings #设置索引设置,可以用来覆盖原索引的索引配置 indices ##默认情况下,快照包括集群中的所有数据流和索引,要来设置需要还原的索引,多个之间用逗号(,)分隔,支持正则est* or *test or te*t or *test*或者使用(-)减号排除-test3 partial ##默认false,表示如果快照中包含的一个或多个索引没有所有的主分片可用,则整个快照将失败 rename_pattern #定义用于恢复数据流和索引的重命名模式。与重命名模式匹配的数据流和索引将根据rename_replacement进行重命名。可使用正则 rename_replacement #定义重命名替换字符串 wait_for_completion #默认false,请求在快照初始化时返回响应,否则要等待完成才返回
实例一(没有试验,官方实例):
POST /_snapshot/my_backup/snapshot_1/_restore { "indices": "data_stream_1,index_1,index_2", "ignore_unavailable": true, "include_global_state": false, "rename_pattern": "index_(.+)", "rename_replacement": "restored_index_$1", "include_aliases": false }
实例二(没有试验,官方实例):
POST /_snapshot/my_backup/snapshot_1/_restore { "indices": "index_1", "ignore_unavailable": true, "index_settings": { #修改索引配置 "index.number_of_replicas": 0 }, "ignore_index_settings": [ #忽略的索引 "index.refresh_interval" ] }
3.3、查看和删除
使用_current参数检索集群中当前运行的所有快照
GET /_snapshot/my_backup/_current
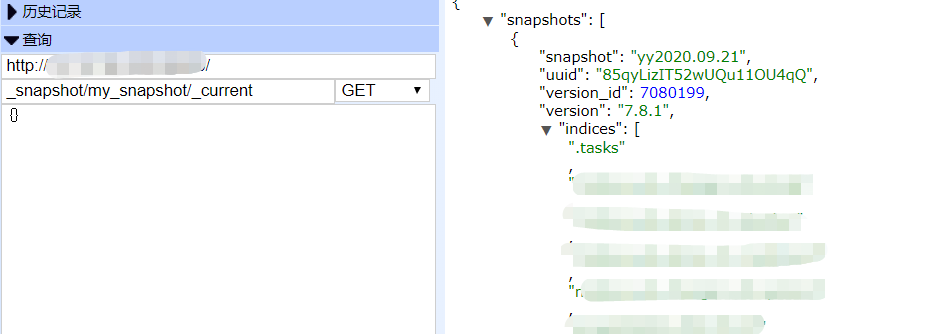
检索关于单个快照的信息
GET /_snapshot/my_backup/snapshot_1
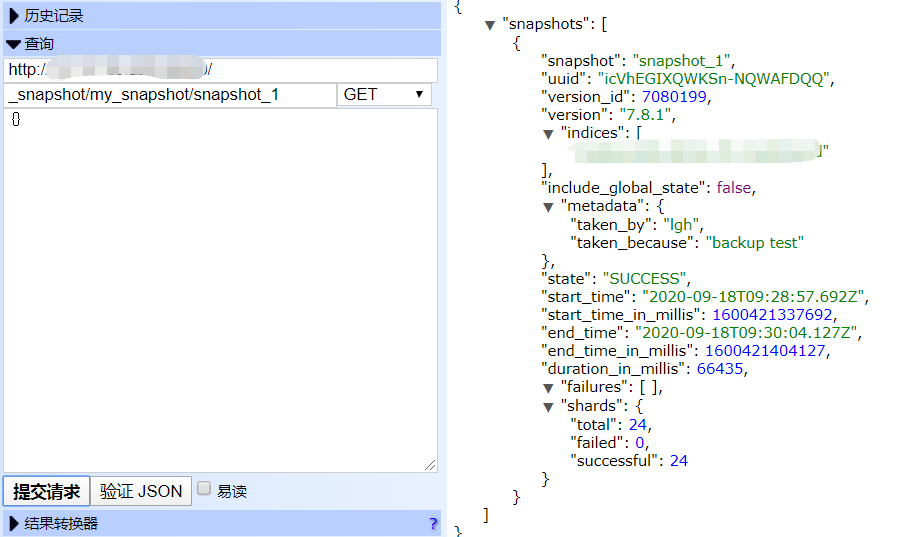
如上可以检索多个快照,可以使用逗号隔开,或者使用*这样的通配符以及_all表示所有,例如:
GET /_snapshot/my_backup/snapshot_*,some_other_snapshot GET /_snapshot/_all GET /_snapshot/my_backup,my_fs_backup GET /_snapshot/my* GET /_snapshot/my_backup/_all
对快照存储库和快照的状态通过_status查看:
GET /_snapshot/_status GET /_snapshot/my_backup/_status GET /_snapshot/my_backup/snapshot_1/_status
详情见:https://www.elastic.co/guide/en/elasticsearch/reference/current/get-snapshot-status-api.html
删除快照:
DELETE /_snapshot/my_backup/snapshot_1
3.4、定时备份
一种是通过crontab定时备份(这里不说,很简单),还有一种是通过Elasticsearch的SLM策略进行定时备份。
我们都知道备份这种事情呢不是单单去备份一次,也不能每次都去手动备份,所以es的备份提供类似crontab一样的时间调度。可以设置快照生命周期策略来自动化快照的计时、频率和保留。快照策略可以应用于多个数据流和索引。
使用SLM策略自动化Elasticsearch数据流和索引的日常备份。该策略获取集群中所有数据流和索引的快照,并将它们存储在本地存储库中。它还定义了一个保留策略,并在不再需要快照时自动删除快照。
要使用SLM,您必须配置一个快照存储库。存储库可以是本地(共享文件系统)或远程(云存储)。远程存储库可以驻留在S3、HDFS、Azure、谷歌云存储或存储库插件支持的任何其他平台上
所以有两个步骤:第一步,创建快照存储库,第二步:创建SLM策略
第一步:创建快照存储库(查看3.1.1、注册快照存储库)
第二步:创建SLM策略
官方实例:
PUT /_slm/policy/nightly-snapshots { "schedule": "0 30 1 * * ?", #配置定时调度,参考https://www.elastic.co/guide/en/elasticsearch/reference/current/trigger-schedule.html#schedule-cron "name": "<nightly-snap-{now/d}>", #配置快照名字,可以通过时间为后缀名 "repository": "my_repository", #快照存储库名 "config": { #用于快照请求的配置,可以从创建快照中的参数配置 "indices": ["*"] #比如对某些索引进行快照 }, "retention": { #保留策略:将快照保存30天,无论快照的年龄如何,至少保留5个且不超过50个快照 "expire_after": "30d", "min_count": 5, "max_count": 50 } }
实验:
put _slm/policy/nightly-snapshots { "schedule": "0 30 1 * * ?", "name": "<lgh-{now{yyyy.MM.dd}}>", "repository": "my_snapshot", "config": { "indices": ["*"] }, "retention": { "expire_after": "30d", "min_count": 5, "max_count": 50 } }

POST /_slm/policy/nightly-snapshots/_execute #手动执行快照策略

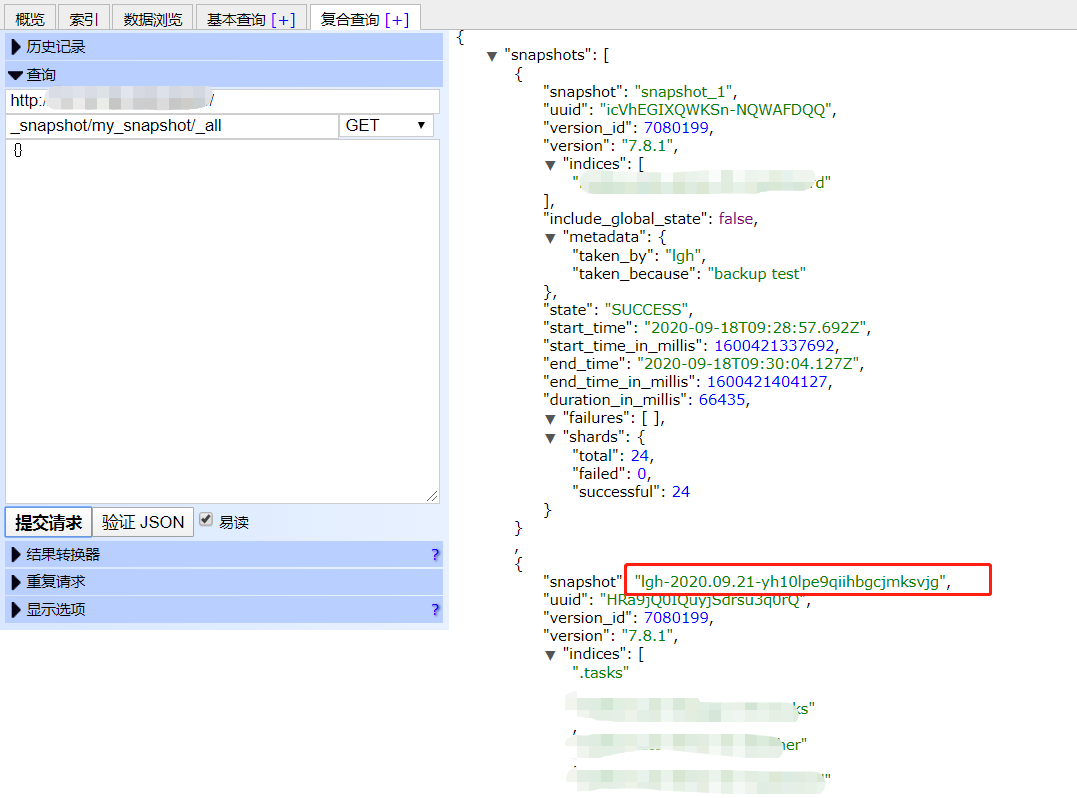
get _snapshot/my_snapshot/_all #查看创建的快照信息
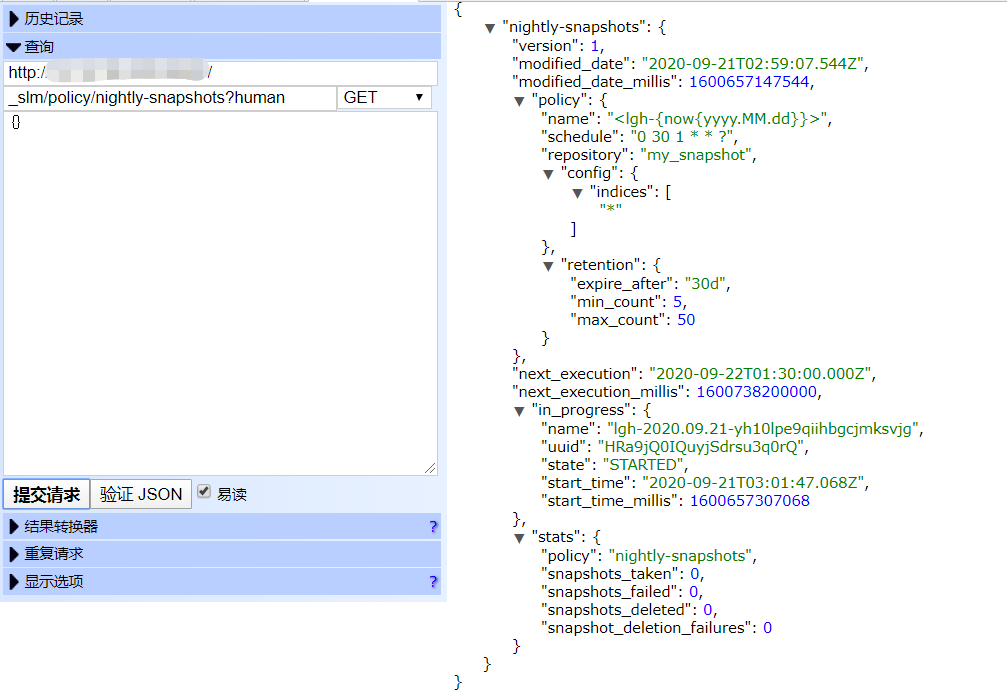
GET /_slm/policy/nightly-snapshots?human #检索策略以获取成功或失败信息
本篇文章差不多结束了,还有要拓展的最好去官网看看,比如要进行SML安全相关的:https://www.elastic.co/guide/en/elasticsearch/reference/current/slm-and-security.html