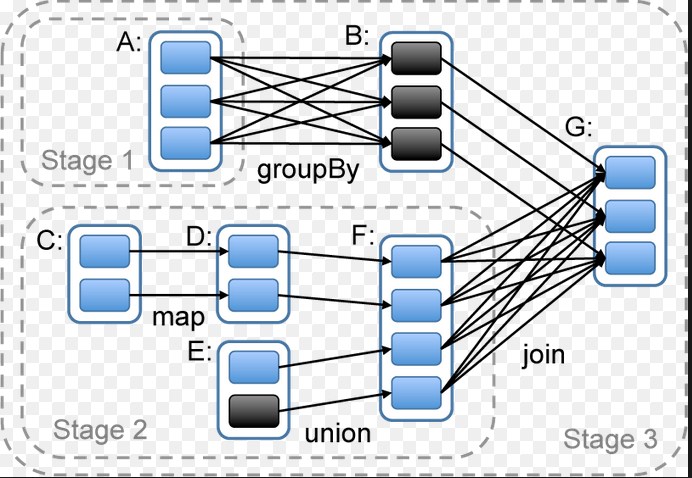
Stage 是一组独立的任务,他们在一个job中执行相同的功能(function),功能的划分是以shuffle为边界的。DAG调度器以拓扑顺序执行同一个Stage中的task。
/**
* A stage is a set of independent tasks all computing the same function that need to run as part
* of a Spark job, where all the tasks have the same shuffle dependencies. Each DAG of tasks run
* by the scheduler is split up into stages at the boundaries where shuffle occurs, and then the
* DAGScheduler runs these stages in topological order.
*
* Each Stage can either be a shuffle map stage, in which case its tasks' results are input for
* another stage, or a result stage, in which case its tasks directly compute the action that
* initiated a job (e.g. count(), save(), etc). For shuffle map stages, we also track the nodes
* that each output partition is on.
*
* Each Stage also has a jobId, identifying the job that first submitted the stage. When FIFO
* scheduling is used, this allows Stages from earlier jobs to be computed first or recovered
* faster on failure.
*
* The callSite provides a location in user code which relates to the stage. For a shuffle map
* stage, the callSite gives the user code that created the RDD being shuffled. For a result
* stage, the callSite gives the user code that executes the associated action (e.g. count()).
*
* A single stage can consist of multiple attempts. In that case, the latestInfo field will
* be updated for each attempt.
*
*/
private[spark] class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int,
val shuffleDep: Option[ShuffleDependency[_, _, _]], // Output shuffle if stage is a map stage
val parents: List[Stage],
val jobId: Int,
val callSite: CallSite)
extends Logging {
重要属性:
val isShuffleMap = shuffleDep.isDefined
val numPartitions = rdd.partitions.size
val outputLocs = Array.fill[List[MapStatus]](numPartitions)(Nil)
var numAvailableOutputs = 0
/** Set of jobs that this stage belongs to. */
val jobIds = new HashSet[Int]
/** For stages that are the final (consists of only ResultTasks), link to the ActiveJob. */
var resultOfJob: Option[ActiveJob] = None
var pendingTasks = new HashSet[Task[_]]
def addOutputLoc(partition: Int, status: MapStatus) {
/**
* Result returned by a ShuffleMapTask to a scheduler. Includes the block manager address that the
* task ran on as well as the sizes of outputs for each reducer, for passing on to the reduce tasks.
* The map output sizes are compressed using MapOutputTracker.compressSize.
*/
private[spark] class MapStatus(var location: BlockManagerId, var compressedSizes: Array[Byte])