论文:
RNNT:SPEECH RECOGNITION WITH DEEP RECURRENT NEURAL NETWORKS,2013
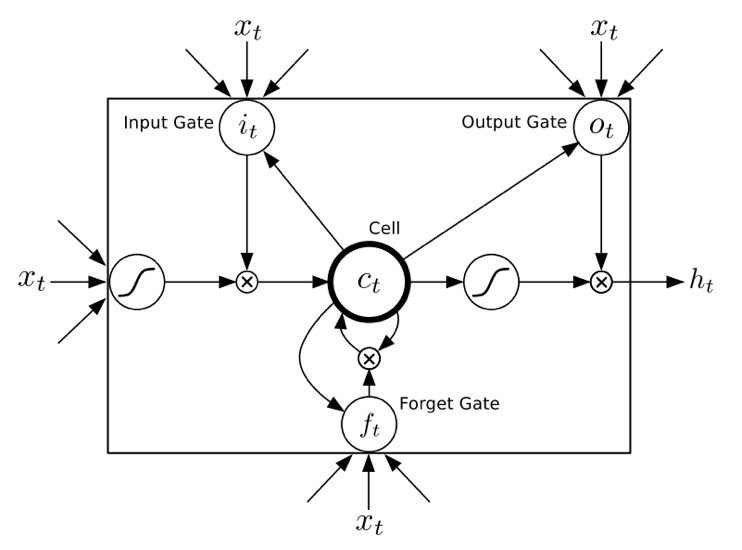
LSTM结构:


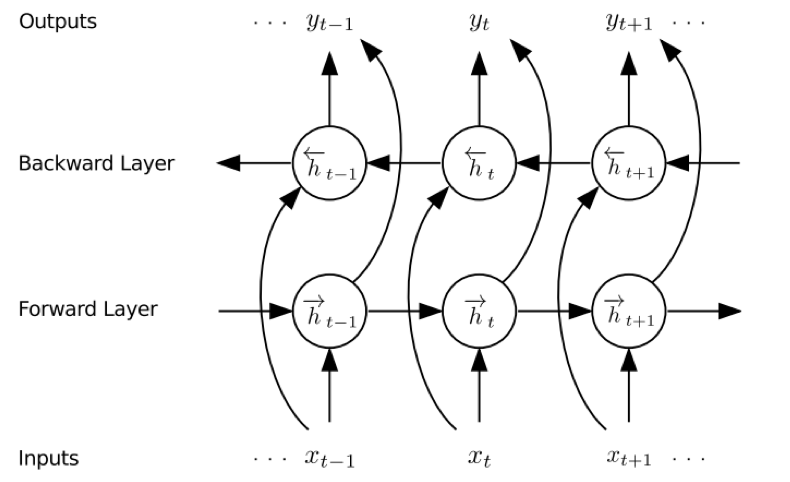
多层双向LSTM结构:
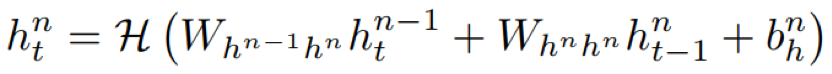

思想:
CTC对于当前时刻的输出只与当前时刻输入有关p(k|t),而RNN-T引入语音学的信息,不仅与当前时刻输入有关,还有历史的输出有关p(k|t,u);即RNN-T的两个网络输出,一个是CTC输出激活,另一个语言学预测模型输出激活,二者结合,一起输入到新的前馈神经网络,从而获得输出分布p(k|t,u);实验证明该思路有助于减少asr的删除错误

模型:
RNN-T 包含三个网络结构分支,一个是CTC网络、一个是语言学预测网络、第三个是前馈输出网络;
- CTC网络采用多层双向LSTM结构,输出为phoneme label加blank组成的后验概率分布
- 预测网络也采用多层非双向LSTM结构,输出为当前时刻的条件概率
- 联合网络采用前馈神经网络DNN结构,输出为基于当前时刻和历史输出文本信息的后验概率分布

细节:
- 输入:41fbank+一阶差分+二阶差分=123维
- 输入数据进行归一化为正态分布
- CTC网络预训练采用CTC损失、语言模型预测网络预训练采用交叉熵损失、联合网络采用CTC损失
- 训练过程中采用正则化思想引入验证集早停和添加高斯权重噪声机制
- 输出类别包括61phoneme+blank,最后映射成39个类别
- 解码采用beam search,论文认为比prefix更快且更高效
训练:
- 数据集:TIMIT,train 462speakers(separate 50speakers for dev)/test 24speakers
- CTC网络、预测网络采用均匀分布[-0.1,0.1]随机初始化或预训练初始化、输出网络采用[-0.1,0.1]随机初始化
- CTC网络和预测网络预训练时不引入权重噪声机制,重训练时引入噪声
- 预测网络预训练时实际采用了训练集文本,但是对于大词汇量任务最好采用外部独立文本数据
- 优化方法SGD,初始学习率0.0004,momentum=0.9
- 模型参数每训练序列后添加一次高斯权重噪声,σ = 0.075
- 利用验证集PER进行早停
- 解码时beam width = 100
实验:
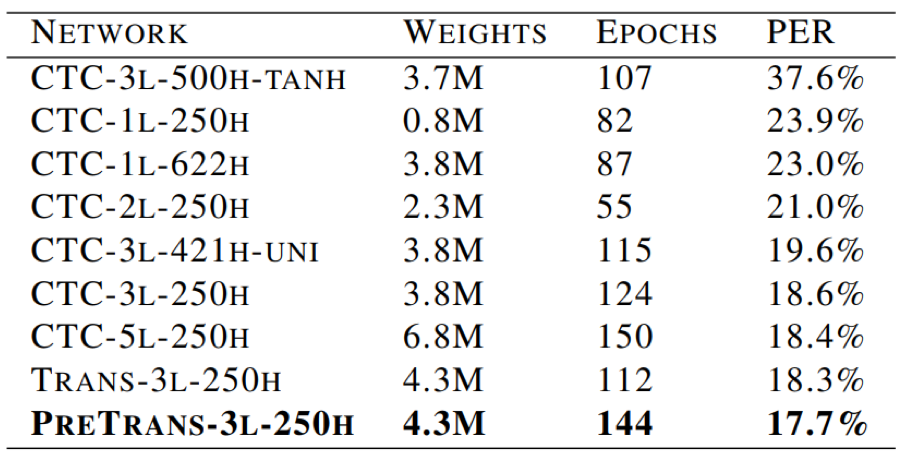
- 通过一系列tricks,RNN-T在TIMIT测试集上得到的最好效果为PER 17.7%
- LSTM结构比tanh在任务中表现的效果更好
- CTC网络结构,双向LSTM比单向LSTM具有轻微的优势
- 网络深度比网络宽度更重要
- 权重随机初始化时,transduser机制具有轻微优势;但是采用CTC网络和预测网络预训练机制,优势更加明显
Reference: