作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
前言:在上次的大作业中,我们已经爬取了豆瓣网的电影排行,包括电影名,图片链接,演员,印象,评分及评价数。同时又在这基础上对热门影片的短评进行提取,从而去了解观众们的喜爱!为我们的数据分析做下基础。详情请见于:https://www.cnblogs.com/zy5250/p/10786882.html。
一、将爬虫大作业产生的csv文件上传到HDFS
1、数据预处理
对csv文件预处理生成无标题的文本文件。
2、启动HDFS
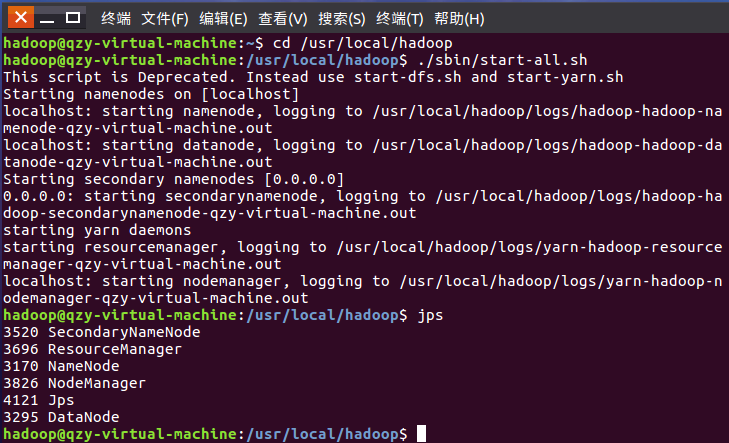
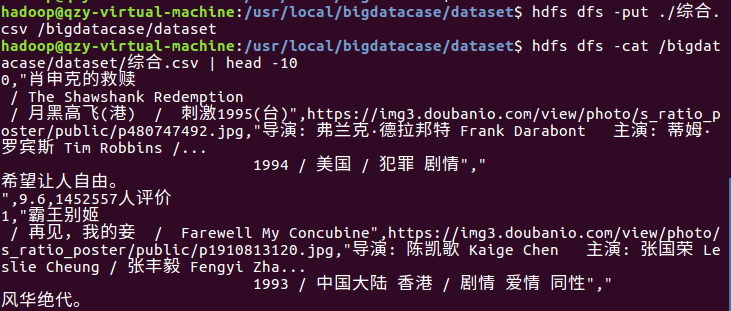
3、在HDFS上建立/bigdatacase/dataset文件夹,并将综合.csv、ww.csv上传到HDFS中

4、把hdfs中的文本文件最终导入到数据仓库Hive中
(1)启动hive

(2)在Hive中创建一个数据库dblab
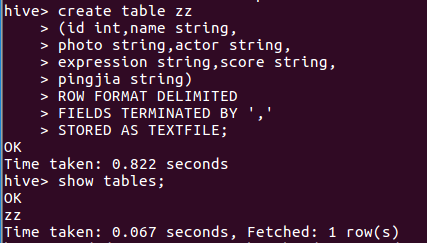
(3)创建表,把HDFS中的“/bigdatacase/dataset”目录下的数据加载到了数据仓库Hive中


5、用Hive对爬虫大作业产生的进行数据分析。(10条以上的分析结果)
* 查询前5条电影的数据,包括了其排名,电影名称(别名)图像,印象,评分,评价人数。
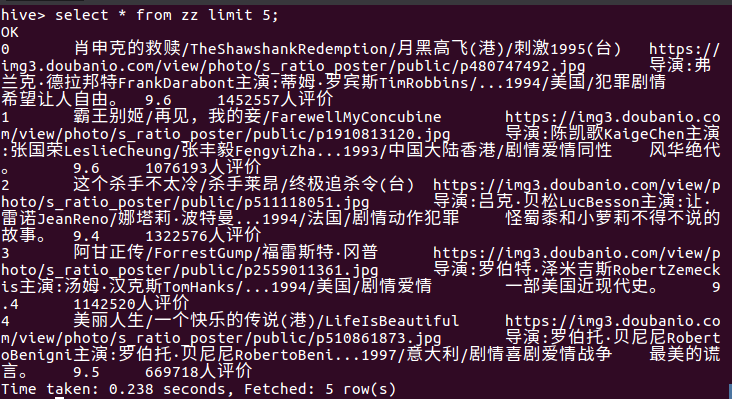
* 查询电影排行榜前5名的电影名及其评分。从筛选出的数据可知,肖申克的救赎这部电影排行第一。是一部不折不扣的好电影。
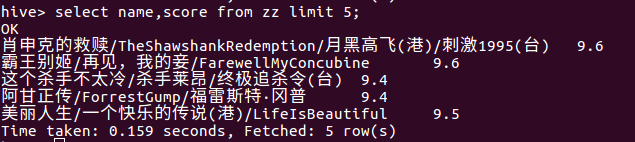
* 查询分数最高9.6评分的电影有哪些?并查看其在电影排行榜中的排名。分析其原因。其中9.6评分的有三部电影,为肖申克的救赎,霸王别姬,控方证人,其中肖申克的救赎和霸王别姬分别位于排行版的前两名。但同为分数最高的控方证人最排行第28,究其原因是在于评价人数太少,较难于影响别人的更多的看法。
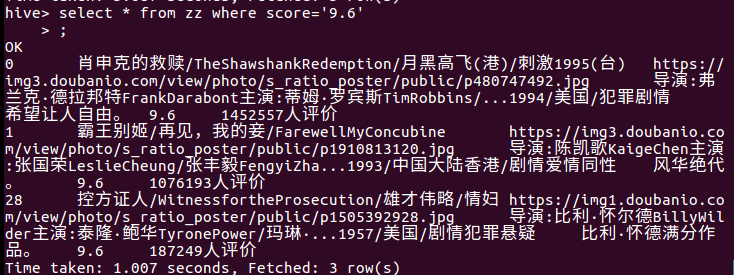
* 统计电影评分小于或者等于8.4的名称。
* 统计电影评分的个数,分析其为什么能够在Top250榜上有名。
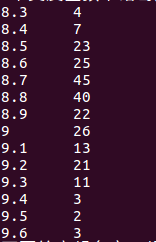
*对电影排行榜存入到hive后。由于我们的爬虫项目里面同样也爬取了肖申克的救赎的短评,用同样的方法把短评内容存放到hive中。具体步骤略,与上面的大同小异。
其中肖申克的救赎的短评数据如下:

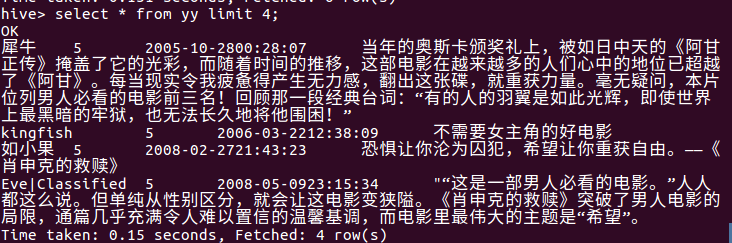
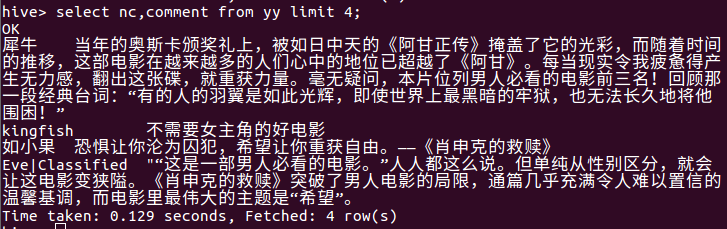
* 查询前四条短评数据的信息。
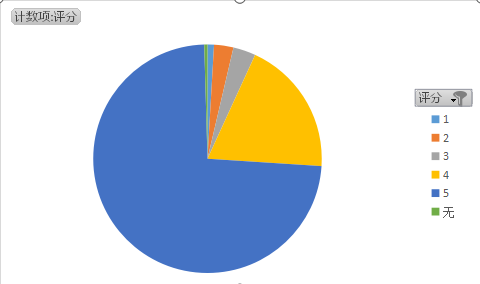
* 分别用以下的方式查询评分为5,评分为4,评分为3,评分为2,评分为1的数量。

生成统计图如下:
* 统计发表短评的人的昵称信息。
6、出现的问题及其解决方案
在导入到hive中时,由于电影名、短片等数据中本身出现了空格,导致数据要么出现了大量的空NULL,要么就出现了乱码!因此项目一直进行不下去。最终的解决方案是在导入到虚拟机前先删除掉空格,并且保存为utf8模式!
二、总结。
答:经过一学期的python和hadoop等知识点的学习,最终虽完成了本篇博客,但过程异常艰辛。好在最终经过百度、问同学、老师都得以解决!在此向他们表示谢意。同时经过本次项目,对python、hive等知识点有了更加清晰的了解和有了一定的知识架构!