一 三维卷积(Convolutions over Volumes)
前面已经讲解了对二维图像做卷积了,现在看看如何在三维立体上执行卷积。
我们从一个例子开始,假如说你不仅想检测灰度图像的特征,也想检测 RGB 彩色图像的特征。彩色图像如果是 6×6×3,这里的 3 指的是三个颜色通道,你可以把它想象成三个 6×6图像的堆叠。为了检测图像的边缘或者其他的特征,不是把它跟原来的 3×3 的过滤器做卷积,而是跟一个三维的过滤器,它的维度是 3×3×3,这样这个过滤器也有三层,对应红绿、蓝三个通道。
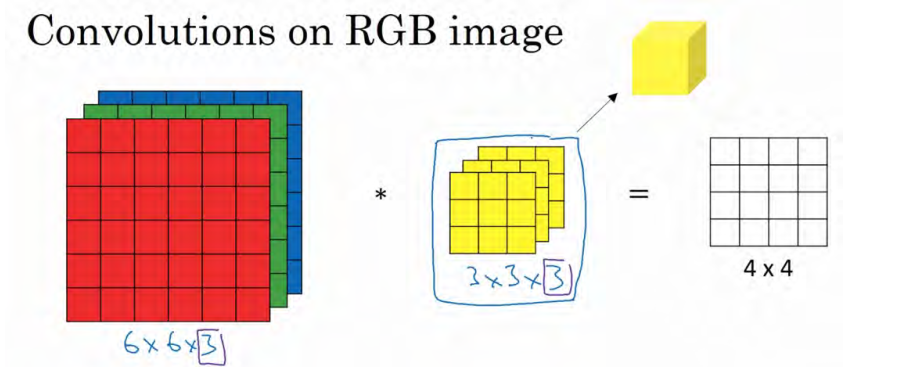
这里的第一个 6 代表图像高度,第二个 6 代表宽度,这个3 代表通道的数目。同样你的过滤器也有一个高,宽和通道数,并且图像的通道数必须和过滤器的通道数匹配,所以这两个数(紫色方框标记的两个数)必须相等。输出会是一个 4×4 的图像,注意是 4×4×1,最后一个数不是 3 了。
为了简化这个 3×3×3过滤器的图像,我们不把它画成 3 个矩阵的堆叠,而画成这样,一个三维的立方体。

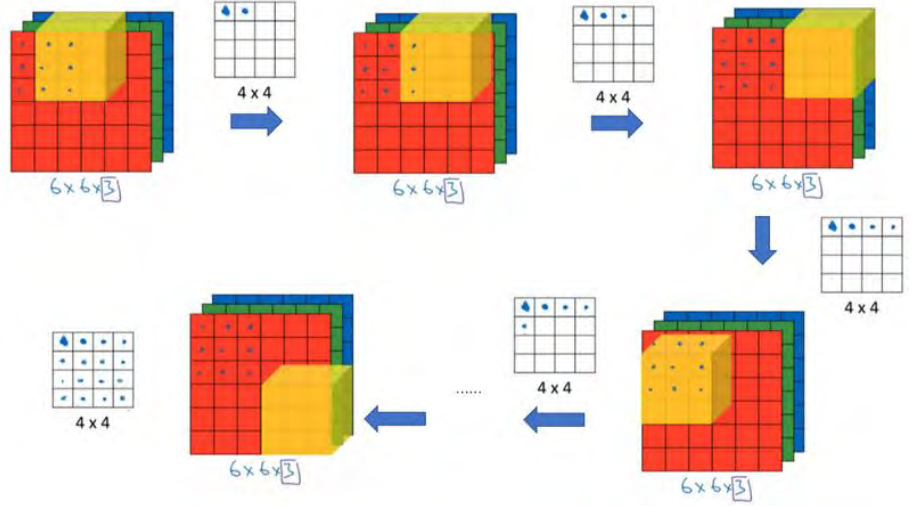
为了计算这个卷积操作的输出,你要做的就是把这个 3×3×3 的过滤器先放到最左上角的位置,这个 3×3×3 的过滤器有 27 个数, 27 个参数就是 3 的立方。依次取这 27 个数,然后乘以相应的红绿蓝通道中的数字。先取红色通道的前 9 个数字,然后是绿色通道,然后再是蓝色通道,乘以左边黄色立方体覆盖的对应的 27 个数,然后把这些数都加起来,就得到了输出的第一个数字。如果要计算下一个输出,你把这个立方体滑动一个单位,再与这 27 个数相乘,把它们都加起来,就得到了下一个输出,以此类推
。
那么,这个能干什么呢?举个例子,这个过滤器是 3×3×3 的, 如果你想检测图像红色通道的边缘, 那么你可以将第一个过滤器设为

和之前一样,而绿色通道和红色通道全为 0, 如果你把这三个堆叠在一起形成一个 3×3×3 的过滤器,那么这就是一个检测垂直边界的过滤器,但只对红色通道有用
。
或者如果你不关心垂直边界在哪个颜色通道里,那么你可以用一个这样的过滤器
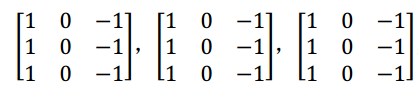
所有三个通道都是这样。所以通过设置过滤器参数,你就有了一个边界检测器, 3×3×3 的边界检测器,用来检测任意颜色通道里的边界。参数的选择不同,你就可以得到不同的特征检测器。
按照计算机视觉的惯例,当你的输入有特定的高宽和通道数时,你的过滤器可以有不同的高,不同的宽,但是必须一样的通道数。理论上,我们的过滤器只关注红色通道,或者只关注绿色或者蓝色通道也是可行的。
如果我们不仅仅想要检测垂直边缘怎么办?如果我们同时检测垂直边缘和水平边缘,还有 45°倾斜的边缘,还有 70°倾斜的边缘怎么做?换句话说,如果你想同时用多个过滤器怎么办?
我们可以同时使用多个过滤器。前面我们让这个 6×6×3 的图像和这个 3×3×3 的过滤器卷积,得到 4×4 的输出。(第一个)这可能是一个垂直边界检测器或者是学习检测其他的特征。第二个过滤器可以用橘色来表示,它可以是一个水平边缘检测器。

输入6×6×3 的图像和第一个过滤器卷积,可以得到第一个 4×4 的输出,然后卷积第二个过滤器,得到一个不同的 4×4 的输出。然后把这两个 4×4 的输出,取第一个把它放到前面,然后取第二个过滤器输出,放到后面。把这两个输出堆叠在一起,这样你就都得到了一个 4×4×2 的输出立方体。
总结
假设你有一个nxnxnc(通道数)的输入图像,设置步幅为 1,并且没有 padding 然后和nc'个fxfxnc的滤波器卷积,这样你就会得到(n-f+1)x(n-f+1)xnc'的输出。
补充:nc有两个术语,通道或者深度 。
二 单层卷积网络
这一节,主要讲解如何构建卷积神经网络的卷积层,下面来看个例子。 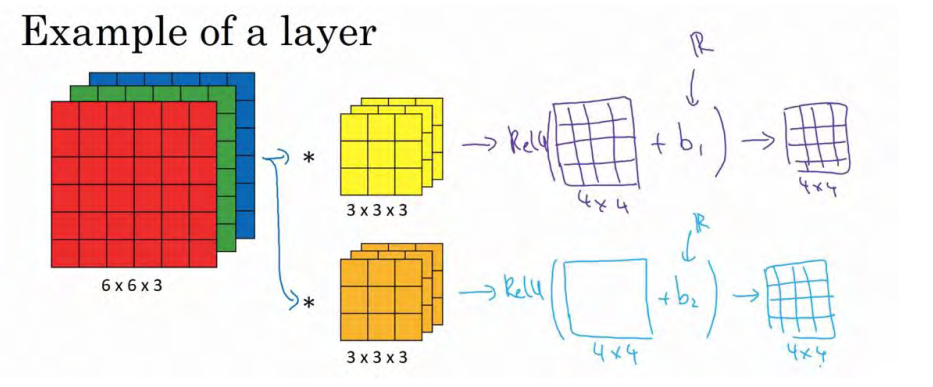
如图使用第一个过滤器进行卷积,得到第一个 4×4 矩阵。使用第二个过滤器进行卷积得到另外一个 4×4 矩阵。 对于每一层,加上一个偏差,通过 Python 的广播机制给这 16 个元素都加上同一偏差。然后应用非线性函数输出。对于第二个 4×4 矩阵,使用不同的偏置,进行同样的运算,最终得到另一个 4×4 矩阵。然后重复我们之前的步骤,把这两个矩阵堆叠起来,最终得到一个 4×4×2 的矩阵。
注意前向传播的一个操作就是z1 = w1a0+b1,其中a0=x,通过非线性函数计算得到a1=g(z1)。在卷积过程中,我们对这 27 个数进行操作,其实是 27×2,因为我们用了两个过滤器,我们取这些数做乘法。实际执行了一个线性函数,得到一个 4×4 的矩阵。卷积操作的输出结果是一个4×4 的矩阵,它的作用类似于
w1a0,也就是这两个 4×4 矩阵的输出结果,然后再加上偏差。
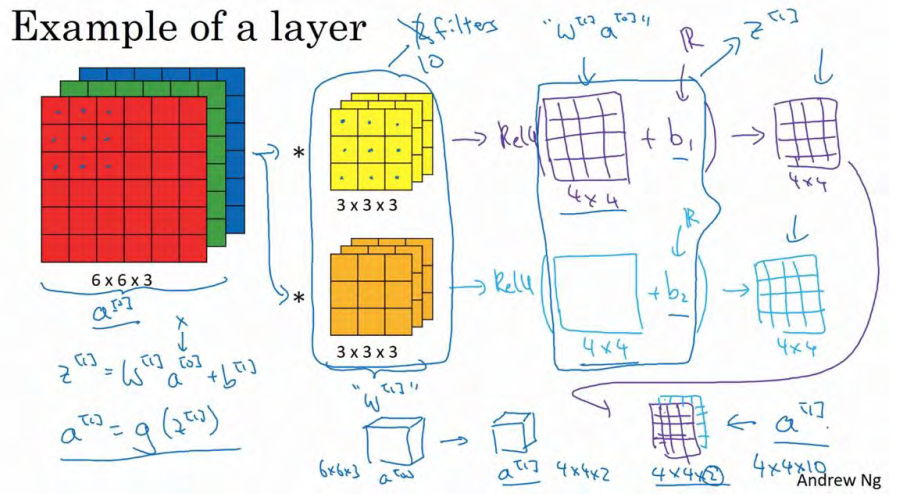
这一部分(图中蓝色边框标记的部分)就是应用激活函数 ReLU 之前的值,它的作用类 z1,最后应用非线性函数,得到的这个 4×4×2 矩阵,成为神经网络的下一层,也就是激活层。
这就是 a0到a1的的演变过程,首先执行线性函数,即所有元素相乘做卷积,再加上偏差,然后应用激活函数 ReLU。这样就通过神经网络的一层把一个6×6×3 的维度 a0演化出一个4×4×2 维度的 a1,这就是卷积神经网络的一层。
为了加深理解,我们来做一个练习。假设你有 10 个过滤器,而不是 2 个,神经网络的一层是 3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个 3×3×3 的矩阵,因此每个过滤器有 27 个参数,也就是 27 个数。然后加上一个偏差,用参数b表示,现在参数增加到 28 个。上一节我画了 2 个过滤器,而现在我们有 10 个,加在一起是 28×10,也就是 280 个参数。
请注意一点,不论输入图片有多大, 1000×1000 也好, 5000×5000 也好,参数始终都是280 个。用这 10 个过滤器来提取特征,如垂直边缘,水平边缘和其它特征。即使这些图片很大, 参数却很少, 这就是卷积神经网络的一个特征, 叫作“避免过拟合”。 你已经知道到如何提取 10 个特征,可以应用到大图片中,而参数数量固定不变,此例中只有 28 个,相对较少。
最后我们总结一下用于描述卷积神经网络中的一层(以l层为例),也就是卷积层的各种标记
。

三 简单卷积网络示例
假设你有一张图片,你想做图片分类或图片识别,把这张图片输入定义为x,然后辨别图片中有没有猫,用 0 或 1 表示,这是一个分类问题,我们来构建适用于这项任务的卷积神经网络。针对这个示例,我用了一张比较小的图片,大小是 39×39×3,这样设定可以使其中一些数字效果更好。所以 nH0=nW0,即宽度和高度都等于39,nc0=3,即0层的通道数为3。
假设第一层我们用一个 3×3 的过滤器来提取特征,那么f1=3。设置s1=1,p1=0,所以宽度和高度使用valid卷积,如果有 10 个过滤器,神经网络下一层的激活值为 37×37×10,写 10 是因为我们用了 10 个过滤器, 37 是公式 (n+2p-f)/s+1的计算结果,所以输出是 37×37,它是一个 vaild 卷积,这是输出结果的大小。 第一层标记为 nH1=nW1=37,nc1=10,nc1等于第一层中过滤器的个数,这(37×37×10)是第一层激活值的维度。
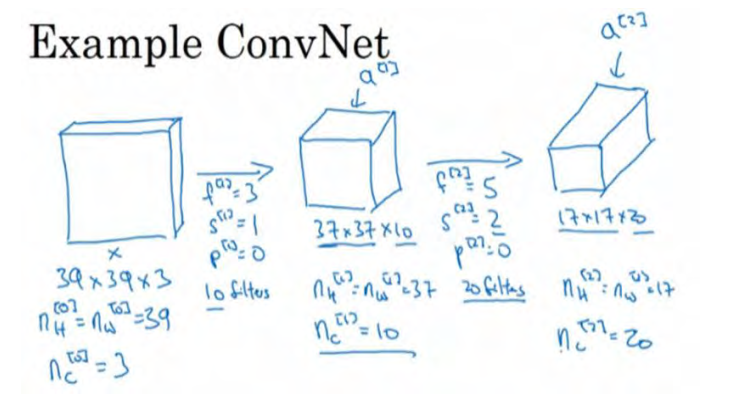
假设还有另外一个卷积层,这次我们采用的过滤器是 5×5 的矩阵。在标记法中,神经网络下一层的
f=5,即f2=5,步幅为2,即s2=2。padding 为 0,即 p2=0,且有 20 个过滤器。所以其输出结果会是一张新图像,这次的输出结果为 17×17×20,因为步幅是 2,维度缩小得很快,大小从 37×37 减小到 17×17,减小了一半还多,过滤器是 20 个,所以通道数也是 20, 17×17×20 即激活值
a2的维度,因此 nH2=nW2=17,nc2=20。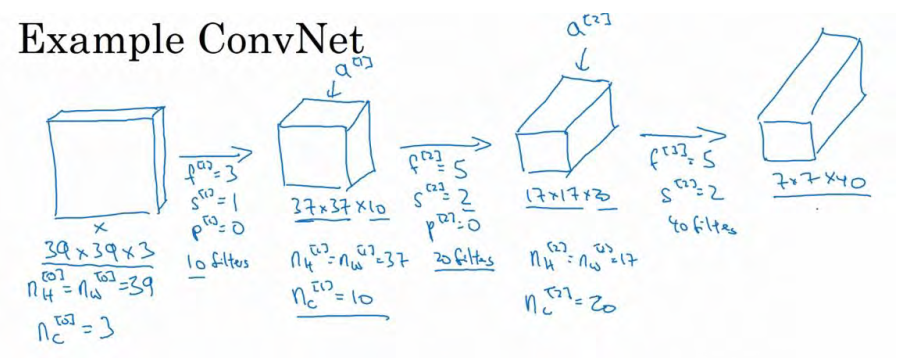
我们来构建最后一个卷积层,假设过滤器还是 5×5,步幅为 2,即 f3=5,s3=2,计算过程我跳过了,最后输出为 7×7×40,假设使用了 40 个过滤器。 padding 为 0, 40 个过滤器,最后结果为 7×7×40。
到此,这张 39×39×3 的输入图像就处理完毕了,为图片提取了 7×7×40 个特征,计算出来就是 1960 个特征。然后对该卷积进行处理,可以将其平滑或展开成 1960 个单元。平滑处 理后可以输出一个向量,其填充内容是 logistic 回归单元还是 softmax 回归单元,完全取决于我们是想识图片上有没有猫,还是想识别k种不同对象中的一种,用y_hat表示最终神经网络的预测输出。明确一点,最后这一步是处理所有数字,即全部的 1960 个数字,把它们展开成一个很长的向量。为了预测最终的输出结果,我们把这个长向量填充到 softmax 回归函数中 。

一个典型的卷积神经网络通常有三层,一个是卷积层,我们常常用 Conv 来标注。上一个例子,我用的就是 CONV。还有两种常见类型的层,一个是池化层,我们称之为 POOL。最后一个是全连接层,用 FC 表示。虽然仅用卷积层也有可能构建出很好的神经网络,但大部分神经望楼架构师依然会添加池化层和全连接层。幸运的是,池化层和全连接层比卷积层更容易设计。后两节课我们会讲解这两个概念以便你更好的了解神经网络中最常用的这几种层,你就可以利用它们构建更强大的网络了。

四 池化层(Pooling Layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性 。
先举一个池化层的例子,然后我们再讨论池化层的必要性。假如输入是一个 4×4 矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的是一个 2×2 矩阵。执行过程非常简单,把 4×4 的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于 2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。

左上区域的最大值是 9,右上区域的最大元素值是 2,左下区域的最大值是 6,右下区域的最大值是 3。为了计算出右侧这 4 个元素值,我们需要对输入矩阵的 2×2 区域做最大值运算。这就像是应用了一个规模为 2 的过滤器,因为我们选用的是 2×2 区域,步幅是 2,这些就是最大池化的超参数。
因为我们使用的过滤器为 2×2,最后输出是 9。然后向右移动 2 个步幅,计算出最大值2。然后是第二行,向下移动 2 步得到最大值 6。最后向右移动 3 步,得到最大值 3。这是一个 2×2 矩阵,即
f=2,步幅为2,即s=2。
最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了
f和s,它就是一个固定运算,梯度下降无需改变任何值。
我们来看一个有若干个超级参数的示例,输入是一个 5×5 的矩阵。我们采用最大池化 法,它的过滤器参数为 3x3,即f=3,步幅为1,s=1,输出矩阵是 3×3.之前讲的计算卷积层输出大小的公式同样适用于最大池化,即
(n+2p-f)/s+1,这个公式也可以计算最大池化的 输出。
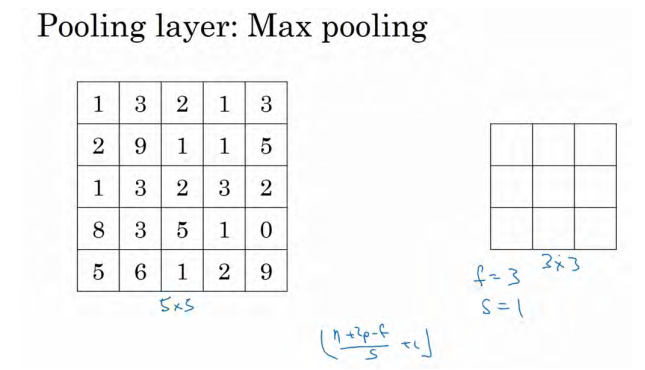
此例是计算 3×3 输出的每个元素,我们看左上角这些元素,注意这是一个 3×3 区域,因为有 3 个过滤器,取最大值 9。然后移动一个元素,因为步幅是 1,蓝色区域的最大值是 9.继续向右移动,蓝色区域的最大值是 5。然后移到下一行,因为步幅是 1,我们只向下移动一个格,所以该区域的最大值是 9。这个区域也是 9。这两个区域的最大值都是 5。最后这三个区域的最大值分别为 8, 6 和 9。超参数
f=3,s=1,最终输出如图所示。 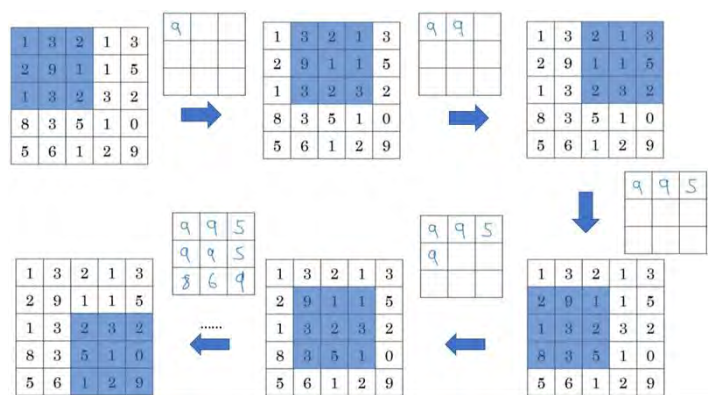
以上就是一个二维输入的最大池化的演示,如果输入是三维的,那么输出也是三维的 。例如,输入是 5×5×2,那么输出是 3×3×2。
另外还有一种类型的池化,平均池化,它不太常用。顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是 3.75,后面依次是 1.25、 4 和 2。这个平均池化的超级参数
f=2,s=2。
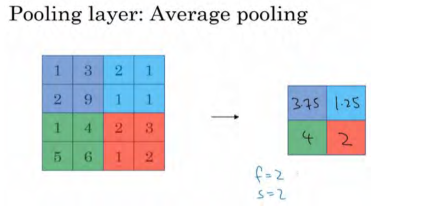
目前来说,最大池化比平均池化更常用。但也有例外,就是深度很深的神经网络,你可以用平均池化来分解规模为 7×7×1000 的网络的表示层,在整个空间内求平均值,得到1×1×1000。但在神经网络中,最大池化要比平均池化用得更多。
总结
池化的超级参数包括过滤器大小 f和步幅s,常用的参数值为 f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半。也有使用 f=3,s=2的情况,至于其它超级参数就要看你用的是最大池化还是平均池化了。你也可以根据自己意愿增加表示padding 的其他超级参数,虽然很少这么用。最大池化时,往往很少用到超参数 padding,当然也有例外的情况。大部分情况下,最大池化很少用 padding。目前
p最常用的值是 0,即
p=0,。最大池化的输入就是 nHxnWxnC,假设没有 padding,则输出( nH-f)/s+1 x ( nW-f)/s+1 x nC(向下取整)。输入通道与输出通道个数相同,因为我们对每个通道都做了池化。需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。

五 卷积神经网络示例
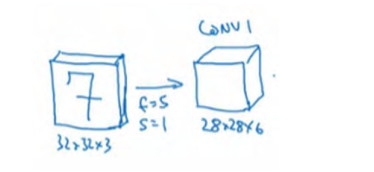
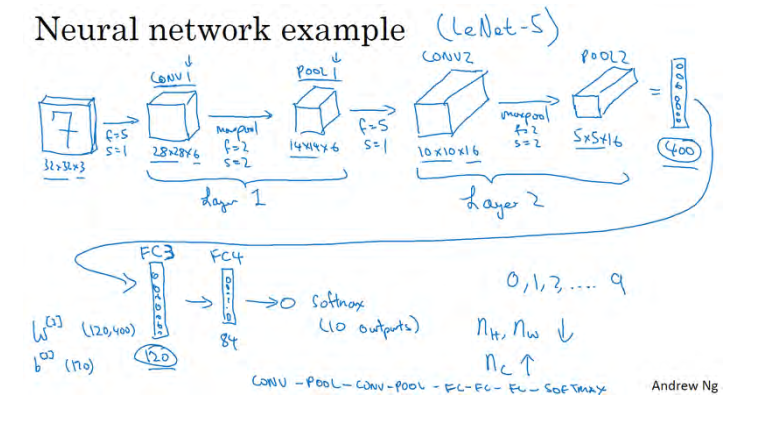
假设,有一张大小为 32×32×3 的输入图片,这是一张 RGB 模式的图片,你想做手写体数字识别。 32×32×3 的 RGB 图片中含有某个数字,比如 7,你想识别它是从 0-9 这 10 个数字中的哪一个,我们构建一个神经网络来实现这个功能。
我们使用的这个网络模型和经典网络 LeNet-5 非常相似,灵感也来源于此。 LeNet-5 是多年前 Yann LeCun 创建的,这里所采用的模型并不是 LeNet-5,但是受它启发,许多参数选择都与LeNet-5 相似。输入是 32×32×3 的矩阵,假设第一层使用过滤器大小为 5×5,步幅是 1, padding是 0,过滤器个数为 6,那么输出为 28×28×6。将这层标记为 CONV1,它用了 6 个过滤器,增加了偏差,应用了非线性函数,可能是 ReLU 非线性函数,最后输出 CONV1 的结果。
然后构建一个池化层,这里我选择用最大池化,参数f=2,s=2,padding 为 0。现在开始构建池化层,最大池化使用的过滤器为 2×2,步幅为 2,池化层的高度和宽度会减少一半。因此, 28×28 变成了 14×14,通道数量保持不变,所以最终输出为 14×14×6,将该输出标记为 POOL1。
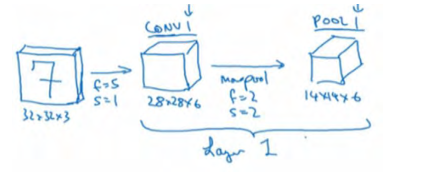
人们发现在卷积神经网络文献中,卷积有两种分类,这与所谓层的划分存在一致性。一类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的 Layer1。另一类卷积是把卷积层作为一层,而池化层单独作为一层。人们在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。这里, 我们把 CONV1和 POOL1 共同作为一个卷积,并标记为 Layer1。虽然你在阅读网络文章或研究报告时,你可能会看到卷积层和池化层各为一层的情况,这只是两种不同的标记术语。一般我在统计网络层数时,只计算具有权重的层,也就是把 CONV1 和 POOL1 作为 Layer1。这里我们用 CONV1和 POOL1 来标记,两者都是神经网络 Layer1 的一部分, POOL1 也被划分在 Layer1 中,因为它没有权重,得到的输出是 14×14×6。
我们再为它构建一个卷积层,过滤器大小为 5×5,步幅为 1,这次我们用 10 个过滤器,最后输出一个 10×10×10 的矩阵,标记为 CONV2。 然后做最大池化,超参数f=2,s=2,高度和宽度会减半,最后输出为 5×5×10,标记为 POOL2,这就是神经网络的第二个卷积层,即 Layer2。
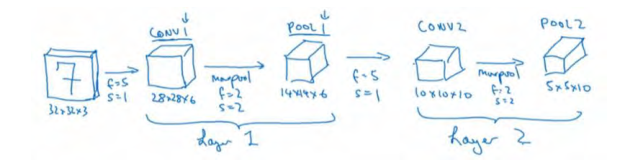
如果对 Layer1 应用另一个卷积层,过滤器为 5×5,即 f=5,s=1,过滤器 16 个,所以 CONV2 输出为 10×10×16。 然后做最大池化,超参数 f=2,s=2,高度和宽度会减半,最后输出为 5×5×16,通道数和之前一样,标记为 POOL2。 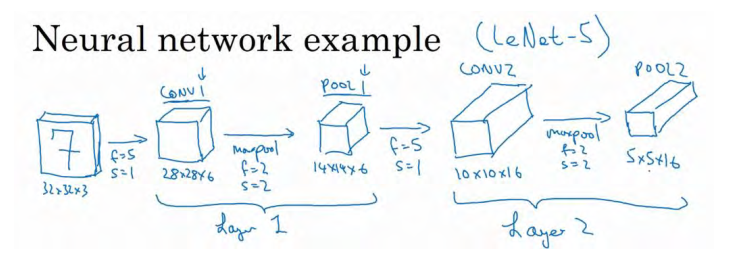
5×5×16 矩阵包含 400 个元素,现在将 POOL2 平整化为一个大小为 400 的一维向量。我们可以把平整化结果想象成这样的一个神经元集合,然后利用这 400 个单元构建下一层。下一层含有 120 个单元,这就是我们第一个全连接层,标记为 FC3。这 400 个单元与 120 个单
元紧密相连,这就是全连接层,这是一个标准的神经网络。它的权重矩阵为W3,维度为120x400,这就是所谓的“全连接”, 因为这 400 个单元与这 120 个单元的每一项连接,还有一个偏差参数。最后输出 120 个维度。
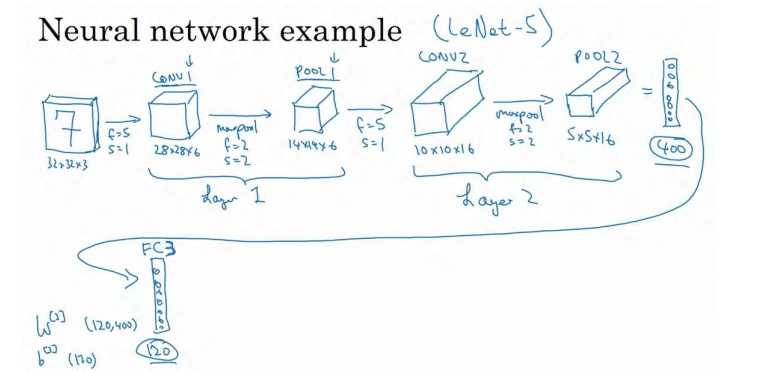
然后我们对这个 120 个单元再添加一个全连接层,这层更小,假设它含有 84 个单元, 标记为 FC4。
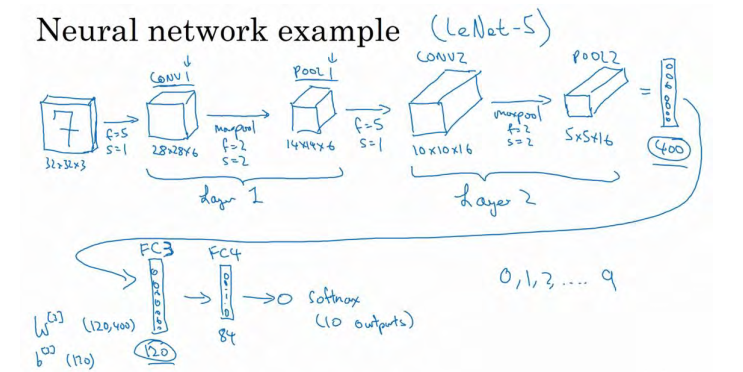
最后,用这 84 个单元填充一个 softmax 单元。如果我们想通过手写数字识别来识别手写 0-9 这 10 个数字,这个 softmax 就会有 10 个输出。
此例中的卷积神经网络很典型,看上去它有很多超参数,关于如何选定这些参数。常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序
。
我们会发现,随着神经网络深度的加深,高度 nH和nW通常都会减少,从 32×32 到 28×28,到 14×14,到 10×10,再到 5×5。所以随着层数增加, 高度和宽度都会减小,而通道数量会增加,从 3 到 6 到 16 不断增加,然后得到一个全连接层。 在神经网络中,另一种常见模式就是一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个 softmax。这是神经网络的另一种常见模式。
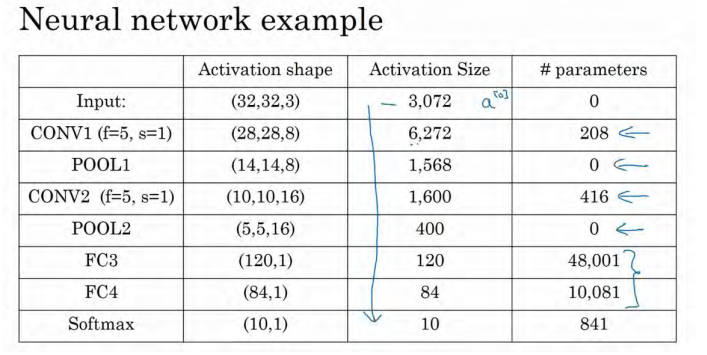
接下来我们讲讲神经网络的激活值形状,激活值大小和参数数量。输入为 32×32×3,这些数做乘法,结果为 3072,所以激活值 a0有3072 维,激活值矩阵为 32×32×3,输入层没有参数。计算其他层的时候,试着自己计算出激活值,这些都是网络中不同层的激活值形状和激活值大小。
一个卷积神经网络包括卷积层、池化层和全连接层。许多计算机视觉研究正在探索如何把这些基本模块整合起来,构建高效的神经网络,整合这些基本模块确实需要深入的理解。找到整合基本构造模块最好方法就是大量阅读别人的案例。
使用卷积网络的优点:
- 一是参数共享 。观察发现,特征检测如垂直边缘检测如果适用于图片的某个区域,那么它也可能适用于图片的其他区域。也就是说,如果你用一个 3×3 的过滤器检测垂直边缘,那么图片的左上角区域,以及旁边的各个区域(左边矩阵中蓝色方框标记的部分)都可以使用这个 3×3 的过滤器。每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其它特征。它不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征,例如提取脸上的眼睛,猫或者其他特征对象。即使减少参数个数,这 9 个参数同样能计算出 16 个输出。直观感觉是,一个特征检测器,
如垂直边缘检测器用于检测图片左上角区域的特征,这个特征很可能也适用于图片的右下角区域。因此在计算图片左上角和右下角区域时,你不需要添加其它特征检测器。假如有一个这样的数据集,其左上角和右下角可能有不同分布,也有可能稍有不同,但很相似,整张图片共享特征检测器,提取效果也很好。
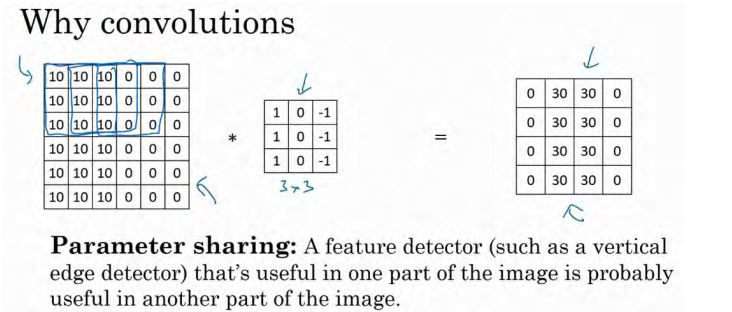
- 稀疏连接。这个 0 是通过3×3 的卷积计算得到的,它只依赖于这个 3×3 的输入的单元格, 右边这个输出单元(元素 0)仅与 36 个输入特征中 9 个相连接。而且其它像素值都不会对输出产生任影响,这就是稀疏连接的概念。
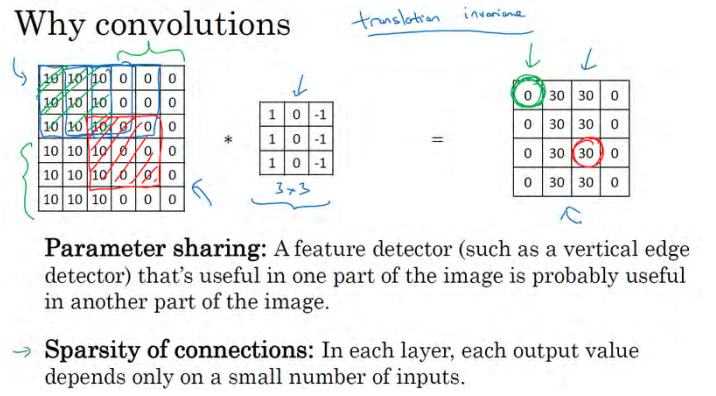
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防过度拟合。你们也可能听过,卷积神经网络善于捕捉平移不变。通过观察可以发现,向右移动两个像素,图片中的猫依然清晰可见,因为神经网络的卷积结构使得即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记。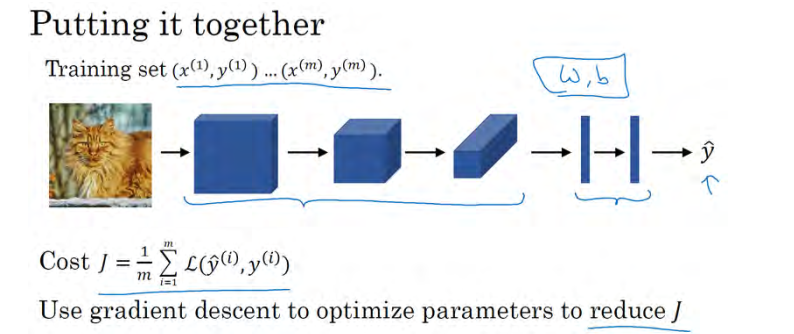
最后,我们把这些层整合起来,看看如何训练这些网络。比如我们要构建一个猫咪检测器,我们有下面这个标记训练集, x表示一张图片, y_hat是二进制标记或某个重要标记。我们选定了一个卷积神经网络,输入图片,增加卷积层和池化层,然后添加全连接层,最后输出一个 softmax。卷积层和全连接层有不同的参数 w和b,我们可以用任何参数集合来定义代价函数。一个类似于我们之前讲过的那种代价函数,并随机初始化其参数 w和b,代价 函 数 J等 于 神 经 网 络 对 整 个 训 练 集 的 预 测 的 损 失 总 和 再 除 以m(上图中),所以训练神经网络,你要做的就是使用梯度下降法,或其它算法,例如 Momentum 梯度下降法,含 RMSProp 或其它因子的梯度下降来优化神经网络中所有参数,以减少代价函数。