本文参考《数据科学家联盟》饼干文章。
一、无量纲化:最值归一化、均值方差归一化及sklearn中的Scaler
在量纲不同的情况下,不能反映样本中每一个特征的重要程度时,将需要使用归一化方法。
一般来说解决方法为把所有的数据都映射到同一个尺度(量纲)上。
1、常用的数据归一化有两种:
最值归一化(normalization):
把所有数据映射到0-1之间。最值归一化的使用范围是特征的分布具有明显边界的(分数0~100分、灰度0~255),受outlier的影响比较大
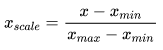
均值方差归一化(standardization):
把所有数据归一到均值为0方差为1的分布中。适用于数据中没有明显的边界,有可能存在极端数据值的情况.

2、sklearn中的Scaler
建模时要将数据集划分为训练数据集&测试数据集。
训练数据集进行归一化处理,需要计算出训练数据集的均值mean_train和方差std_train。
问题是:我们在对测试数据集进行归一化时,要计算测试数据的均值和方差么?
答案是否定的。在对测试数据集进行归一化时,仍然要使用训练数据集的均值train_mean和方差std_train。这是因为测试数据是模拟的真实环境,真实环境中可能无法得到均值和方差,对数据进行归一化。只能够使用公式(x_test - mean_train) / std_train并且,数据归一化也是算法的一部分,针对后面所有的数据,也应该做同样的处理.
因此我们要保存训练数据集中得到的均值和方差。
在sklearn中专门的用来数据归一化的方法:StandardScaler。
###下载数据集 import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split iris = datasets.load_iris() X = iris.data y = iris.target X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=666) ###归一化 from sklearn.preprocessing import StandardScaler standardScaler = StandardScaler() # 归一化的过程跟训练模型一样 standardScaler.fit(X_train) standardScaler.mean_ standardScaler.scale_ # 表述数据分布范围的变量,替代std_ # 使用transform X_train_standard = standardScaler.transform(X_train) X_test_standard = standardScaler.transform(X_test)
二、缺失值处理
1、确定缺失值范围
对每个字段都计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略,可用下图表示:
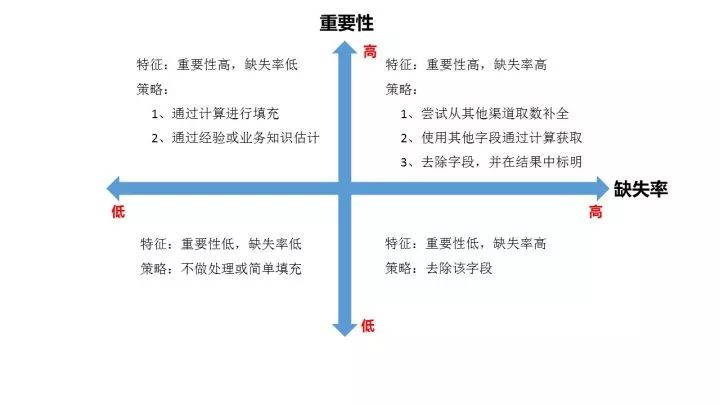
2、去除不需要的字段
建议清洗每做一步都备份一下,或者在小规模数据上试验成功再处理全量数据。
3、填充缺失内容
1)人工填充(filling manually)
根据业务知识来进行人工填充。
2)特殊值填充(Treating Missing Attribute values as Special values)
将空值作为一种特殊的属性值来处理,它不同于其他的任何属性值。如所有的空值都用“unknown”填充。一般作为临时填充或中间过程。
df['Feature'].fillna('unknown', inplace=True)
3)统计量填充
若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况进行填充。
常用填充统计量:
-
平均值:
对于数据符合均匀分布,用该变量的均值填补缺失值。
-
中位数:
对于数据存在倾斜分布的情况,采用中位数填补缺失值。
-
众数:
离散特征可使用众数进行填充缺失值。
平均值填充法:
将初始数据集中的属性分为数值属性和非数值属性来分别进行处理。
# 以pandas库操作为例 display(df.head(10)) # 填充前数据 Feature1 Feature2 Label 0 1.0 A 1 1 2.0 A 1 2 3.0 A 1 3 4.0 C 1 4 NaN A 1 5 2.0 None 0 6 3.0 B 0 7 3.0 None 0 8 NaN B 0 9 NaN B 0 # 均值填充 df['Feature1'].fillna(df['Feature1'].mean(), inplace=True) # 中位数填充 df['Feature2'].fillna(df['Feature2'].mode().iloc[0], inplace=True) display(df.head(10)) # 填充后数据 Feature1 Feature2 Label 0 1.000000 A 1 1 2.000000 A 1 2 3.000000 A 1 3 4.000000 C 1 4 2.571429 A 1 5 2.000000 A 0 6 3.000000 B 0 7 3.000000 A 0 8 2.571429 B 0 9 2.571429 B 0
条件平均值填充法(Conditional Mean Completer):
在该方法中,用于求平均值/众数/中位数并不是从数据集的所有对象中取,而是从与该对象具有相同决策属性值的对象中取得。
# 条件平均值填充 def condition_mean_fillna(df, label_name, feature_name): mean_feature_name = '{}Mean'.format(feature_name) group_df = df.groupby(label_name).mean().reset_index().rename(columns={feature_name: mean_feature_name}) df = pd.merge(df, group_df, on=label_name, how='left') df.loc[df[feature_name].isnull(), feature_name] = df.loc[df[feature_name].isnull(), mean_feature_name] df.drop(mean_feature_name, inplace=True, axis=1) return df df = condition_mode_fillna(df, 'Label', 'Feature2')
4)模型预测填充
使用待填充字段作为Label,没有缺失的数据作为训练数据,建立分类/回归模型,对待填充的缺失字段进行预测并进行填充。
最近距离邻法(KNN)
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均/投票来估计该样本的缺失数据。
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor def knn_missing_filled(x_train, y_train, test, k = 3, dispersed = True): ''' @param x_train: 没有缺失值的数据集 @param y_train: 待填充缺失值字段 @param test: 待填充缺失值数据集 ''' if dispersed: clf = KNeighborsClassifier(n_neighbors = k, weights = "distance") else: clf = KNeighborsRegressor(n_neighbors = k, weights = "distance") clf.fit(x_train, y_train) return test.index, clf.predict(test)
回归(Regression)
基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。常用线性回归。
4)重新取数
如果某些指标非常重要又缺失率高,那就需要和取数人员或业务人员了解,是否有其他渠道可以取到相关数据。
三、处理分类型特征:编码与哑变量
参考链接:https://www.cnblogs.com/juanjiang/archive/2019/05/30/10948849.html
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是["小学",“初中”,“高中”,"大学"],付费方式可能包含["支付宝",“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
preprocessing.OneHotEncoder:独热编码,创建哑变量
四、处理连续型特征:二值化与分段
-
sklearn.preprocessing.Binarizer
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯设置中的伯努利分布建模)。