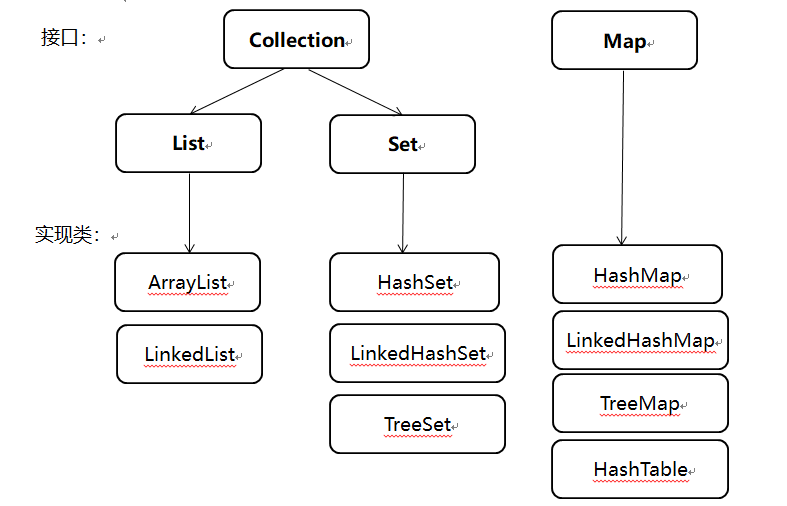
Java集合框架的组成
注意:四个接口的区别
① Collection:存储无序的、不唯一的数据;
② List:存储有序的、不唯一的数据;
③ Set:存储无序的、唯一的数据;
④ Map:以键值对的形式存储数据,以键取值,键不可以重复、值可以重复。
下面分别看一下各个接口和对应的实现类:

一、List接口
有序、不唯一
1、常用方法:
① add(): 在列表的最后添加元素;
② add(index,obj): 在列表的指定位置插入元素;
③ size(): 返回当前列表的元素个数;
④ get(int index): 返回下标为index的元素;
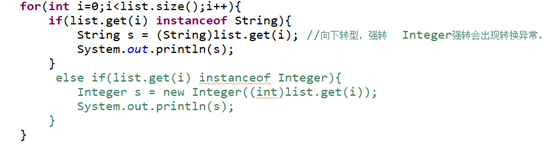
如果没有泛型约束,返回object类型,需要强转;如果有泛型约束,直接返回泛型类型,无需强转
⑤ clear(): 清除列表中所有元素。
isEmpty(): 如果此列表不包含元素,则返回 true。 检测列表是否为空。
⑥ contains(): 传入一个对象,检测列表中是否包含该对象;
如果传入的是String 和 基本数据类型,可以直接比对;
如果传入的是实体对象,则默认只对比两个对象的地址。因此,需要在实体类重写equal()方法。
⑦ indexof(): 传入一个对象,返回该对象在列表中首次出现的地址。
LastIndexof(): 最后一次。
⑧ remove(): 传入一个下标,或者一个对象,删除指定元素。
如果传入下标,返回被删除的元素对象。如果下标大于size(),会报下标越界异常。
如果传入对象,则要求重写equal()方法,返回true或false表示删除是否成功。
⑨ set(index,object): 用新传入的对象,将指定位置的元素替换掉。
返回被替换掉的元素对象。
⑩ List.subList(1,3): 截取一个子列表,返回List类型。
toArray(): 将列表转为数组,返回一个object[]类型的数组。
2、实现类:
1)ArrayList
实现了一个长度可变的数组,在内存空间中开辟一串连续的空间,与数组的区别在于长度可以随意修改。
这种存储结构,在循环遍历和随机访问元素时的速度比较快。
2)LinkedList
使用链表结构存储数据,在插入和删除元素时速度非常快。
线程不安全,速度较快,常用!
LinkedList 的特有方法:
① add.first(): 开头插入元素。(在该列表开头插入指定的元素。)
add.last(): 结尾插入元素。(将指定的元素追加到此列表的末尾。)
② removeFirst(): 删除第一个元素,并返回被删除的元素。
removeLast(): 删除最后一个元素,并返回被删除的元素。
③ getFirst(): 返回列表的第一个元素,并不会被删除。
getLast(): 返回列表的最后一个元素,并不会被删除。
3、List循环遍历方法:
1)使用for循环遍历列表:
2)使用foreach遍历列表:

3)使用iterator迭代器遍历列表
① 使用列表调用 .iterator()返回一个迭代器对象。
② 使用迭代器对象调用.hasNext()判断是否有下一条数据。
③ 使用迭代器对象调用.next()取出下一条数据

二、Set接口
无序、唯一
1、常用方法:
与List接口基本相同。(参考上述List接口常用方法 ↑↑↑)
但是,由于Set接口中的元素是无序的,因此没有与下标相关的方法。
例如:get(index) remove(index) add(index,obj) ... ...
2、实现类
1)HashSet
HashSet 底层是调用HashMap的相关方法,传入数据后,根据数据的hashCode进行散列运算。
得到一个散列值后再进行运算,确定元素在序列中存储的位置。
HashSet如何确定两个对象是否相等?(存储无序、唯一的数据)
① 先判断对象的hashCode(),如果hashCode不同,那肯定不是一个对象;
如果hashCode相同,那继续判断equal方法。
② 重写equal()方法。
>>>所以,使用HashSet存储实体对象时,必须重写hashCode()和equal()两个方法!
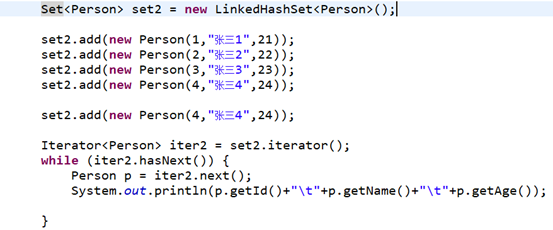
2)LinkedHashSet
LinkedHashSet:在HashSet的基础上,新建了一个链表。
用链表来记录HashSet中元素放入的顺序,因此使用迭代器遍历时,可以按照放入的顺序依次读出元素。
3)TreeSet
TreeSet:将存入的元素,进行排序,然后再输出。(二叉树原理)
如果存入的是实体对象:
(1)那么实体类必须实现Comparable接口,并重写compareTo()方法。
Set<Person> set3 = new TreeSet<Person>();
排序后,遍历输出:
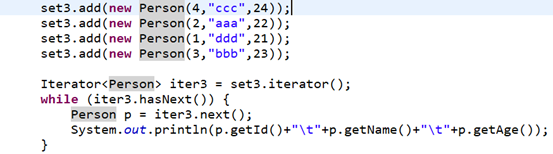
实现Comparable接口:
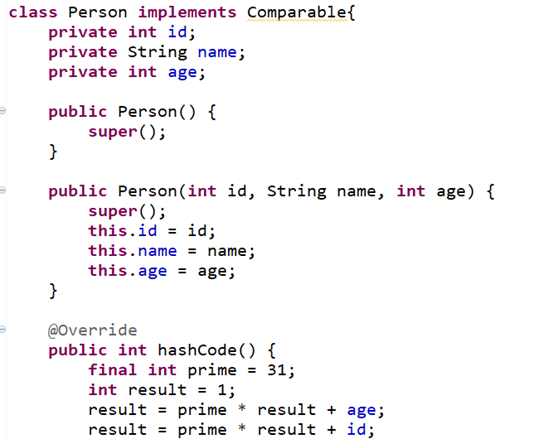
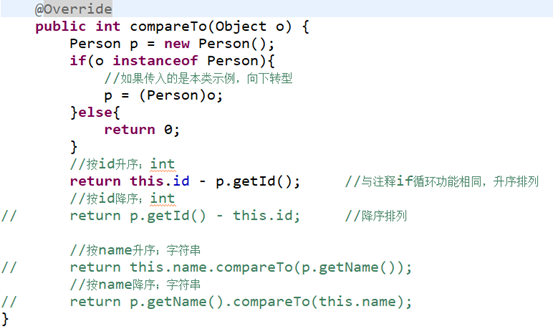
重写compareTo()方法:
(2)或者,也可以在实例化TreeSet的同时,通过构造函数传入一个比较器;
比较器:一个实现了Comparator接口,并重写了compare()方法的实现类的对象。
① 使用匿名内部类,拿到一个比较器对象。
Set<Person> set = new TreeSet<Person>(new Comparator(){
public int compare(Person p1,Person p2){
return p1.getId() - p2.getId();
}
});
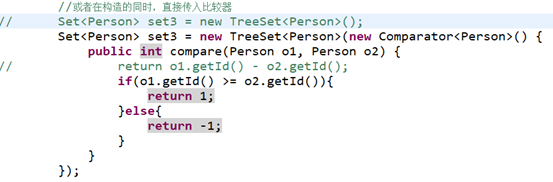
② 自定义一个比较类,实现Comparator 接口。
Set<Person> set = new TreeSet<Person>(new Compare());
class Compare implements Comparator(){
// 重写compare方法。
}

[ Comparable接口 和 Comparator接口 的区别 ]
① Comparable 由实体类实现,重写compareTo()方法;
实体类实现Comparable接口以后,TreeSet使用空参构造即可。
② Comparator 需要单独一个比较类进行实现,重写compare()方法。
实例化TreeSet的时候,需要传入这个比较类的对象。
三、Map接口
以键值对的形式存储数据,以键取值;键不能重复,值可以重复。
1、常用方法:
① put(key,value): 向map的最后追加一个键值对;
② get(key): 通过键,取到一个值;
③ clear(): 清除map中的所有数据;
④ containsValue(obj): 检测是否包含指定的值;
containsKey(obj): 检测是否包含指定的键。
⑤ replace(key,oid v,new v): 替换值
2、实现类:
1)HashMap 与 HashTable
区别:
① HashTable 是线程安全(线程同步)的,HashMap是线程不安全的(线程不同步);
② HashTable 的键不能为null;HashMap的键可以为null;
2)LinkedHashMap
可以使用链表,记录数据放入的次序,读出的顺序和放入的顺序一致,与LinkedHashSet一样。
3)TreeMap
根据键的顺序,进行排序后,输出。(与TreeSet类似,参见上述TreeSet)
如果传入的是实体对象,必须重写比较函数。(见TreeSet)
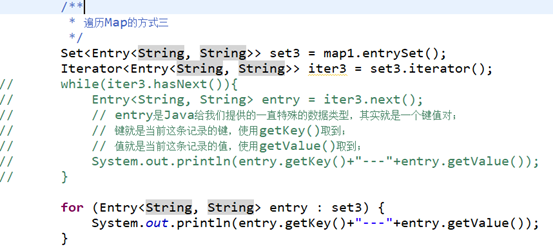
3、遍历Map的方式: