自然语言处理(NLP)
NLP中最细粒度的是词语(word),词语组成句子,句子再组成段落、章节和文档。所以NLP的核心问题就是:如何理解word
如何理解word
由于目标是与计算机对接,其核心就是如何给计算机描述一个word,有以下两种描述方式:
One-hot Representation
Distributional Representation
One-hot Representation
采用稀疏存储,把每个词表示成一个很长的向量,向量长度是词表大小,向量中只有一个值是1,其余全是0
缺点:稀疏且高维度
没有语义信息
Distributional Representation
分布式表示:对于每一个词,用低维稠密的向量来表示,每个维度可以表示该词在这个维度的分布情况
注意:向量长度可以自己指定
word2vec是由谷歌科学家Mikolov在2013年所提出来的算法,其算法解决了如何将word映射成一个能保持语义信息的向量

word2vec采用Skip-Gram语言模型:learning word representations by predicting its nearby words
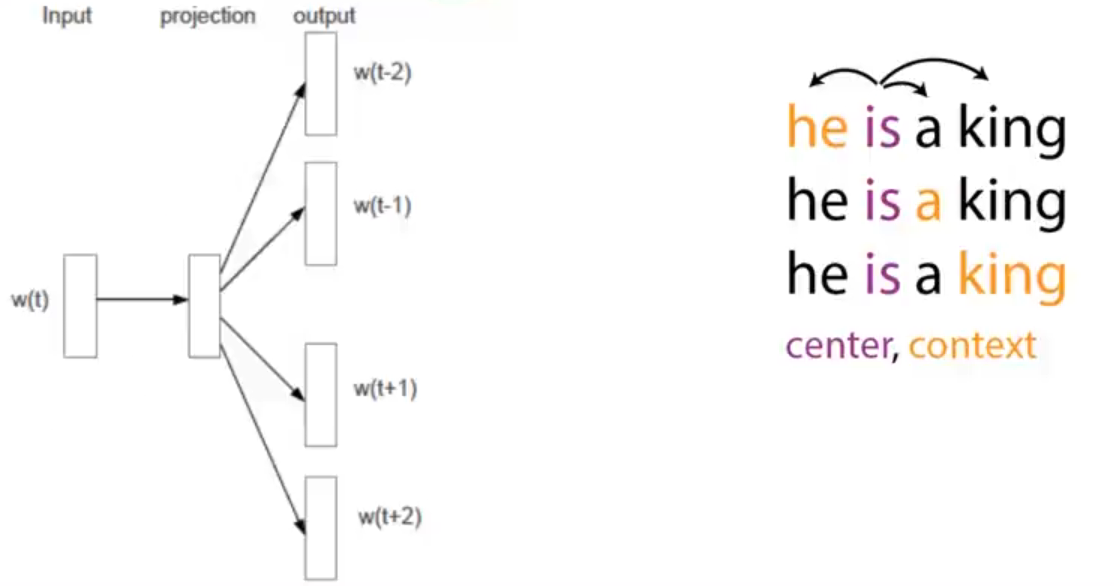

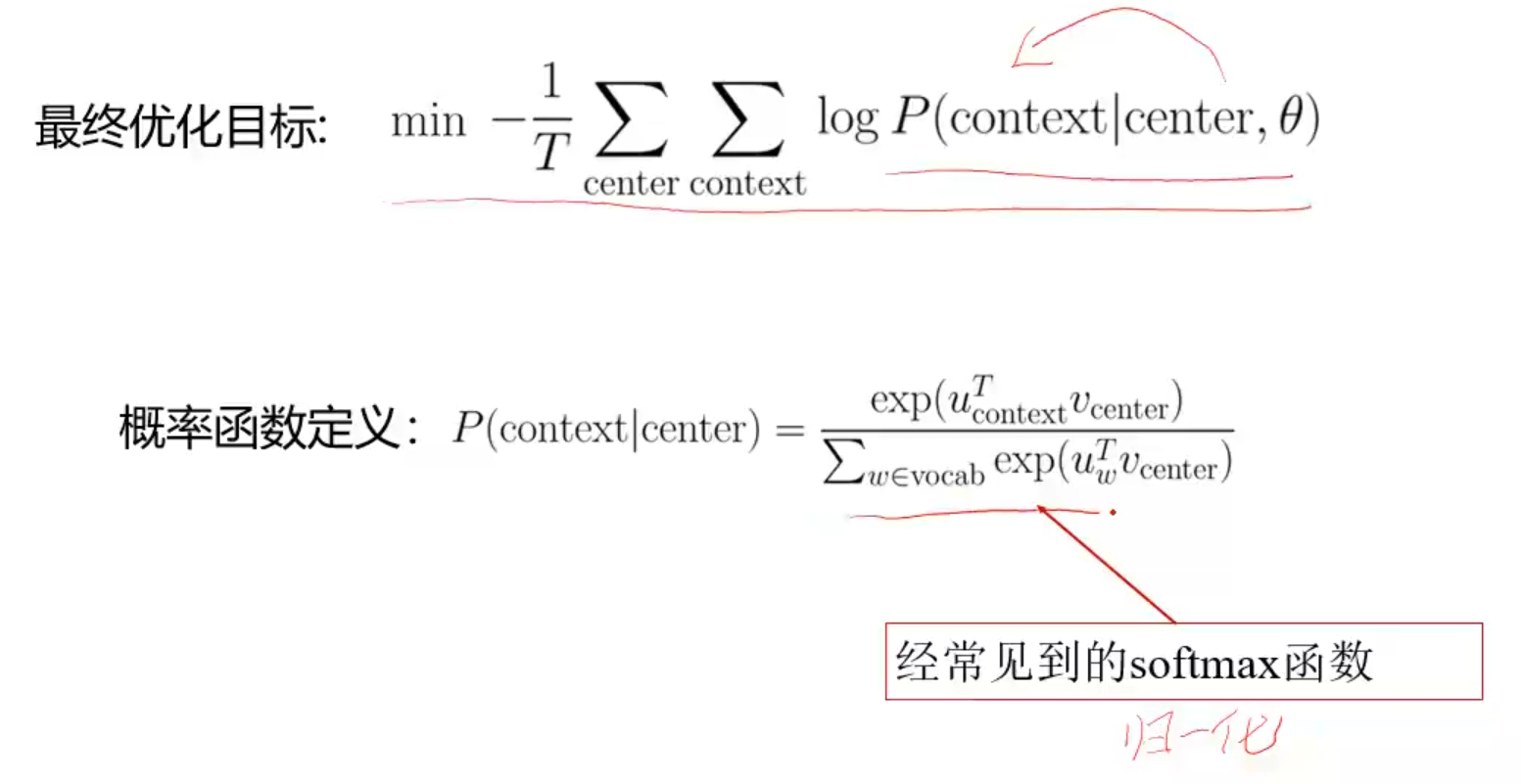
进行优化

Word2vec应用
有非常多的应用,比如搜索,文档分类,推荐等等
代表性工作:谷歌的神经翻译机,将Cn^2个翻译模型简化为一个模型(传说中的巴别通天塔)

