在Hadoop集群的基础上搭建Spark
一、环境准备
在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark的安装之中,我们必须确定SPARK_DIST_CLASSPATH这个环境变量的值,而这个值恰恰就是Hadoop目录中的classpath,因为这个原因,我在搭建的过程中吃了很多的苦,希望大家引以为戒。现在让我们准备一下安装spark的实验环境:
- Ubuntu Kylin16.04.4
- 安装java环境,在我的测试中最好使用jdk1.8及其以上的,或者openjdk8及其以上的,便于Scala安装;
- 安装ssh,无论单机还是集群,都最好安装;
- 搭建Hadoop集群,单机/伪分布式也可以;
- 安装Scala,我安装的是,要注意最新的版本不支持hadoop的最新版本,必须清楚;
- 安装spark3.0最新版本;
笔者安装得出的结论:
使用 Ubuntu16.04.4+(openjdk8/jdk1.8.x)+(scala2.11.x)+hadoop2.9.0+(spark2.3.0/spark2.2.1) 成功安装并可以运行;
二、开始安装
对于Hadoop集群的安装,大家可以查看我的《在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享》和《手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群》,其中有着详细的步骤和方法,建议最好直接就使用Ubuntu Kylin16.04.4,这样我们的版本就很同步了,其次,我的实验环境大部分都是最新环境或者次新环境,对于大家有着更好的借鉴意义,比如在这里我的JAVA版本使用的是JDK1.8或者openjdk-8-jdk,openjdk-8-jre,关于这两者的安装过程,大家可以查看我之前的博文,或者查看《》获得JDK1.8的安装过程;对于Hadoop集群,我用的是Hadoop2.9.0,已经是稳定版中的最新版了;对于Scala我使用的scala-2.11.12.tgz ,是仅次于最新版的版本,因为spark3.0只支持到这个版本,所以,我们不能使用scala的最新版本。这里假定我们已经安装了java,ssh,hadoop集群。
2.1、安装Scala
首先我们从官网下载相应的最高支持版本,在这里笔者下载的是Scala2.11.12,随着发展肯定会有更高的支持版本,读者注意使用。下载之后,我们看是解压,配置环境变量,然后使用。大家注意这里的一句话,那就是我们必须使用java 8及其以上版本的!
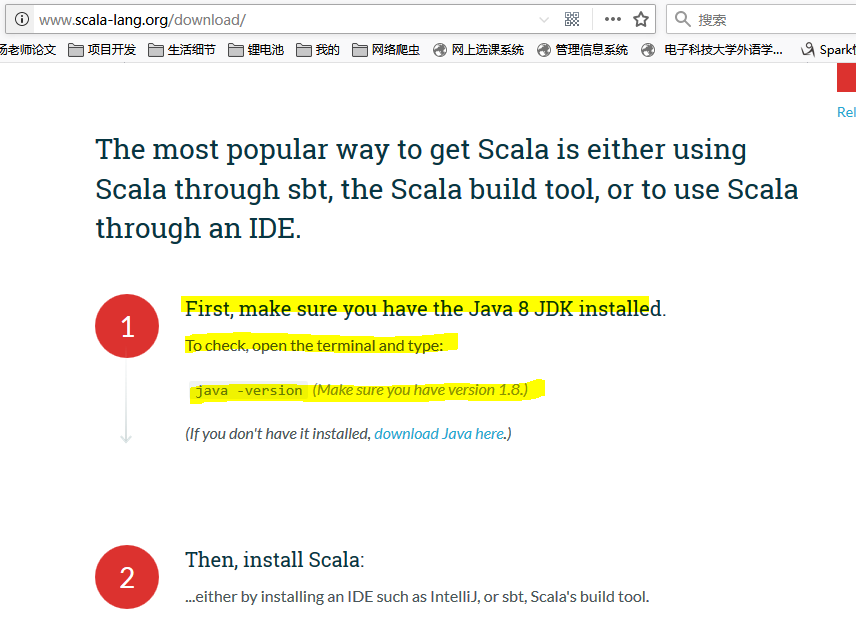
cd ~/Downloads ls #注意,这里解压的目录视情况而定,如果读者是新创建了一个用户,只供本用户使用,那么我建议存放在下面的目录,否则可以存放在/usr/local目录下! sudo tar -zxvf ./scala-2.11.12.tgz -C /home/grid/ #重命名 sudo mv ../scala-2.11.12 ../scala #修改权限 sudo chown -R grid:hadoop ../scala
#修改环境变量
sudo gedit ~/.bashrc
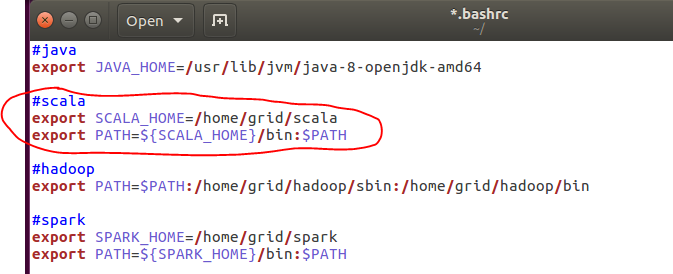
在.bashrc中,我们加入如下内容:
export SCALA_HOME=/home/grid/scala
export PATH=$PATH:$SCALA_HOME/bin
更新使环境变量生效:
source ~/.bashrc
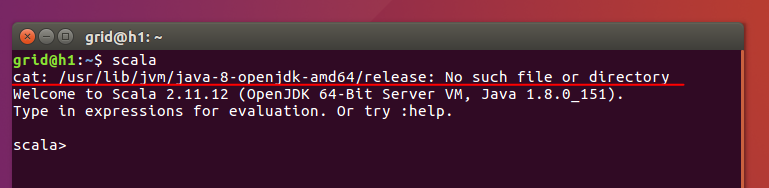
然后我们可以测试一下,注意到下图出现了cat找不到文件或目录,这就是使用openjdk8的弊端,所以建议大家最好使用jdk1.8版本。
scala
2.2、安装Spark
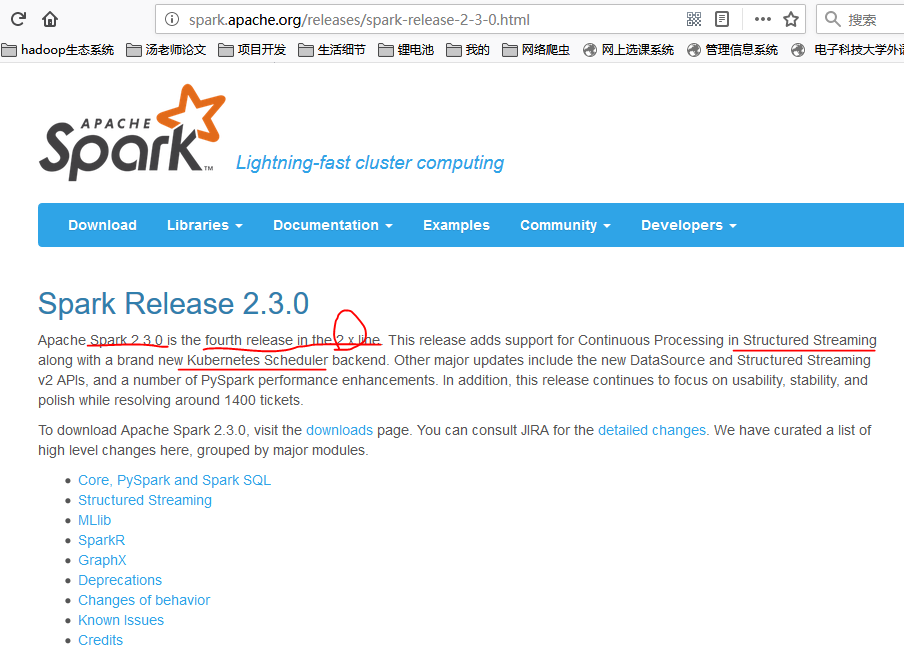
之后我们安装Spark,在这里有几个版本我们都可以用,比如说我尝试过spark-2.3.0-bin-without-hadoop.tgz和spark-2.2.1-bin-without-hadoop.tgz,在我们上面的配置中都没有问题。大家要学会查看官网上面的安装配置,比如spark2.3.0,里面就明确说过这一句话:
Spark runs on Java 8+, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.3.0 uses Scala 2.11.
You will need to use a compatible Scala version (2.11.x).
Note that support for Java 7, Python 2.6 and old Hadoop versions before 2.6.5 were removed as of Spark 2.2.0.
Support for Scala 2.10 was removed as of 2.3.0.
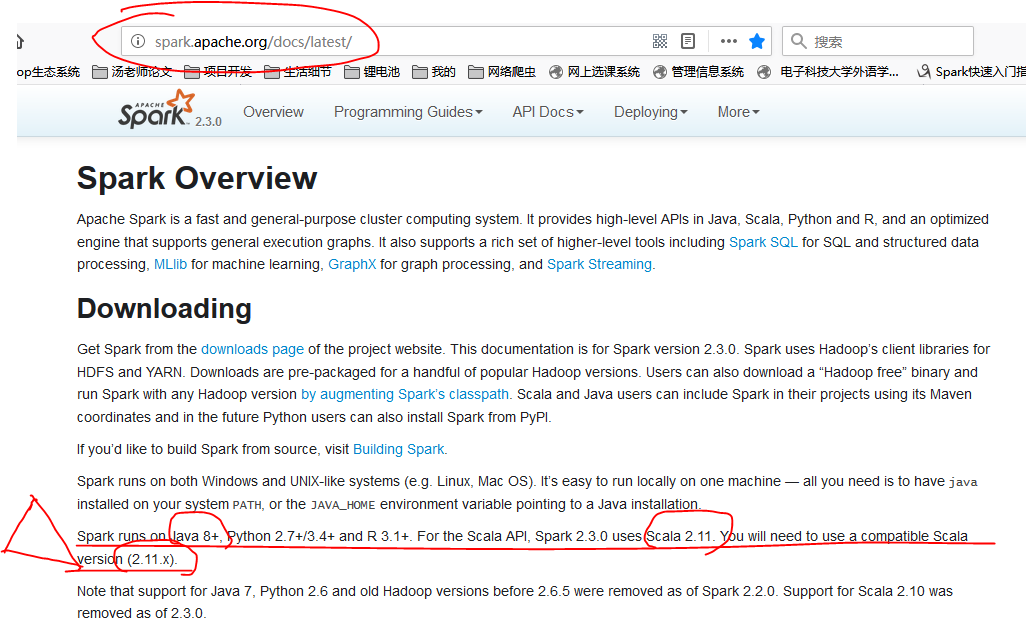
如果我们没有看到这句话,没有使用java 8+或者Scala2.11.x,那么失败是不可避免的,就算是安装成功了,在使用某个特殊的功能的时候还是会出现问题的。官网永远都是最值得我们去看的一手资料,有的内容适合于当时的版本,但是在新的版本中已经发生了质变,各种命名和习惯都不一样了,这个时候我们就不能按照原来的博客上说的来了,这点真的很重要,在下面我们也可以看到。
在这里,我们下载最新版本的spark-2.3.0-bin-without-hadoop.tgz,对于hadoop集群的任何版本都适合,这样我们就不用去纠结是不是版本不兼容的问题了,然后同样的我们需要解压,命名,修改权限,最后修改环境变量。
cd ~/Downloads
sudo tar -zxvf spark-2.3.0-bin-without-hadoop.tgz -C /home/grid/
sudo mv ../spark-2.3.0-bin-without-hadoop ../spark
sudo chown -R grid:hadoop ../spark
sudo gedit ~/.bashrc
在环境变量中加入:
export SPARK_HOME=/home/grid/spark
export PATH=$PATH:$SPARK_HOME/bin
然后修改使得环境变量生效:
source ~/.bashrc
有的教程中到了这一步就万事大吉了,直接去睡觉了,我真的很奇怪为什么有那么多不认真的人呢,因为这个原因,让我花了几乎一下午的时间去寻找原因,最终竟然发现是因为还没有配置完成而一直出现如下的报错,这个错误让我郁闷的吐血呀,网上很少有关于这个错误的解释的,就算是有也是词不达意,别的地方出现的,没办法,我开始想是不是因为我安装的是openjdk8而产生的?于是我卸载了这个版本,又下载了jdk1.8.x,结果问题依旧出现,再加上我的多次修改使得整个系统变得乱七八糟,后来我在想是不是因为我安装的spark2.3.0版本太高了,官方没有发现这个问题?结果我降低为2.2.1问题依旧出现,然后我在想是不是因为Scala和jdk的版本不匹配,为此我特意查了一下scala的官网,官网上明确指出需要jdk1.8及其以上的,我也是这样做的呀,百思不得其解,在网上找资料,还是没办法解决,当时的那种崩溃感真的是让人难以忍受呀,我们的时间都是宝贵的,所以我希望那些写博客的人至少要保持着对广大的看众负责的态度来写文章吧,不然的话就不要发表了,因为这真的是在浪费大家的时间同时也是在显示自己的弱智!好了,我就不再吐糟了,继续写下去,最终我在一个网站上发现了后续的安装步骤,总算是告别了这种困扰,根本就不是版本的问题。
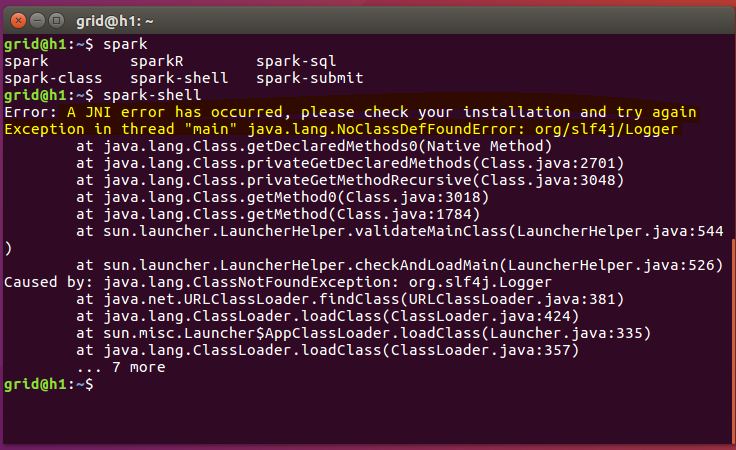
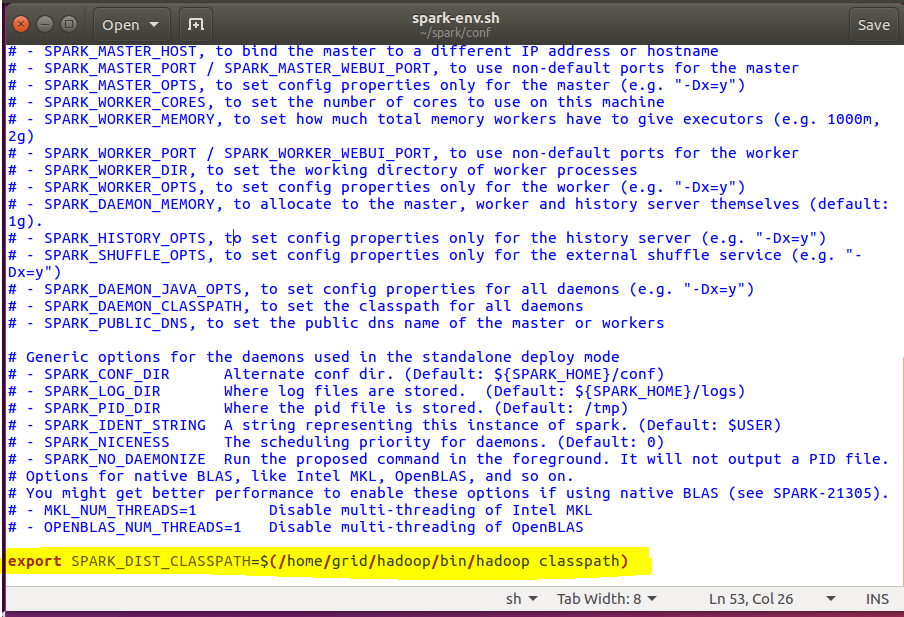
最重要的配置,继续配置环境变量:
接下来我们需要配置spark安装目录下的环境变量,在环境变量中和hadoop进行库文件的关联!
cd ~/spark/conf
sudo mv spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
在文件的结尾我们添加:
export SPARK_DIST_CLASSPATH=$(/home/grid/hadoop/bin/hadoop classpath)
然后我们在任意目录执行spark-shell看一下:
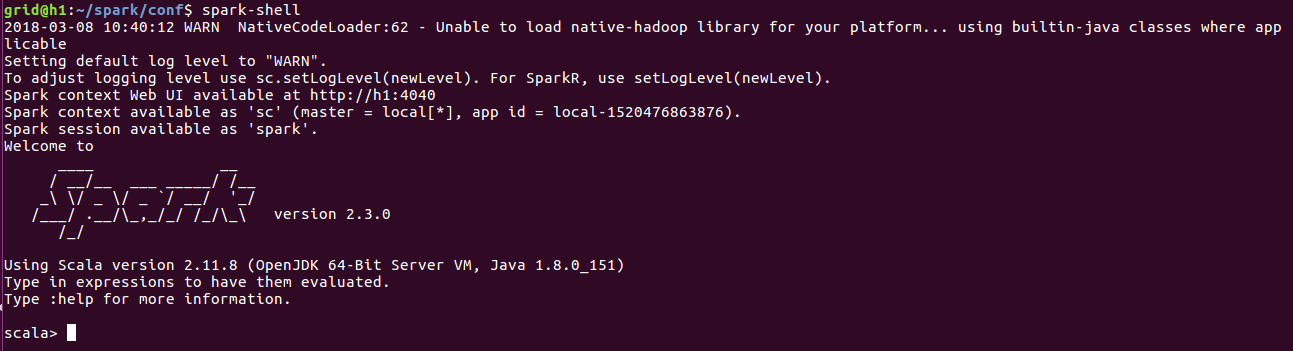
此时,我们的spark才算搭建完成,当然了我们还可以有更多的配置,比如说我们在刚刚的文件spark-env.sh中,我们还可以加入很多的描述信息和控制信息,在conf目录下还有很多的模板,我们都可以重命名之后拿来使用,这样我们的集群就更加有生命力了。在这里我们暂时不讨论spark和hadoop结合来运行程序,先让我们看一下spark在单机上的运行水平。
三、使用基本的spark命令
下面的内容大部分来自于官网,大家可以看一下,因为官网会根据不同的版本来变化,我现在的内容或者在您看的时候已经改变了很多。
3.1、创建数据集
Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets.
Let’s make a new Dataset from the text of the README file in the Spark source directory。
在这里我们不从hdfs上读取,而是直接从本地文件系统中读取,因此需要使用file协议。
val textFile = spark.read.textFile("file://home/grid/spark/README.md")// Number of items in this Dataset
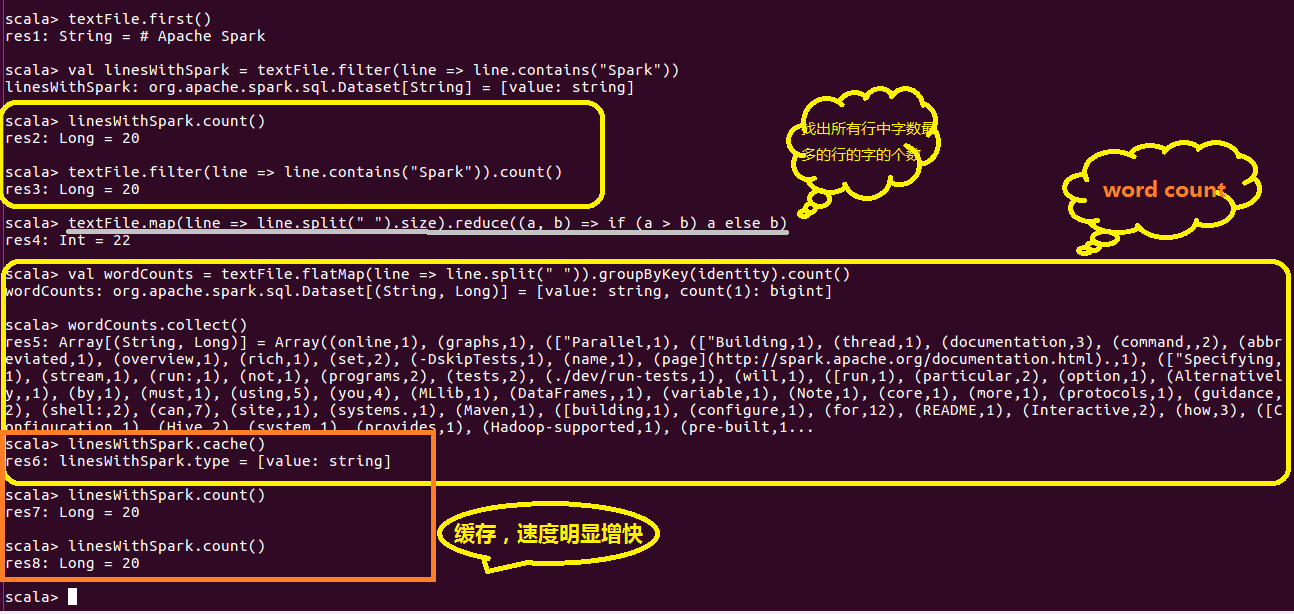
textFile.count()textFile.first() // First item in this Dataset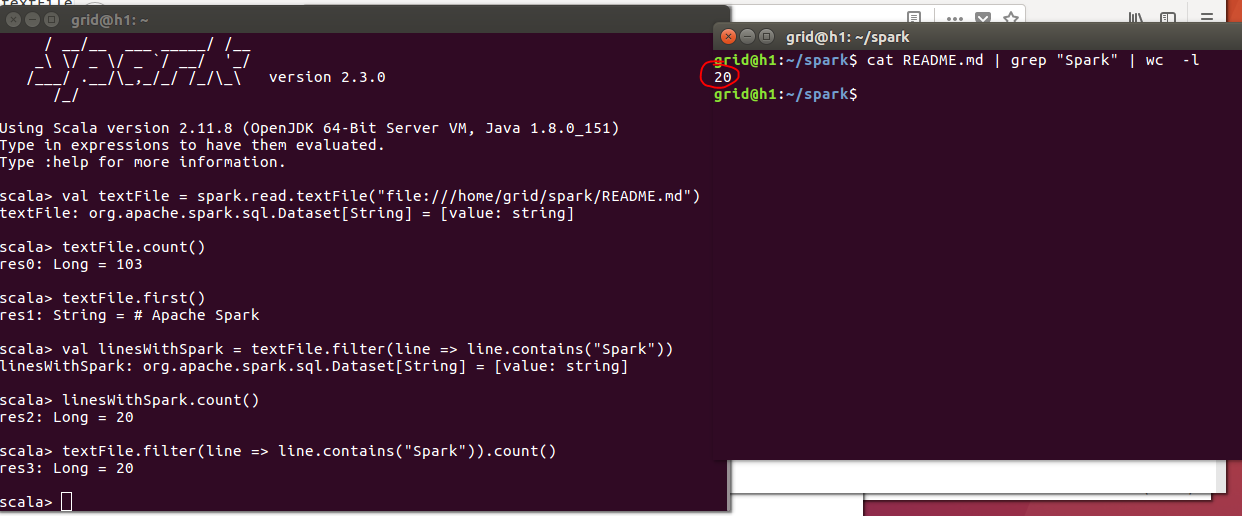
在spark-shell运行的过程中,我们也可以从网址http://h1:4040来查看运行的情况!
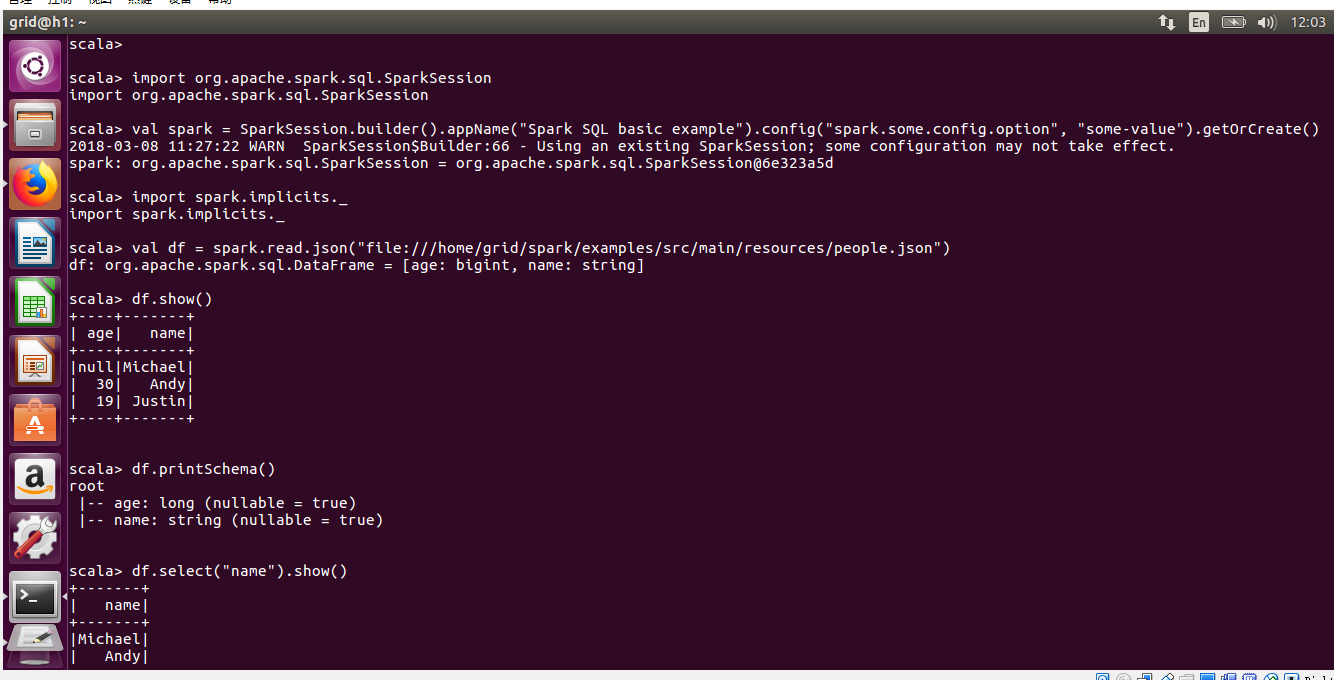
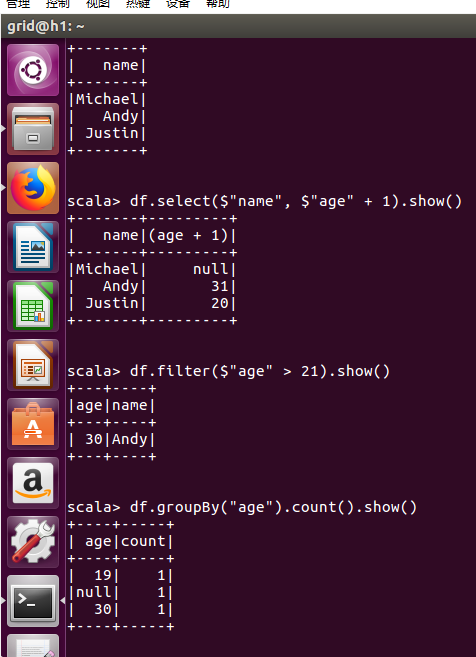
3.2、Spark SQL, DataFrames and Datasets Guide
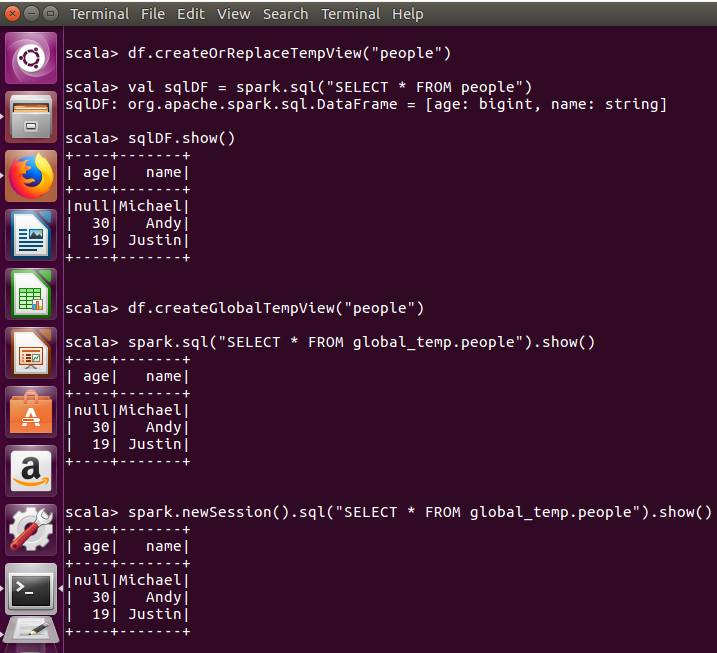
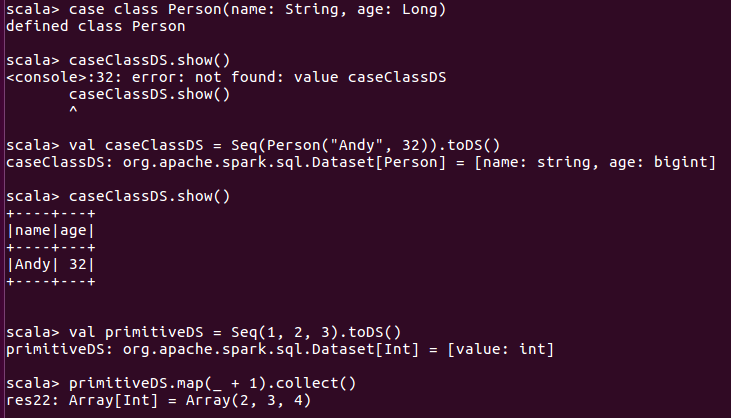
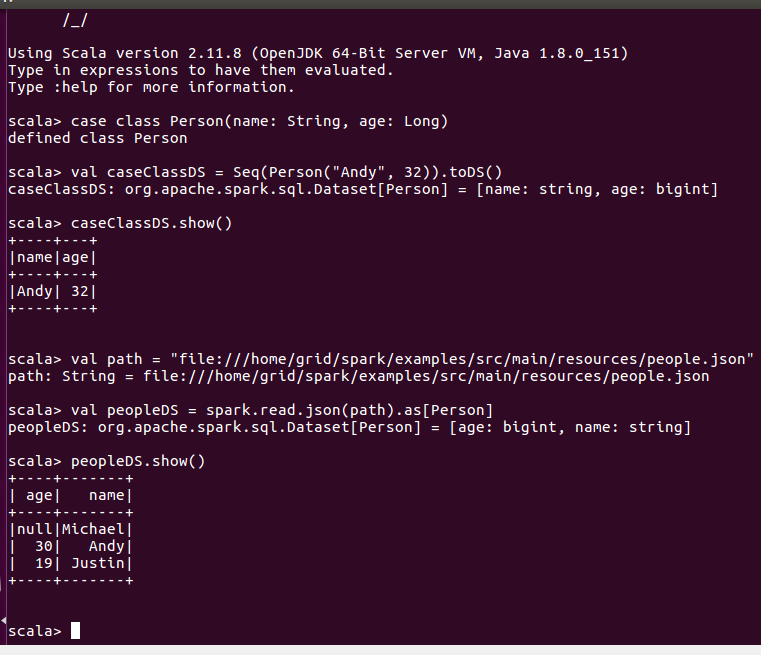
四、搭建完全分布式的spark系统
在上面的示例中我们其实并没有用到hdfs,换句话说,我们并没有实现分布式的spark架构,下面让我们继续进行配置完成分布式内存计算平台的搭建。
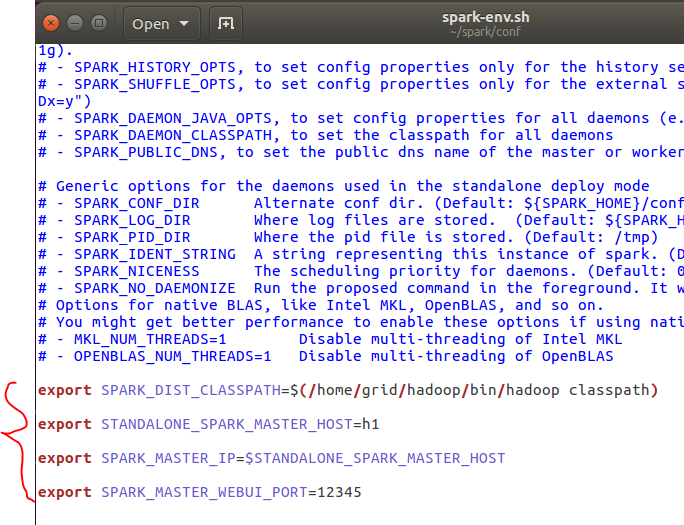
4.1、继续修改spark-env.sh文件
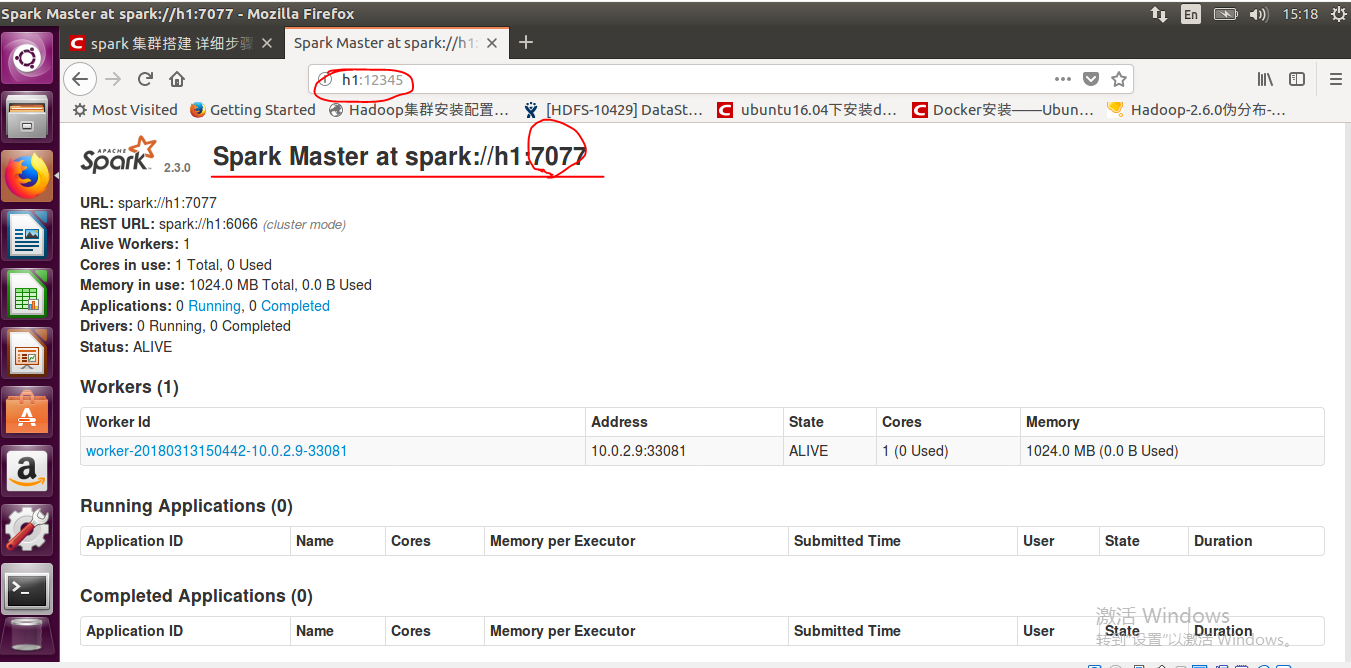
在该文件中,我们加入本机(主节点)的IP(主机名),然后配置一下web页面显示的端口,因为spark默认的是8080,可能被其他的程序占用,比如这里我们随意设定一个端口12345。
export SPARK_DIST_CLASSPATH=$(/home/grid/hadoop/bin/hadoop classpath)
export STANDALONE_SPARK_MASTER_HOST=h1
export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST
export SPARK_MASTER_WEBUI_PORT=12345
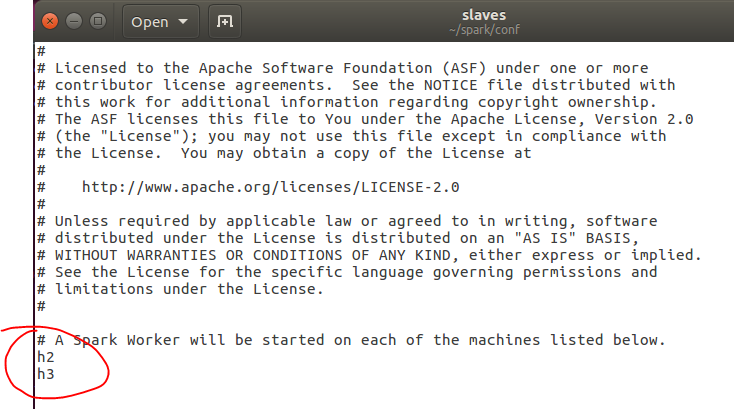
4.2、修改slaves文件
在这里首先我们将slaves.template复制为slaves,可以保留原来的文件,或者直接重命名。然后加入从节点(worker)
h2
h3
4.3、向其他节点复制并运行spark
保存之后,我们将这些文件复制到其他节点,使用scp命令,并且我们需要在其他节点的~/.bashrc中加入scala和spark的全局变量,这样我们的系统搭建算是告一段落了。
scp -r ~/scala grid@h2:/home/grid/
scp -r ~/spark grid@h2:/home/grid/
scp -r ~/scala grid@h3:/home/grid/
scp -r ~/spark grid@h3:/home/grid/
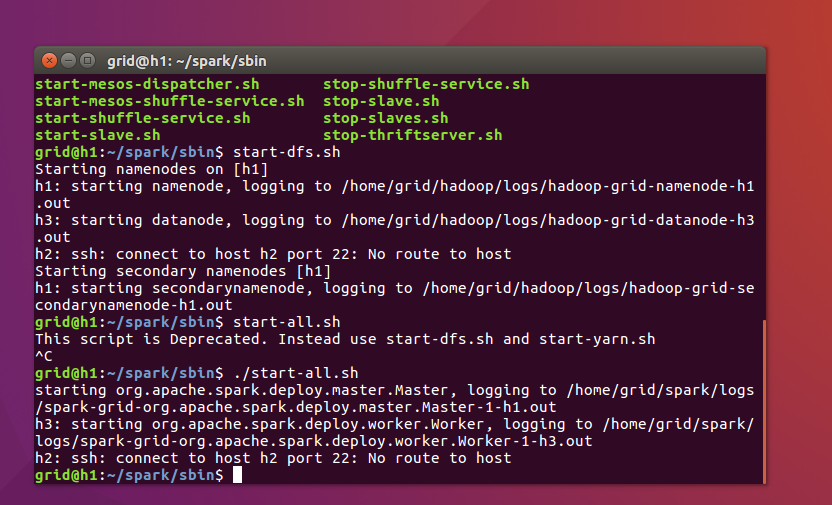
之后我们在主节点的spark目录下的sbin目录中使用如下命令来运行master和worker,注意在hdfs中我们就有start-all.sh,在这里我们作为区分直接使用:
./start-all.sh
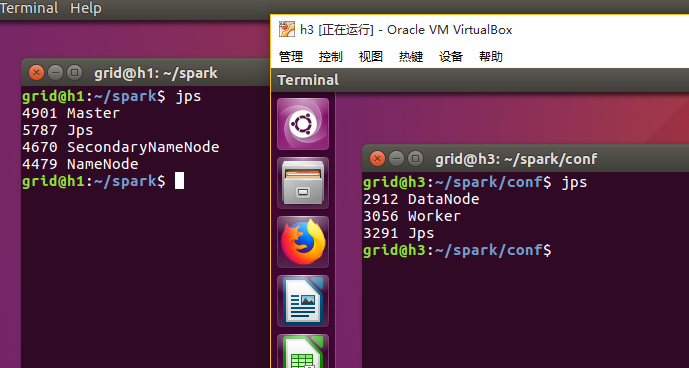
jps一下:
我们还可以使用h1:12345来访问我们的页面:
五、总结
关于spark的功能和各个模块,还有很多很多,我们可以参考官网的例子来尝试和学习,回想一下自己学习的方法确实有一些需要改进的,就比如说学习一个新知识,新东西,我习惯于从已有的别人的总结去找,而不习惯从官网上去查找,这一点是非常差的学习习惯,除此之外,我对于一些知识还是有一些遗忘和生疏的部分,对于Linux命令的掌握还是需要更加深刻和深入才行。同时也希望我的笔记能够帮助到有着同样需求的人!