1.Hibernate是什么
Hibernate是一款优秀的持久化ORM框架,解决持久化操作,使得程序员可以从编写繁复的JDBC工作中解放出来,专注于业务,提高程序员开发效率。并且具有可靠的移植性,降低了系统耦合度。
2.Hibernate入门案例
源码地址:https://github.com/zhongyushi-git/hibernate-collection.git。下载代码后,示例代码在hibernate-maven文件夹下。
1)新建一个普通的maven项目
2)导入依赖,本文采用hibernate5版本进行说明
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-agroal</artifactId>
<version>5.4.30.Final</version>
<type>pom</type>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.18</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
3)配置hibernate.cfg.xml
新建一个资源目录resources,在下面新建hibernate.cfg.xml,内容如下
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name="connection.url">jdbc:mysql://localhost:3306/hibernate</property> <property name="connection.driver_class">com.mysql.jdbc.Driver</property> <property name="connection.username">root</property> <property name="connection.password">zys123456</property> <!-- 方言--> <property name="dialect">org.hibernate.dialect.MySQL5Dialect</property>
<!-- 指定数据库的生成方式,update是当表存在时插入数据,表不存在时先创建表再插入数据-->
<property name="hibernate.hbm2ddl.auto">update</property>
</session-factory> </hibernate-configuration>
上述<session-factory>中指定了数据库的基本信息,包括url,driverClass,用户名及密码等。
4)新建实体类User
package com.zxh.entity; import lombok.Data; @Data public class User { private Integer id; private String name; private String password; }
5)创建数据库及表
create databse hebarnate;
6)在User类同级目录下新建User.hbm.xml用于进行映射
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate mapping DTD//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <!--数据库映射,package指定了实体类所在的包名--> <hibernate-mapping package="com.zxh.entity"> <!--表映射,name表示对象名,table表示表名--> <class name="User" table="t_user"> <!--主键,native是自增,assigned是不指定,自定义--> <id name="id"> <generator class="native"></generator> </id> <!--其他属性映射,name对象的属性,column表示数据库表的字段名称,当name和column时可省略--> <property name="name" column="name"></property> <property name="password"></property> </class> </hibernate-mapping>
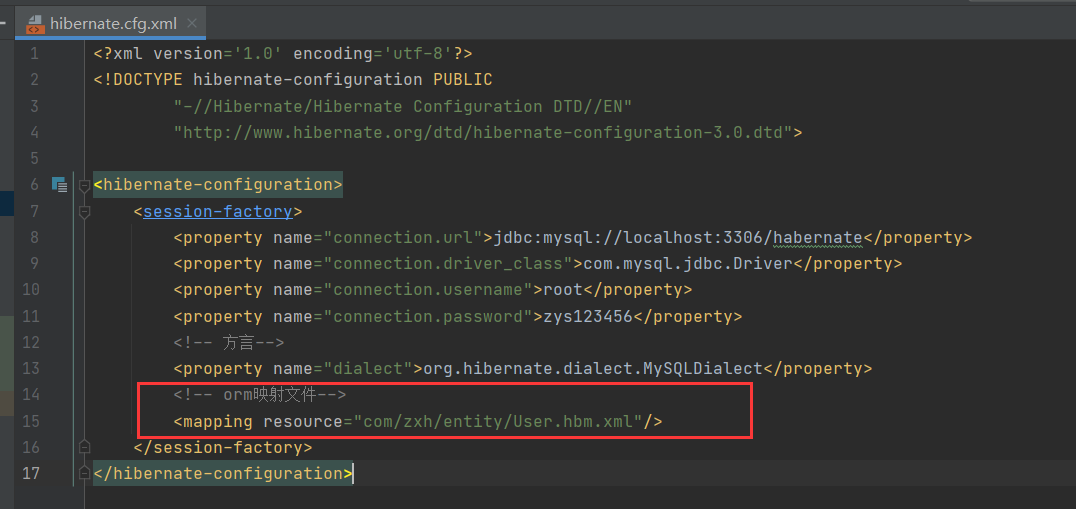
7)在hibernate.cfg.xml指定orm映射,指定hbm.xml位置
<!-- orm映射文件--> <mapping resource="com/zxh/entity/User.hbm.xml"/>
8)在pom.xml中读取配置文件
<build>
<!--读取配置文件-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering></resource>
</resources>
</build>
9)添加测试类并进行测试
@Test public void test1() { //初始化注册服务对象 final StandardServiceRegistry registry = new StandardServiceRegistryBuilder() .configure()//默认加载hibernate.cfg .xmL配置文件,如果配置文件名称被修改,configure("修改的名字") .build(); //从元信息获取session工厂 SessionFactory sessionFactory = new MetadataSources(registry) .buildMetadata() .buildSessionFactory(); //从工厂创建session连接 Session session = sessionFactory.openSession(); //开启事务 Transaction tx = session.beginTransaction(); //创建实例 User user = new User(); user.setName("zhangsan"); user.setPassword("123"); session.save(user); //提交事务 tx.commit(); //关闭 session.close(); }
执行测试方法成功后查看数据库,发现自动创建了表t_user并插入了一条数据。上述示例是添加数据,另外还有修改、删除和查询。
10)修改数据
添加一个测试方法,来修改上面添加的信息
@Test public void test2(){ //初始化注册服务对象 final StandardServiceRegistry registry = new StandardServiceRegistryBuilder() .configure()//默认加载hibernate.cfg .xmL配置文件,如果配置文件名称被修改,configure("修改的名字") .build(); //从元信息获取session工厂 SessionFactory sessionFactory = new MetadataSources(registry) .buildMetadata() .buildSessionFactory(); //从工厂创建session连接 Session session = sessionFactory.openSession(); //获取事务 Transaction tx = session.beginTransaction(); //创建实例 User user = new User(); user.setId(1); user.setName("王海红"); user.setPassword("9999"); //提交事务 session.update(user); tx.commit(); //关闭session session.close(); }
由代码可以看出,修改数据和添加数据是类型的,只是使用的方法不一样。
11)查询数据
添加一个测试方法,来查询上面修改的信息
@Test public void test3(){ //初始化注册服务对象 final StandardServiceRegistry registry = new StandardServiceRegistryBuilder() .configure()//默认加载hibernate.cfg .xmL配置文件,如果配置文件名称被修改,configure("修改的名字") .build(); //从元信息获取session工厂 SessionFactory sessionFactory = new MetadataSources(registry) .buildMetadata() .buildSessionFactory(); //从工厂创建session连接 Session session = sessionFactory.openSession(); User user = session.get(User.class, 1); System.out.println(user); //关闭session session.close(); }
这里查询是根据主键查询的单挑数据。在 Hibernate 中,除了使用 get() 方法加载数据以外,还可以使用 load() 方法加载数据,它们都能将数据从数据库中取出。两者的区别是使用 get() 方法加载数据时,如果指定的记录不存在,则返回 null;而使用 load() 方法加载数据时,如果指定的记录不存在,则会报出 ObjectNotFoundException 异常。
12)删除数据
添加一个测试方法,来删除上面修改的信息
@Test public void test4(){ //初始化注册服务对象 final StandardServiceRegistry registry = new StandardServiceRegistryBuilder() .configure()//默认加载hibernate.cfg .xmL配置文件,如果配置文件名称被修改,configure("修改的名字") .build(); //从元信息获取session工厂 SessionFactory sessionFactory = new MetadataSources(registry) .buildMetadata() .buildSessionFactory(); //从工厂创建session连接 Session session = sessionFactory.openSession(); //获取事务 Transaction tx = session.beginTransaction(); //创建实例进行查询 User user = session.get(User.class, 1); //删除 session.delete(user); //提交事务 tx.commit(); //关闭session session.close(); }
由代码可以看出,在删除时先根据条件去查询,查询后根据结果进行删除。
3.hibernate.cfg.xml介绍
3.1Hibernate配置文件
Hibernate中配置主要分为两种:
1)一种包含了Hibernate与数据库的基本连接信息,在Hibernate工作的初始阶段,这些信息被先后加载到Configuration和SessionFactory实例。(如hibernate.cfg.xml,说明见本章节)
2)另一种包含了Hibernate的基本映射信息,即系统中每一个类与其对应的数据库表之间的关联信息,在Hibernate工作的初始阶段,这些信息通过hibernate.cfg.xml的mapping节点被加载到Configuration和SessionFactory实例。(如User.hbm.xml,说明见下一章节)
3.2常用配置属性
配置文件在入门案例中,其常用属性说明如下表:
| 名 称 | 描 述 |
|---|---|
| hibernate.dialect | 操作数据库方言 |
| hibernate.connection.driver_class | 连接数据库驱动程序 |
| hibernate.connection.url | 连接数据库 URL |
| hibernate.connection.username | 数据库用户名 |
| hibernate.connection.password | 数据库密码 |
| hibernate.show_sql | 在控制台输出 SQL 语句,true时打印,默认是false |
| hibernate.format_sql | 格式化控制台输出的 SQL 语句,true时格式化,默认是false |
| hibernate.hbm2ddl.auto | 当 SessionFactory 创建时是否根据映射文件自动验证表结构或 自动创建、自动更新数据库表结构。推荐使用update参数 |
| hibernate.connection.autocommit | 事务是否自动提交 |
属性说明后下面进行详细的说明。
3.3数据库更新方式
在入门案例中,hibernate.cfg.xml中配置的hibernate.hbm2ddl.auto是update方式,其参数的作用是用于自动创建表或更新数据等。除此之外还有其他的几种方式,见下表
| 方式 | 说明 |
| update | 第一次加载时,数据库是没有表的,会先创建表,把数据插入,后面表存在时直接插入数据。推荐使用 |
| create |
每次执行前都先把原有数据表删除,然后创建该表,会导致数据库表数据丢失。不使用 |
| create-drop |
每次执行前都先把原有数据表删除,然后创建该表。关闭SessionFactory时,将删除掉数据库。不使用 |
| validate |
每次加载hibernate时,会验证创建数据库表结构,如果不一致就抛出异常,但是会插入新值。只会和数据库中的表进行比较,不会创建新表。不建议使用 |
3.4打印sql日志
在进行数据的操作时,我们并没有写sql语句,当想查看其执行的sql时,也是可以开启的。只需要的配置文件中开启sql并格式化sql即可,代码如下:
<!--打印sql--> <property name="show_sql">true</property> <!--格式化sql--> <property name="format_sql">true</property>
截图如下

再执行测试的方法,又添加了一条数据,控制台打印如下图
4.*.hbm.xml介绍
用于向 Hibernate 提供对象持久化到关系型数据库中的相关信息,每个映射文件的结构基本相同。通常和对象在同一目录下,前缀也一样,如User.hbm.xml,见入门案例配置。其首先进行了 xml 声明,然后定义了映射文件的 dtd 信息,然后后面是Hibernate 映射的具体配置。
4.1<hibernate-mapping> 元素
是映射文件的根元素,它所定义的属性在映射文件的所有节点都有效。其元素所包含的常用属性及其含义说明如下表所示。
| 属性名 | 是否必须 | 说 明 |
|---|---|---|
| package | 否 | 为映射文件中的类指定一个包前缀,用于非全限定类名 |
| schema | 否 | 指定数据库 schema 名 |
| catalog | 否 | 指定数据库 catalog 名 |
| default-access | 否 |
指定 Hibernate 用于访问属性时所使用的策略,默认为 property。 当 default-access="property" 时,使用 getter 和 setter 方法访问成员变量;当 default-access = "field"时,使用反射访问成员变量 |
| default-cascade | 否 | 指定默认的级联样式,默认为空 |
| default-lazy | 否 | 指定 Hibernate 默认所采用的延迟加载策略,默认为 true |
在User.hbm.xml中,使用package指定了实体类所在的包路径。
4.2<class> 元素
主要用于指定持久化类和数据表的映射关系,它是 XML 配置文件中的主要配置内容。其常用属性及其含义说明如下表 所示。
| 属性名 | 是否必须 | 说 明 |
|---|---|---|
| name | 否 | 持久化类或接口的全限定名。如果未定义该属性,则 Hibernate 将 该映射视为非 POJO 实体的映射 |
| table | 否 | 持久化类对应的数据库表名,默认为持久化类的非限定类名 |
| catalog | 否 | 数据库 catalog 名称,如果指定该属性,则会覆盖 hibernate-mapping 元素中指定的 catalog 属性值 |
| lazy | 否 | 指定是否使用延迟加载 |
在User.hbm.xml中,使用name指定了实体类是User,table指定了表名是t_user。
4.3<id>元素
用于设定持久化类的主键的映射,其常用属性及其含义说明如下表 所示。
| 属性名 | 是否必须 | 说 明 |
|---|---|---|
| name | 否 | 标识持久化类主键标识 |
| type | 否 | 持久化类中标识属性的数据类型。如果没有为某个属性显式设定映射类型,Hibernate 会运用反射机制先识别出持久化类的特定属性的 Java 类型,然后自动使用与之对应的默认 Hibernate 映射类型。若指定是引用数据类型,可省略。 |
| column | 否 | 设置标识属性所映射的数据列的列名(主键字段的名字),若列名与对象的属性名称一致,则可省略 |
| access | 否 | 指定 Hibernate 对标识属性的访问策略,默认为 property。若此处指定了该属性,则会覆盖 <hibemate-mapping> 元素中指定的 default-access 属性 |
除了上面4个元素以外,<id> 元素还可以包含一个子元素 <generator>。<generator> 元素指定了主键的生成方式。
对于不同的关系型数据库和业务应用来说,其主键的生成方式往往也不同,有的是依赖数据库自增字段生成主键,有的是按照具体的应用逻辑决定,通过 <generator> 元素就可以指定这些不同的实现方式。这些实现方式在 Hibernate 中,又称为主键生成策略。常用的策略有两种,一种是native,它是根据不同的数据库实现主键的自增;另一种是assigned,根据用户的需要自定义主键的值,也就是说在插入数据时需要指定主键的值;如果不指定 id 元素的 generator 属性,则默认使用assigned主键生成策略。
在User.hbm.xml中,id使用的是native,即使用数据库的自增特性,这里以mysql为例说明。
4.4<property>元素
<class> 元素内可以包含多个 <property> 子元素,它表示持久化类的其他属性和数据表中非主键字段的映射关系。常用属性及其含义说明如下表所示。
| 属性名 | 是否必须 | 说 明 |
|---|---|---|
| name | 是 | 持久化类属性的名称,以小写字母开头 |
| column | 否 | 数据表字段名(若列名与对象的属性名称一致,则可省略) |
| type | 否 | 数据表的字段类型(若指定是引用数据类型,可省略。) |
| length | 否 | 数据表字段定义的长度(未指定则使用数据库的默认长度) |
| lazy | 否 | 指定当持久化类的实例首次被访问时,是否对该属性使用延迟加载,其默认值是 false |
| unique | 否 | 是否对映射列产生一个唯一性约束。常在产生 DDL 语句或创建数据库对象时使用 |
| not-null | 是否允许映射列为空 |
5.整合log4j
当需要根据自己的需求打印日志时,可使用log4j进行自定义。在使用时,需先把配置文件hibernate.cfg.xml中的开启sql打印和格式化sql代码注释。
1)导入依赖
<!--添加s1f4j依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!--添加s1f4j-log4j转换包-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<!--添加log4j依赖-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2)新建log4j.properties
#控制台处理类
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
#控制台输出源布局layout
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd} %d{ABSOLUTE} %5p %c{1}:%L - %m%n
#文件处理类
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:/test/hibernate.log
#文件输出源布局layout
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd} %d{ABSOLUTE} %5p %c{1}:%L - %m%n
# 记录器 输出源 布局
log4j.rootLogger=warn,stdout,file
#记录hibernate参数
log4j.logger.org.hibernate.SQL=debug
#记录JDBC参数
log4j.logger.org.hibernate.type=info
#记录执行sQL的DDL语句
1og4j.logger.org.hibernate.tool.hbm2ddl=debug
3)测试。再次执行测试方法,看到有打印的信息。
5.Hibernate生命周期
5.1对象的状态
Hibernate中对象有三种状态:瞬时状态(Transient)、持久状态(Persistent)、游离状态(Detached)。
1)瞬时状态:刚刚使用new语句创建,还没有被持久化,不处于Session的缓存中。处于临时状态的Java对象被称为临时对象。Session中没有,数据库中没有。
2)持久化状态:已经被持久化,加入到Session的缓存中。处于持久化状态的Java对象被称为持久化对象。Session中有,数据库中有。
3)游离状态:已经被持久化,但不处于Session的缓存中。处于游离状态的Java对象被称为游离对象。Session中没有,数据库中有。
6.一级缓存
6.1概述
Hibernate 中的缓存分为一级缓存和二级缓存,这两个级别的缓存都位于持久化层,并且存储的都是数据库数据的备份。其中一级缓存是 Hibernate 的内置缓存,也叫做session缓存,属于事务范围的缓存,这一级别的缓存由 Hibernate 管理,一般情况下无须进行干预。其作用是减少数据库的访问次数。
hibernate在查询数据时,首先会使用对象的 OID 值在 Hibernate 的一级缓存中查找,如果找到匹配的对象,则直接将该对象从一级缓存中取出使用;如果没有找到匹配的对象,则会去数据库中查询对应的数据。当从数据库中查询到所需数据时,该数据信息会同步存储到一级缓存中,从而在下次查询同一个OID时就可直接从缓存中获取,不需要再次查询数据库。
6.2特点
1)当调用 Session 接口的 load()、get() 方法,以及 Query 接口的 list()、iterator() 方法时,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果缓存中没有要查询的对象,则再去数据库中查询对应对象,并添加到一级缓存中。
2)当应用程序调用 Session 接口的 save()、update()、saveOrUpdate() 时,如果 Session 缓存中没有相应的对象,则 Hibernate 就会自动把从数据库中查询到的相应对象信息加入到一级缓存中。
3)当调用 Session 的 close() 方法时,Session 缓存会被清空。
4)Session 能够在某些情况下,按照缓存中对象的变化,执行相关的 SQL 语句同步更新数据库,这一过程被称为刷出缓存(flush)。那么刷出缓存的几种情况如下:
A:当应用程序调用 Transaction 的 commit() 方法时,该方法先刷出缓存(调用 session.flush() 方法),然后再向数据库提交事务(调用 commit() 方法)
B:当应用程序执行一些查询操作时,如果缓存中持久化对象的属性已经发生了变化,会先刷出缓存,以保证查询结果能够反映持久化对象的最新状态。
C:调用 Session 的 flush() 方法。
6.3一级缓存示例
1)为了使用方便即代码的简洁,把创建session的代码封装为一个工具类
package com.zxh.util; import org.hibernate.Session; import org.hibernate.SessionFactory; import org.hibernate.boot.MetadataSources; import org.hibernate.boot.registry.StandardServiceRegistry; import org.hibernate.boot.registry.StandardServiceRegistryBuilder; /** * 工具类,用来创建session */ public class HibernateUtils { public static final StandardServiceRegistry registry; public static final SessionFactory sessionFactory; static { registry = new StandardServiceRegistryBuilder().configure().build(); sessionFactory = new MetadataSources(registry).buildMetadata().buildSessionFactory(); } public static Session getSession() { return sessionFactory.openSession(); } }
2)添加一个测试方法,对一条数据进行两次查询
@Test public void test5(){ Session session = HibernateUtils.getSession(); User user = session.get(User.class, 2); System.out.println(user); User user2 = session.get(User.class, 2); System.out.println(user2); //关闭session session.close(); }
控制台的打印结果如下图,根据下图可以看出,只执行了一次查询,第二次查询直接从缓存中获取了。

6.4快照技术
Hibernate 向一级缓存中存入数据的同时,还会复制一份数据存入 Hibernate 快照中。当调用 commit() 方法时,会清理一级缓存中的数据操作,同时会检测一级缓存中的数据和快照区的数据是否相同。如果不同,则会执行 update() 方法,将一级缓存的数据同步到数据库中,并更新快照区;反之,则不会执行 update() 方法。快照的作用就是保证缓存中的数据与数据库的数据保持一致。
且先看下面的示例:
@Test public void test6() { Session session = HibernateUtils.getSession(); User user = new User(); user.setName("李焕英"); user.setPassword("123456"); //向一级缓存中存入session对象 session.save(user); //重新设置值 user.setPassword("000000"); //提交事务 session.beginTransaction().commit(); //关闭session session.close(); }
运行的日志如下:

插入的数据查询如下:
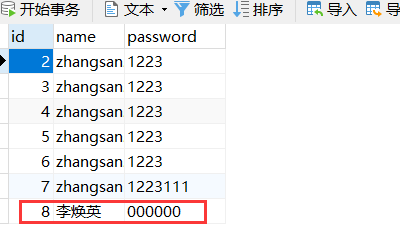
从这个sql的执行日志来看,首先把数据插入进去,然后根据id把password进行了修改,最终的数据便是数据库查询到的数据。其实这里就用到了快照技术。当设置对象后调用session.save()时,会把在一级缓存中和快照中各存一份User对象数据,此时两者的数据是一样的;但在提交事务之前,把User对象的password属性修改了,数据会同步到快照中;在提交事务时,先根据一级缓存的数据进行插入操作,于此同时会对比快照中的数据与一级缓存中的数据是否相同,由于两者的数据不同,就会执行update语句把一级缓存的数据更新并修改数据库的数据。
6.5一级缓存常用操作
1)刷出flush
一级缓存刷出功能是指在调用 Session 的 flush() 方法时让Session执行一些必须的SQL语句来把内存中的对象的状态同步到JDBC中,也就会执行update语句。在提交事务前,Hibernate 程序会默认先执行 flush() 方法。
且看代码:
@Test public void test7() { Session session = HibernateUtils.getSession(); session.beginTransaction(); User user = session.get(User.class, 8); //重新设置值 user.setPassword("9999"); //执行刷出操作 session.flush(); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
2)清除clear
在调用 Session 的 clear() 方法时,会清除缓存中的数据。
且看代码:
@Test public void test8() { Session session = HibernateUtils.getSession(); session.beginTransaction(); User user = session.get(User.class, 8); //重新设置值 user.setPassword("55555"); //清除缓存 session.clear(); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
执行后发现控制台只打印了查询的语句,并没有执行update语句,数据库的数据也没有发生变化。原因是在提交事务前,清除了缓存中的数据,就不会执行修改操作。
如果将上述方法中的 session.clear() 方法更改为 session.evict(user)方法,也可以实现同样的效果。这两个方法的区别是:clear() 方法是清空一级缓存中所有的数据,而 evict() 方法是清除一级缓存中的某一个对象。
3)刷新refresh
在调用 Session 的 refresh() 方法时,会重新查询数据库,并更新 Hibernate 快照区和一级缓存中的数据,让两者的数据保持一致。
且看代码:
@Test public void test9() { Session session = HibernateUtils.getSession(); session.beginTransaction(); User user = session.get(User.class, 8); //重新设置值 user.setPassword("55555"); //清除缓存 session.refresh(user); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
日志打印截图:

可以看出执行了两次的查询。第一次查询是指定的查询,第二次查询是由refresh执行的查询。查询后查看数据库,发现数据并没有发生变化,原因是在执行refresh后,会重新查询数据,并把数据给一级缓存和快照各一份,尽管在此之前快照中的值发生了变化,但此时仍然会被最新查询的数据覆盖,password由55555变成原来的9999。
7.二级缓存
7.1概述
二级缓存是SessionFactory 级别的缓存,它是属于进程范围的缓存,这一级别的缓存可以进行配置和更改,以及动态地加载和卸载,它是由 SessionFactory 负责管理的。
在访问指定的对象时,首先从一级缓存中查找,找到就直接使用,找不到则转到二级缓存中查找(必须配置和启用二级缓存)。如果在二级缓存中找到,就直接使用,否则会查询数据库,并将查询结果根据对象的 ID 放到一级缓存和二级缓存中。
7.2二级缓存分类
外置缓存(二级缓存)的物理介质可以是内存或硬盘,其分类如下表:
| 名称 | 说明 |
| Class Cache Region | 类级别的缓存。用于存储 PO(实体)对象 |
| Collection Cache Region | 集合级别的缓存。用于存储集合数据 |
| Query Cache Region | 查询缓存。缓存一些常用查询语句的查询结果 |
| Update Timestamps | 更新时间戳缓存。该区域存放了与查询结果相关的表在进行插入、更新或删除操作的时间戳,Hibernate 通过更新时间戳缓存区域判断被缓存的查询结果是否过期 |
7.3整合EHCache插件实现二级缓存
1)导入依赖
<!-- 二级缓存 EHcache -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-ehcache</artifactId>
<version>5.4.30.Final</version>
</dependency>
由于本文采用的是hibernate5,那么ehcache也要采用相同的版本才行,否则执行会报错,这是一个大坑!其他版本开启缓存的方式略有差别,请注意!
2)开启二级缓存
在核心配置文件中开启缓存,并指定使用缓存的类
<!-- 开启二级缓存-->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 开启查询缓存-->
<property name="hibernate.cache.use_query_cache">true</property>
<property name="hibernate.cache.region.factory_class">
org.hibernate.cache.ehcache.EhCacheRegionFactory
</property>
<!-- orm映射文件-->
<mapping resource="com/zxh/entity/User.hbm.xml"/>
<class-cache usage="read-write" class="com.zxh.entity.User"/>
上述标红的配置实际上在起那么已经存在了,这里只是说明其位置。也就是说<mapping>标签必须放到<property>标签后面,<class-cache> 标签必须放在 <mapping> 标签的后面。
<class-cache> 标签用于指定将哪些数据存储到二级缓存中,其中 usage 属性表示指定缓存策略。
3)创建测试类
@Test public void test10() { //开启第一个Session对象 Session session1 = HibernateUtils.getSession(); // 开启第一个事务 Transaction tx1 = session1.beginTransaction(); // 获取对象 User p1 = session1.get(User.class, 8); User p2 = session1.get(User.class, 8); // 第一次比较对象是否相同 System.out.println(p1 == p2); // 提交事务 tx1.commit(); //session1对象关闭,一级缓存被清理 session1.close(); // 开启第二个Session对象 Session session2 = HibernateUtils.getSession(); // 开启第二个事务 Transaction tx2 = session2.beginTransaction(); // 获取对象 User p3 = session2.get(User.class, 8); // 第二次比较 System.out.println(p1 == p3); User p4 = session2.get(User.class, 8); // 第三次比较 System.out.println(p3 == p4); // 提交事务2 tx2.commit(); // session2关闭 session2.close(); }
执行后控制台只执行了一次查询,打印的结果分别是true,false,true。
4)代码执行分析
第一步:从第一个 Session 中获取 p1 对象时,由于一级缓存和二级缓存中没有相应的数据,需要从数据库中查询,所以执行了一次查询。
第二步:查询出 p1 对象后,p1 对象会保存到一级缓存和二级缓存中。在获取p2对象时,Session 并没有关闭,由于一级缓存中已存在对应的数据,则直接从缓存中获取,并不会去数据库查询;由于 p1 和 p2 对象都保存在一级缓存中,而且指向的是同一实体对象,所以p1和p2是一样的。
第三步:提交事务 tx1并关闭 session1,此时一级缓存中的数据会被清除。
第四步:开启第二个 Session 和事务,获取 p3 对象,此时 p3 对象是从二级缓存中获取的。取出后,二级缓存会将数据同步到一级缓存中,这时 p3 对象又在一级缓存中存在了。
第五步:二级缓存中存储的都是对象的散装数据,它们会重新 new 出一个新的对象,所以p1和p3指向的地址不同。
第六步:获取 p4 对象时,Session 并没有关闭,由于一级缓存中已存在对应的数据,则直接从缓存中获取,故p3和p4是一样的,其原理同p1与p2。
8.Hibernate多表操作
在前面的操作中,都是对单表进行操作。除此之外,还有多表的关联关系,它们的关系分别有一对一、一对多、多对多。
8.1一对多映射
8.1.1一对多关系
一对多映射关系是由“多”的一方指向“一”的一方。在表示“多”的一方的数据表中增加一个外键,指向“一”的一方的数据表的主键,“一”的一方称为主表,而“多”的一方称为从表。
比如班级和学生关系,一个班级中有多个学生,但是一个学生只属于一个班级,就属于一对多的关系(一个班级对应多个学生)
8.1.2 实战演练
1)新建班级类Clazz
package com.zxh.entity; import lombok.Data; import lombok.experimental.Accessors; import java.util.HashSet; import java.util.Set; @Data @Accessors(chain = true) public class Clazz { private Integer id; private String name; private Set<Student> students = new HashSet<>(); }
其中 students 是一个集合对象,用于存储一个班级的学生。
2)新建学生类Student
package com.zxh.entity; import lombok.Data; import lombok.experimental.Accessors; @Data @Accessors(chain = true) public class Student { private Integer id; private String name; private Clazz clazz; }
其中 clazz是一个 Clazz类型的对象,用于表示该学生属于某一个班级。
3)新建Clazz.hbm.xml
在Clazz同级目录下新建Clazz.hbm.xml,内容如下:
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate mapping DTD//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <!--数据库映射,package指定了实体类所在的包名--> <hibernate-mapping package="com.zxh.entity"> <!--表映射,name表示对象名,table表示表名--> <class name="Clazz" table="t_clazz"> <!--主键自增--> <id name="id"> <generator class="native"></generator> </id> <property name="name" length="100"></property> <!-- 一对多的关系使用set集合映射 --> <set name="students"> <!-- 指定映外键的列名 --> <key column="cid" foreign-key="cid"/> <!-- 指定映射的类,指向多的一方 --> <one-to-many class="Student"/> </set> </class> </hibernate-mapping>
在一对多的关系中,使用<set>标签进行关系的映射。其name表示对象的属性名,里面包含两个标签。<key>用于指定外键,colmun指定外键的列名,foreign-key指定外键名称(若不指定,则使用默认策略生成外键名称,若指定,主键名称 不能重复)。<one-to-many> 标签描述持久化类的一对多关联,指向多的一方的类。
4)新建Student.hbm.xml
在Student同级目录下新建Student.hbm.xml,内容如下:
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate mapping DTD//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <!--数据库映射,package指定了实体类所在的包名--> <hibernate-mapping package="com.zxh.entity"> <!--表映射,name表示对象名,table表示表名--> <class name="Student" table="t_student"> <!--主键自增--> <id name="id"> <generator class="native"></generator> </id> <property name="name" length="50"></property> <!-- 多对一关系映射,指向一的一方 --> <many-to-one name="clazz" class="Clazz" column="cid"></many-to-one> </class> </hibernate-mapping>
<many-to-one> 标签定义了三个属性,分别是 name、class 和 column 属性。其中,name 属性表示 Student 类中的 clazz属性名称,class 属性表示指定映射的类,column 属性表示表中的外键类名。需要注意的是,该 column 属性与 Clazz.hbm.xml 映射文件的 <key> 标签的 column 属性要保持一致。
5)核心配置文件指定xml位置
在hibernate.cfg.xml配置
<mapping resource="com/zxh/entity/Clazz.hbm.xml"/> <mapping resource="com/zxh/entity/Student.hbm.xml"/>
6)创建测试方法
为了代码的结构清晰,这里再新建一个测试类MyTest2,添加一个测试方法
@Test public void test1() { Session session = HibernateUtils.getSession(); session.beginTransaction(); Clazz clazz = new Clazz(); clazz.setName("计算机1班"); //学生属于某个班级 Student student1 = new Student().setName("蔡敏敏").setClazz(clazz); Student student2 = new Student().setName("李明").setClazz(clazz); //班级里有多个学生 clazz.getStudents().add(student1); clazz.getStudents().add(student2); //保存数据 session.save(clazz); session.save(student1); session.save(student2); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
运行测试方法,会发现发生了异常,如下图:
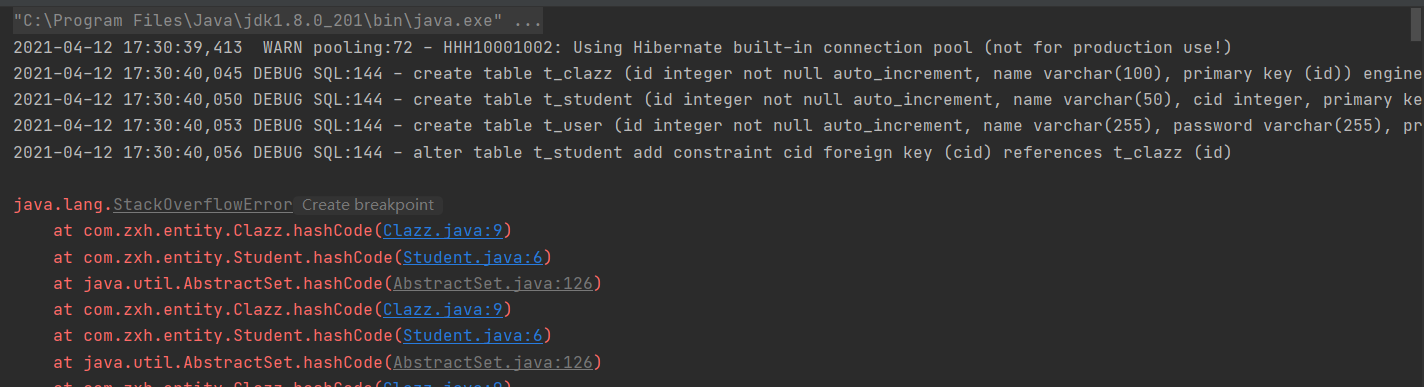
根据打印的结果来看,表已经创建成功了,在插入数据时出现的异常。这也是一个坑,原因是在实体类上使用了lombok的@Data注解,其toString()方法会去调用本类属性的其他对象的toString()方法。Clazz调用Student的toString(),Studen又调用Clazz的toString(),这样就陷入了死循环,导致栈溢出。解决办法是不使用@Data注解,改使用@Getter和@Setter注解。当两个实体都注解修改后,删除两个表,再次运行,发现执行成功,如下图: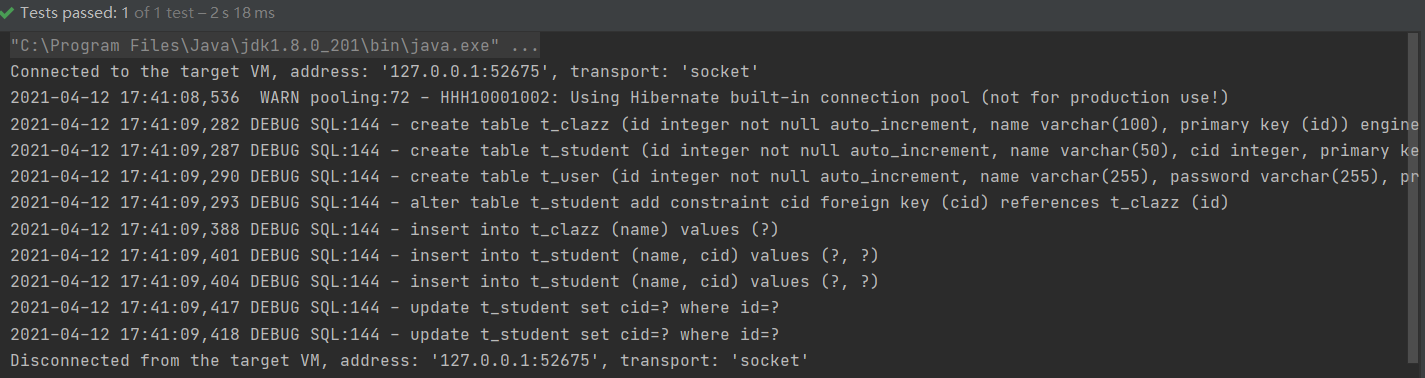
数据库的数据如下图:
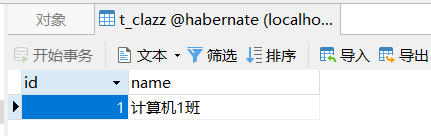
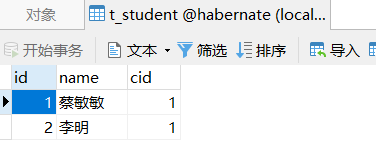
如果需要使用上述两个对象的toString()方法,那么只需要给其加上@toString注解即可。这样使用三个注解来替换@Data可以完美的解决上述的异常。
8.2多对多映射
8.2.1多对多关系
多对多的关系都会产生一张中间表。比如学生和学科关系,一个学生可以选择多个学科,一个学科可以被多个学生选择。
8.2.2 实战演练
1)新建学生类Stud
为了和一对多的代码进行区分,这里学生类使用Stud
package com.zxh.entity; import lombok.Getter; import lombok.Setter; import lombok.ToString; import lombok.experimental.Accessors; import java.util.HashSet; import java.util.Set; @Setter @Getter @ToString @Accessors(chain = true) public class Stud { private Integer id; private String name; private Set<Course> courses = new HashSet<>(); }
其中 courses是一个集合对象,用于存储选择的学科。
2)新建学科类Course
package com.zxh.entity;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import lombok.experimental.Accessors;
import java.util.HashSet;
import java.util.Set;
@Setter
@Getter
@ToString
@Accessors(chain = true)
public class Course {
private Integer id;
private String name;
private Set<Stud> students = new HashSet<>();
}
其中 students是一个集合对象,用于存储选择学科的学生。
3)新建Stud.hbm.xml
在Stud同级目录下新建Stud.hbm.xml,内容如下:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!--数据库映射,package指定了实体类所在的包名-->
<hibernate-mapping package="com.zxh.entity">
<!--表映射,name表示对象名,table表示表名-->
<class name="Stud" table="t_stud">
<!--主键自增-->
<id name="id">
<generator class="native"></generator>
</id>
<property name="name" ></property>
<!-- 多对多的关系使用set集合映射 -->
<set name="courses" table="stu_course">
<!-- 指定映外键的列名 -->
<key column="sid"/>
<!-- 指定映射的类,指向指向对方 -->
<many-to-many class="Course" column="cid"/>
</set>
</class>
</hibernate-mapping>
对比一对多的关系,<set>标签中多了一个table属性,用来指定中间表的表名称。<many-to-many> 标签表示两个持久化类多对多的关联关系,其中 column 属性指定 course 表在中间表中的外键名称。Stud指向Course类,其在中间表的列名是cid。
4)新建Course.hbm.xml
在Course同级目录下新建Course.hbm.xml,内容如下:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!--数据库映射,package指定了实体类所在的包名-->
<hibernate-mapping package="com.zxh.entity">
<!--表映射,name表示对象名,table表示表名-->
<class name="Course" table="t_course">
<!--主键自增-->
<id name="id">
<generator class="native"></generator>
</id>
<property name="name" ></property>
<!-- 多对多的关系使用set集合映射 -->
<set name="students" table="stu_course">
<!-- 指定映外键的列名 -->
<key column="cid"/>
<!-- 指定映射的类,指向对方 -->
<many-to-many class="Stud" column="sid"/>
</set>
</class>
</hibernate-mapping>
<set>标签中table属性用来指定中间表的表名称。<many-to-many> 标签表示两个持久化类多对多的关联关系,其中 column 属性指定 Stud表在中间表中的外键名称。Course指向Stud类,其在中间表的列名是sid。
5)核心配置文件指定xml位置
在hibernate.cfg.xml配置
<mapping resource="com/zxh/entity/Stud.hbm.xml"/>
<mapping resource="com/zxh/entity/Course.hbm.xml"/>
6)创建测试方法
在测试类MyTest2中添加一个测试方法
@Test public void test2() { Session session = HibernateUtils.getSession(); session.beginTransaction(); //学生 Stud student1 = new Stud().setName("蔡敏敏"); Stud student2 = new Stud().setName("李明"); //学科 Course course = new Course().setName("java 基础"); Course course2 = new Course().setName("NySQL 基础"); //学生关联科目 student1.getCourses().add(course); student1.getCourses().add(course2); student2.getCourses().add(course); student2.getCourses().add(course2); //保存数据 session.save(course); session.save(course2); session.save(student1); session.save(student2); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
运行测试方法,执行成功,如下图
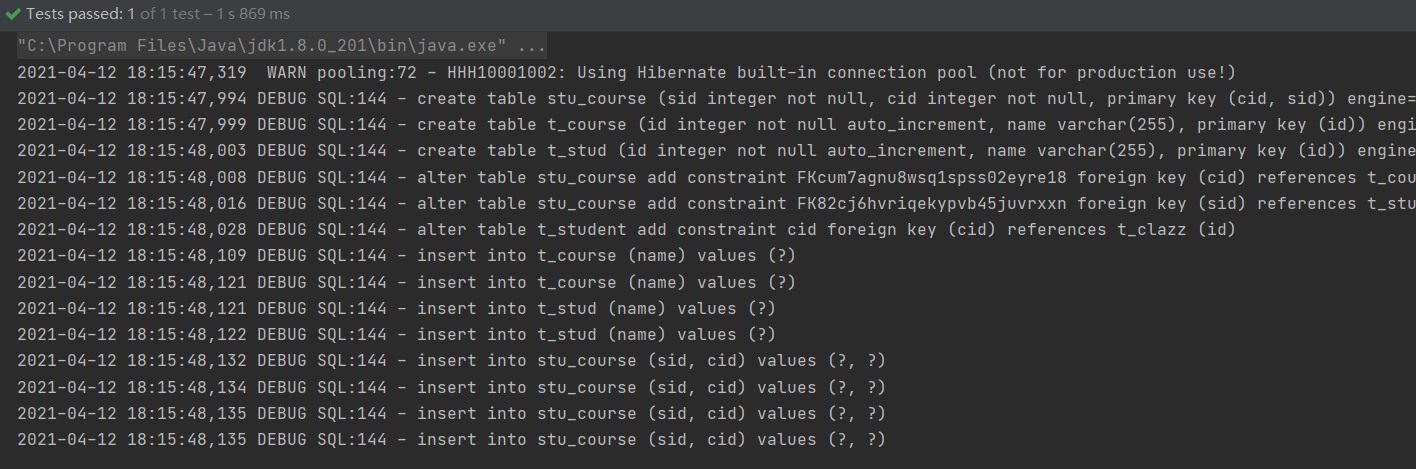
数据库数据如下图:
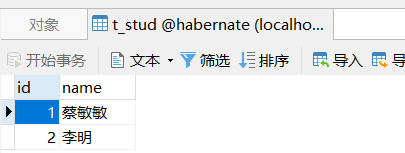
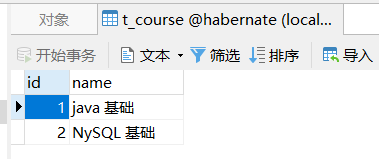

上述测试代码中,首先创建两个学生对象和两门课程对象,然后用学生对科目进行关联,这是多对多的单向关联。
8.3反转(inverse)
8.3.1概述
在映射文件的 <set> 标签中,inverse(反转)属性的作用是控制关联的双方由哪一方管理关联关系。
inverse 属性值是 boolean 类型的,当取值为 false(默认值)时,表示由当前这一方管理双方的关联关系,如果双方 inverse 属性都为 false 时,双方将同时管理关联关系;取值为 true 时,表示当前一方放弃控制权,由对方管理双方的关联关系。
通常情况下,在一对多关联关系中,会将“一”的一方的 inverse 属性取值为 true,即由“多”的一方维护关联关系,否则会产生多余的 SQL 语句;而在多对多的关联关系中,任意设置一方的 inverse 属性为 true 即可。
8.3.2实战演练
1)新建一个测试方法test3,对test2方法添加课程对学生的关联
@Test public void test3() { Session session = HibernateUtils.getSession(); session.beginTransaction(); //学生 Stud student1 = new Stud().setName("张三丰"); Stud student2 = new Stud().setName("赵虎义"); //学科 Course course = new Course().setName("redis 基础"); Course course2 = new Course().setName("java框架"); //学生关联科目 student1.getCourses().add(course); student1.getCourses().add(course2); student2.getCourses().add(course); student2.getCourses().add(course2); //科目关联学生 course.getStudents().add(student1); course.getStudents().add(student2); course2.getStudents().add(student1); course2.getStudents().add(student2); //保存数据 session.save(course); session.save(course2); session.save(student1); session.save(student2); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
2)执行后代码报错,显示主键重复。这是因为在双向关联中会产生一张中间表,关联双方都向中间表插入了数据。
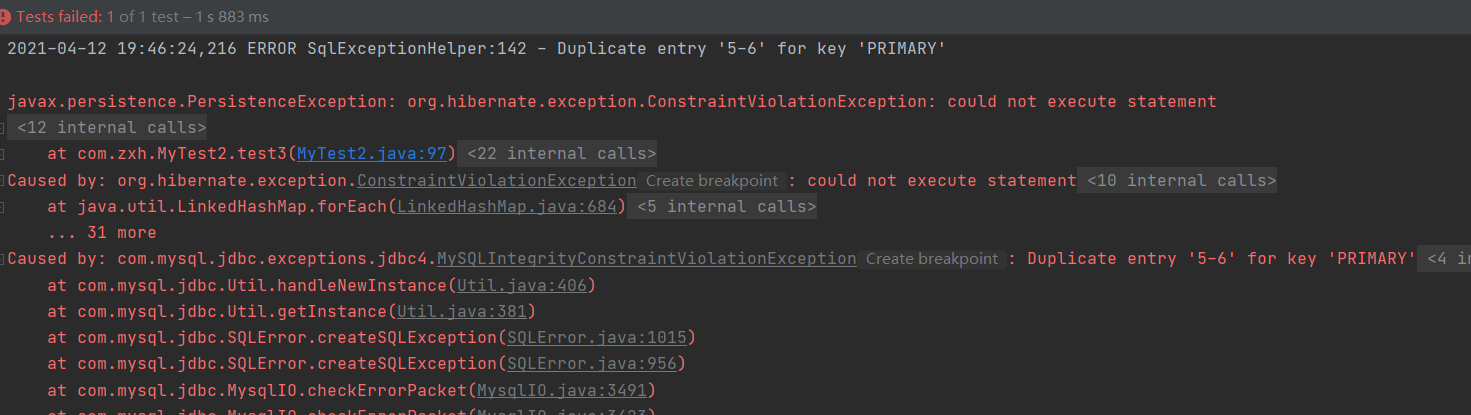
通常情况下,这种问题有两种解决方案:第一种是进行单向关联(即最初的代码test2方法中的代码),第二种是在一方的映射文件中,将 <set> 标签的 inverse 属性设置为 true。
3)在 Course.hbm.xml 映射文件的 <set> 标签中,添加 inverse 属性,并将其属性值设置为 true
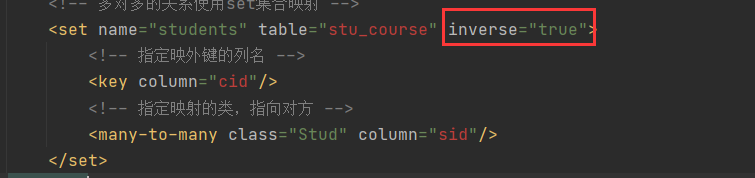
再次执行test3方法,运行成功,数据正常插入进去。
4)注意点:inverse 只对 <set>、<one-to-many> 和 <many-to-many> 标签有效,对 <many-to-one> 和 <one-to-one> 标签无效。
8.4级联(cascade)
8.4.1概述
级联操作是指当主控方执行任意操作时,其关联对象也执行相同的操作,保持同步。在映射文件的 <set> 标签中有个 cascade 属性,该属性用于设置是否对关联对象采用级联操作。其常用属性如下表所示:
| 属性值 | 描 述 |
|---|---|
| save-update | 在执行 save、update 或 saveOrUpdate 吋进行关联操作 |
| delete | 在执行 delete 时进行关联操作 |
| delete-orphan | 删除所有和当前解除关联关系的对象 |
| all | 所有情况下均进行关联操作,但不包含 delete-orphan 的操作 |
| all-delete-orphan | 所有情况下均进行关联操作 |
| none | 所有情况下均不进行关联操作,这是默认值 |
一对多的关系还是以班级和学生进行说明,新建一个测试类MyTest3,下面的级联操作均在此测试类进行。
8.4.2一对多级联添加
1)新建一个方法test1
@Test public void test1(){ Session session = HibernateUtils.getSession(); session.beginTransaction(); // 创建一个班级 Clazz clazz = new Clazz(); clazz.setName("计算机二班"); // 创建一个学生 Student student = new Student(); student.setName("王五"); clazz.getStudents().add(student); // 班级关联学生 session.save(clazz); session.getTransaction().commit(); session.close(); }
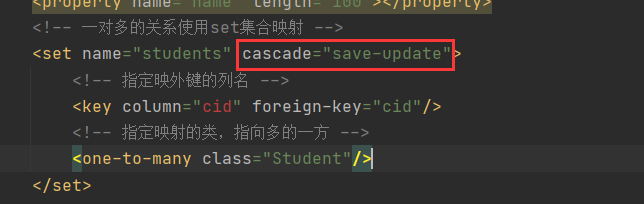
2)修改Clazz.hbm.xml
把<set>标签的cascade 的属性值设置为 save-update
3)运行测试方法,日志截图

查看数据库,数据如下:
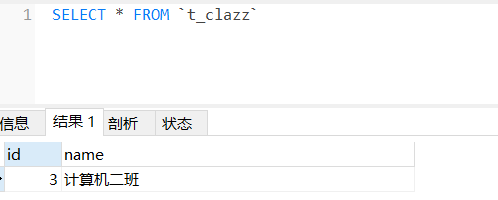
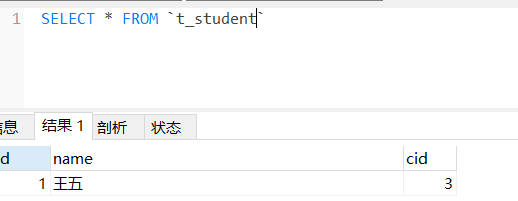
对比上述8.1.2小节的代码可以看出,这里的测试方法并没有写保存学生的代码,由级联操作自动去执行。
8.4.3一对多级联删除
在班级和学生的关联关系中,如果使用级联删除了班级,那么该班级对应的学生也会被删除。
1)先看不使用级联删除班级信息的效果。新建test2,用于删除班级信息
@Test public void test2(){ Session session = HibernateUtils.getSession(); session.beginTransaction(); Clazz clazz = session.get(Clazz.class,3); session.delete(clazz); session.getTransaction().commit(); session.close(); }
2)执行后日志截图如下。从日志可以看出,在删除时,先修改了学生的外键值为null,再删除了班级信息。数据库查询也是如此,也就是说删除看班级信息,但对应的学生信息并没有删除,只是将其班级id置为null而已。

3)如果需要在删除班级的同时删除学生信息,就需要使用级联操作。只需要在 Clazz.hbm.xml 映射文件的 <set> 标签中,将 cascade 属性值设置为 delete 即可。在设置之前,先执行test1方法把数据再次插入进去,然后把cascade 值设置为delete,

4)在插入数据后,根据id修改test2方法中的查询条件(现在插入的班级id是4),再次执行test2方法,日志截图:
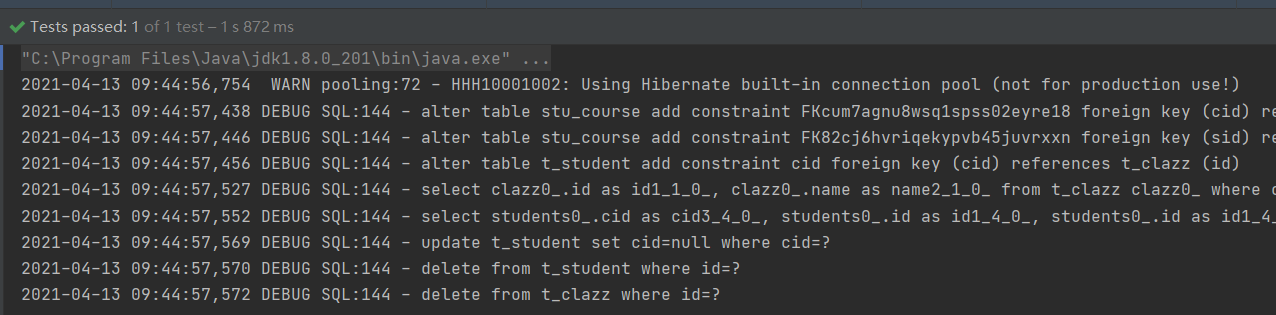
执行后对应的数据已经删除成功了。看到日志发现,它还是先把学生的外键置为null,然后根据主键id进行删除。
8.4.4孤儿删除
孤儿的意思是如果解除了外键的关联关系,那么没有外键的一方就是孤儿。要想删除这些数据,也是可以的,那么这种删除就叫孤儿删除。
1)先修改cascade="save-update"执行test1方法把数据再次插入进去
2)新建测试方法test3,先查询数据,然后解除关联关系,再删除班级信息
@Test public void test3() { Session session = HibernateUtils.getSession(); session.beginTransaction(); Clazz clazz = session.get(Clazz.class, 6); Student student = session.get(Student.class, 3); //解除关联关系 clazz.getStudents().remove(student); session.delete(clazz); session.getTransaction().commit(); session.close(); }
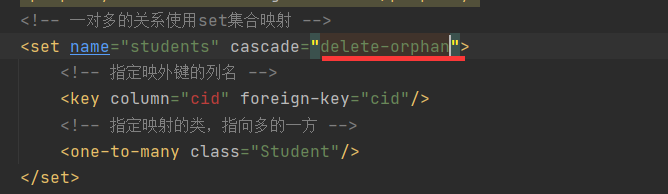
3)在 Clazz.hbm.xml 映射文件的 <set> 标签中,将 cascade 属性值设置为 delete-orphan
4)运行test3方法,日志截图如下:
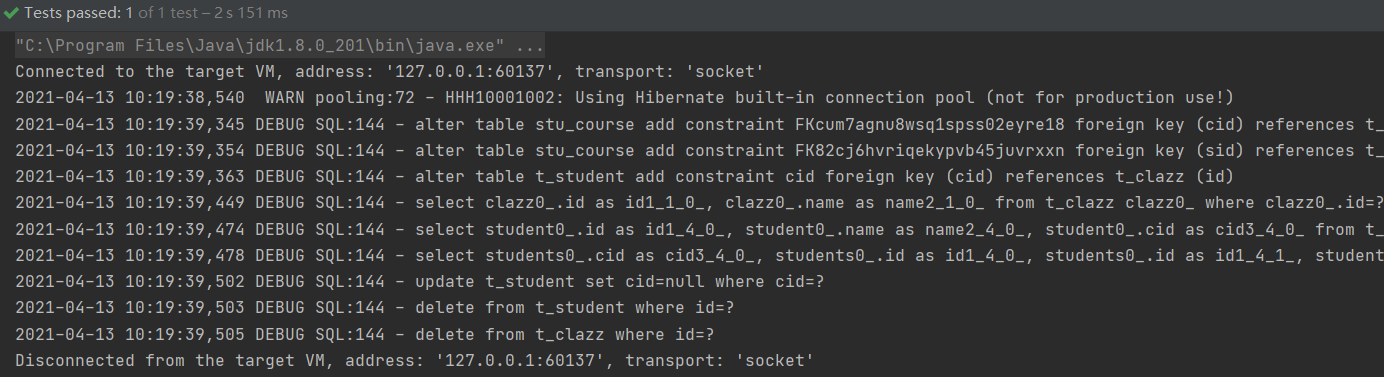
数据也正常被删除了,达到了预定的效果。
8.4.5多对多级联添加
前面已经熟悉了一对多的级联添加,那么多对多的级添加也是同样的道理,直接贴代码。
1)测试方法test4
@Test public void test4() { Session session = HibernateUtils.getSession(); session.beginTransaction(); //学生 Stud student1 = new Stud().setName("蔡敏敏"); Stud student2 = new Stud().setName("李明"); //学科 Course course = new Course().setName("java 基础"); Course course2 = new Course().setName("NySQL 基础"); //学生关联科目 student1.getCourses().add(course); student1.getCourses().add(course2); student2.getCourses().add(course); student2.getCourses().add(course2); //保存数据 session.save(student1); session.save(student2); //提交事务 session.getTransaction().commit(); //关闭session session.close(); }
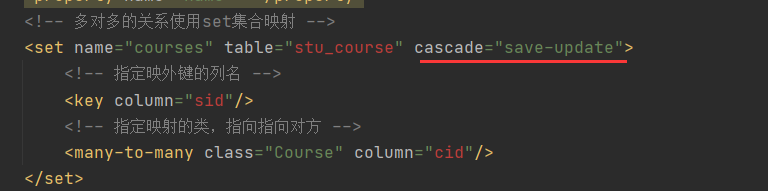
2)修改Stud.hbm.xml的属性cascade="save-update"
3)运行测试方法,日志截图如下,数据添加成功:

8.4.6多对多级联删除
多对多级联删除和一对多的级联删除类似,直接贴代码:
1)测试方法test5
@Test public void test5() { Session session = HibernateUtils.getSession(); session.beginTransaction(); Stud stud = session.get(Stud.class, 2); session.delete(stud); session.getTransaction().commit(); session.close(); }
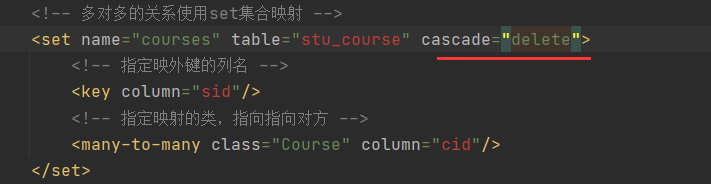
2)修改Stud.hbm.xml的属性cascade="delete"
3)运行测试方法,日志截图如下,数据删除成功:
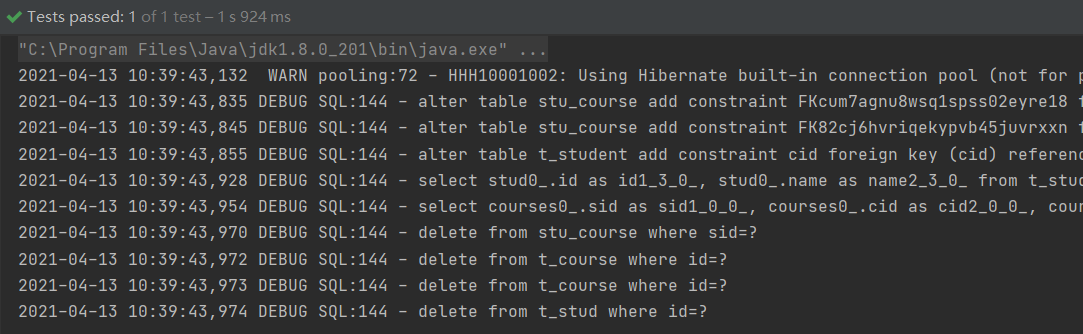
9.Hibernate的5种检索方式
9.1导航对象图检索
导航对象图检索方式是根据已经加载的对象,导航到其他对象,利用的是类与类之间的关系检索对象。
Student student = session.get(Student.class, 4); Clazz clazz = student.getClazz();
这种方式不常用。
9.2 OID 检索
OID 检索方式是指按照对象的 OID 检索对象。它使用 Session 对象的 get() 和 load() 方法加载某一条记录所对应的对象,其使用的前提是需要事先知道 OID 的值。
Student student = session.get(Student.class, 4);
9.3 HQL 检索
HQL(Hibernate Query Language)是 Hibernate 查询语言的简称,它是一种面向对象的查询语言,与 SQL 查询语言有些类似,但它使用的是类、对象和属性的概念,而没有表和字段的概念。
9.3.1 HQL 检索语法
select/update/delete...]from...[where...][group by...][having...][order by...][asc/desc]
HQL 查询与 SQL 查询非常类似,通常情况下,当检索表中的所有数据时,查询语句中可以省略 select 关键字。这种查询使用createQuery()执行,数据使用list()方法获取。
String hql="from User";
需要注意的是,语句中 User 表示类名,而不是表名,因此需要区分大小写。新建测试类HQLQuery,本小节的测试方法在里面创建。
9.3.2指定别名
指定别名和sql中的as一样,对字段或表名指定别名。下面的案例对表名指定别名:
@Test
public void test1(){
Session session = HibernateUtils.getSession();
String sql ="from User t where t.name='lisi'";
Query query = session.createQuery(sql);
List<User> list = query.list();
System.out.println(list);
session.close();
}
这里查询出了所有的字段信息,有时候想只查询部分字段信息,就需要使用投影查询。
9.3.3投影查询
投影查询就是只查询一部分字段,把数据库的字段与实体类的字段进行投影。
@Test public void test2(){ Session session = HibernateUtils.getSession(); String sql ="select t.id,t.name from User t"; Query query = session.createQuery(sql); List<Object[]> list = query.list(); Iterator<Object[]> iter = list.iterator(); while (iter.hasNext()) { Object[] objs = iter.next(); System.out.println(objs[0] + " " + objs[1]); } session.close(); }
上述语句只查询了用户的id和姓名,这就属于只查询部分字段。那么对于这种情况,查询返回的一个数组类型的集合,集合的大小代表查询的数据条数,数组的大小代表查询的字段个数。数组中的元素都是按照查询的语句字段的顺序来的,不同的字段对应不同的位置。如上述objs[0]代表字段id,objs[1]代表字段name,这是因为在select后id是第一位,name是第二位。
查询的结果如下图:

使用这种查询,麻烦之处在于对查询结果的处理,必须按照顺序进行一一处理。
9.3.4动态实例查询
动态实例查询将检索出来的数据重新封装到一个实体的实例中,提高了检索效率。
@Test public void test3(){ Session session = HibernateUtils.getSession(); String sql ="select new User (t.id,t.name) from User t"; Query query = session.createQuery(sql); List<User> list = query.list(); System.out.println(list); session.close(); }
由于这里创建了对象User,那么就需要给User对象添加部分参数构造函数(无参构造默认已存在),否则会报错:
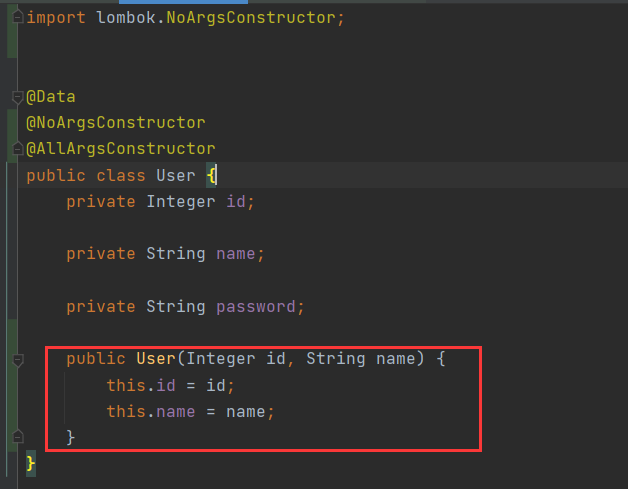
执行测试方法,数据查询成功,已经被封装到User对象中。需要注意的就是要给对应的类添加部分参数构造。也就是说,要查询哪几个参数,就需要用这几个参数创建一个有参构造。
9.3.5条件查询
Hibernate条件查询分为按参数位置查询和按参数名称查询。
1)按参数位置查询
按参数位置查询时,需要在 HQL 语句中使用“?”定义参数的位置,然后通过 Query 对象的 setXxx() 方法为其赋值,为参数赋值的常用方法如下表
| 方法名 | 说 明 |
|---|---|
| setString() | 给映射类型为 String 的参数赋值 |
| setDate() | 给映射类型为 Date 的参数赋值 |
| setTime() | 给映射类型为 Date 的参数赋值 |
| setDouble() | 给映射类型为 double 的参数赋值 |
| setBoolean() | 给映射类型为 boolean 的参数赋值 |
| setInteger() | 给映射类型为 int 的参数赋值 |
| setParameter() | 给任意类型的参数赋值 |
新建一个测试方法test4,使用like关键字进行模糊查询:
@Test
public void test4(){
Session session = HibernateUtils.getSession();
//使用?作为占位符,后面需要指定所在的位置索引
String sql ="from User t where t.name like ?0 and t.password like ?1";
Query query = session.createQuery(sql);
//根据位置设置查询条件,位置表示的是?所在的索引位置,如第一个后面是0
query.setString(0,"%zhang%").setString(1,"%12%");
List<User> list = query.list();
System.out.println(list);
session.close();
}
在设置占位符时,使用?作为占位符,后面需要指定所在的位置索引,如第一个位置就是"?0"。设置参数时,要根据索引指定参数的位置。这种方式必须指定索引,只要一个索引写错了,就无法查询成功。
2)按参数名称查询
按参数名字查询时,需要在 HQL 语句中定义命名参数,命名参数是“:”和自定义参数名的组合。
新建一个测试方法test5,使用like关键字进行模糊查询:
@Test public void test5(){ Session session = HibernateUtils.getSession(); //使用:命名参数 String sql ="from User t where t.name like :name1 and t.password like :pwd"; Query query = session.createQuery(sql); //根据参数名称设置参数 query.setParameter("name1","%zhang%").setParameter("pwd","%12%"); List<User> list = query.list(); System.out.println(list); session.close(); }
这种方式和上面按照参数位置查询的结果是一样的。
3)Hibernate支持的常用运算符
| 类 型 | HQL 运算符 |
|---|---|
| 比较运算 | >,<,=,>=,<=,<>,!= |
| 逻辑运算 | and,or,not |
| 模式匹配 | like |
| 范围运算 | in,not in,between,not between |
| 其他运算符 | is null,is not null,is empty,is not empty等 |
9.3.6分页查询
Hibernate的分页查询使用Query接口,使用setFirstResult(int index)表示查询的起始索引值,使用setMaxResult(int size)表示每次查询的条数。
@Test public void test6(){ Session session = HibernateUtils.getSession(); String sql ="from User"; Query query = session.createQuery(sql); //设置查询的起始索引 query.setFirstResult(2); //设置查询的条数 query.setMaxResults(10); List<User> list = query.list(); System.out.println(list); session.close(); }
上述代码查询的是从索引2开始的10条数据。那么在实际情况中,会传入当前页码和分页条数,需要对其进行转换。例如查询第m页的n条数据,那么分页条件设置如下:
query.setFirstResult((m-1)*n); query.setMaxResults(n);
9.4 QBC 检索
QBC(Query By Criteria),它主要由 Criteria 接口、Criterion 接口和 Expression 类组成,并且支持在运行时动态生成查询语句。
新建测试类QBCQuery,本小节的测试方法在里面创建。
9.4.1组合查询
组合查询是指通过 Restrictions 工具类的相应方法动态地构造查询条件,并将查询条件加入 Criteria 对象,从而实现查询功能。
新建测试方法test1:
@Test public void test1(){ Session session = HibernateUtils.getSession(); Criteria criteria = session.createCriteria(User.class); // 设定查询条件 LogicalExpression expression = Restrictions.or(Restrictions.like("name", "%li%"), Restrictions.eq("id", 3)); // 添加查询条件 criteria.add(expression); // 执行查询,返回查询结果 List<User> list = criteria.list(); System.out.println(list); session.close(); }
上述代码查询的条件是:查询name包含"li"或id=3的用户信息。先设置查询的条件,把查询的条件放到Criteria 中去执行,获取查询的结果。条件的设置上述用到了or、eq和like,其常用的条件如下表:
| 方法名 | 说 明 |
|---|---|
| Restrictions.eq | 等于 |
| Restrictions.like | 对应 SQL 的 like 子句 |
| Restrictions.or | or关系 |
| Restrictions.and | and 关系 |
| Restrictions.allEq | 使用 Map 和 key/value 进行多个等于的比较 |
| Restrictions.gt | 大于 > |
| Restrictions.ge | 大于等于 >= |
| Restrictions.lt | 小于 |
| Restrictions.le | 小于等于 <= |
| Restrictions.between | 对应 SQL 的 between 子句 |
| Restrictions.in | 对应 SQL 的 IN 子句 |
| Restrictions.sqlRestriction | SQL 限定查询 |
9.4.2分页查询
QBC也可以实现分页查询。在 Criteria 对象中,通过设置setFirstResult(int index)和setMaxResult(int size)进行分页查询。
@Test public void test2(){ Session session = HibernateUtils.getSession(); Criteria criteria = session.createCriteria(User.class); // 设定分页条件 criteria.setFirstResult(2); criteria.setMaxResults(10); // 执行查询,返回查询结果 List<User> list = criteria.list(); System.out.println(list); session.close(); }
设置的参数和HQL的参数说明是一样的,就不多说。
9.5本地 SQL 检索
本地 SQL 检索方式就是使用本地数据库的 SQL 查询语句进行查询。
新建测试类LocalQuery,本小节的测试方法在里面创建。
9.5.1不指定类型查询(查询结果类型是Object)
@Test public void test1() { Session session = HibernateUtils.getSession(); SQLQuery sqlQuery = session.createSQLQuery("select * from t_user"); List queryList = sqlQuery.list(); System.out.println(queryList); session.close(); }
通过这种查询得到的只是对象的地址,无法得到具体的数据。不推荐使用!
9.5.2将查询结果封装为对象
在查询时添加要封装的对象即可
@Test public void test2() { Session session = HibernateUtils.getSession(); SQLQuery sqlQuery = session.createSQLQuery("select * from t_user"); sqlQuery.addEntity(User.class); List<Object> queryList = sqlQuery.list(); System.out.println(queryList); session.close(); }
这样查询出来的数据就是对象类型,可以看到具体的内容,方便使用。
9.5.3动态参数查询
本身sql检索也可以使用动态参数的格式进行查询,用法和HQL的动态参数查询类似,这里只举例说明
@Test public void test3() { Session session = HibernateUtils.getSession(); SQLQuery sqlQuery = session.createSQLQuery("select * from t_user where name=:name"); //设置封装对象 sqlQuery.addEntity(User.class); //指定参数 sqlQuery.setString("name","zhangsan111"); List<Object> queryList = sqlQuery.list(); System.out.println(queryList); session.close(); }
10.Hibernate事务操作
10.1事务配置
Hibernate事务配置有两种方式,推荐使用第二种方式。
1)使用代码操作管理事务
开启事务:Transaction tx = session.beginTransaction();
提交事务:tx.commit();
回滚事务:tx.rollback();
2)在核心配置文件中配置事务
<!--使用本地事务--> <property name= "hibernate.current_session_context_class"> thread</property> <!--设置事务隔离级别--> <property name= "hibernate.connection.isolation">2</property>