使用SparkThrfitServer结合Hive来做即席查询,那么会遇到这样的问题,一个数据量很大的查询SQL把所有的资源全占了,导致后面的SQL都等待,尽管在等待的SQL只需要几秒就能完成。
表数据量
3亿+条,36G左右(partquet+snappy)
sql语句
sql1
且不要管sql合理不合理,就是想让它多计算一点
SELECT count(1) FROM ( SELECT google_gci ,google_gri ,count(1) FROM capacity.cell_pathloss_data_hangzhou GROUP BY google_gci ,google_gri ) a;
sql2
select * from capacity.cell_pathloss_data_hangzhou limit 10;
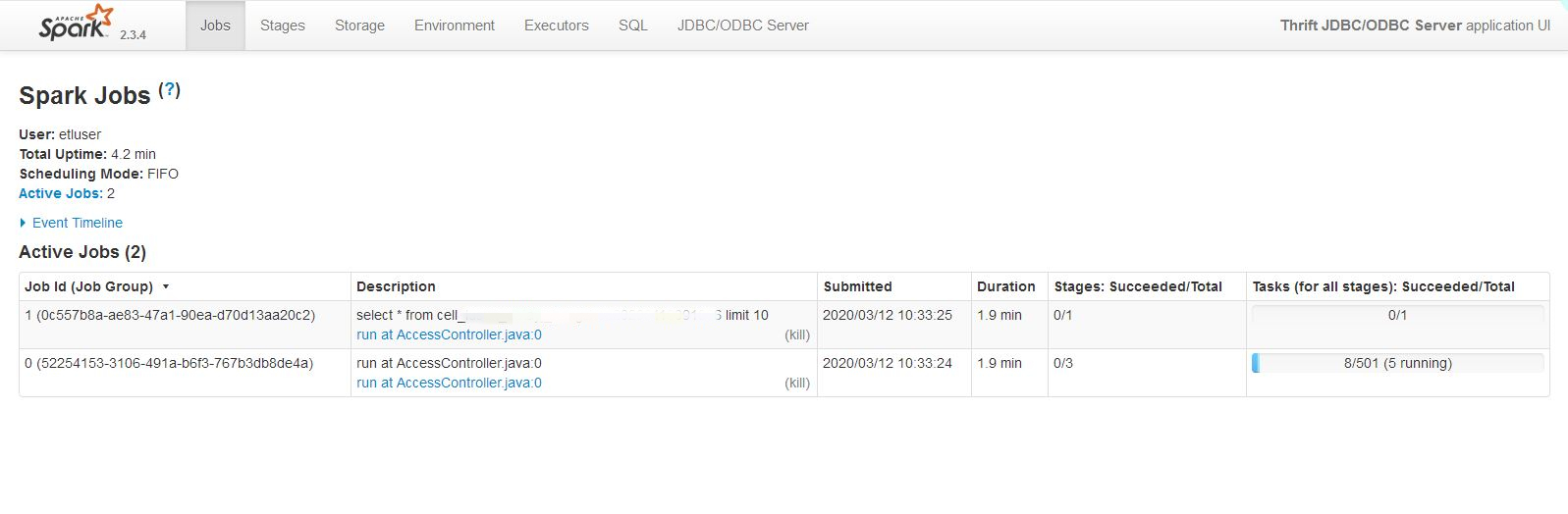
第1次:默认情况,也就是FIFO模式
启动thriftserver
/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/sbin/stop-thriftserver.sh /home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/sbin/start-thriftserver.sh --master yarn --driver-memory 1G --executor-memory 1G --num-executors 2 --executor-cores 2 --hiveconf hive.server2.thrift.bind.host=`hostname -i` --hiveconf hive.server2.thrift.port=9012
执行情况如图,可以看到,调度模式为FIFO,sql2一直未能执行

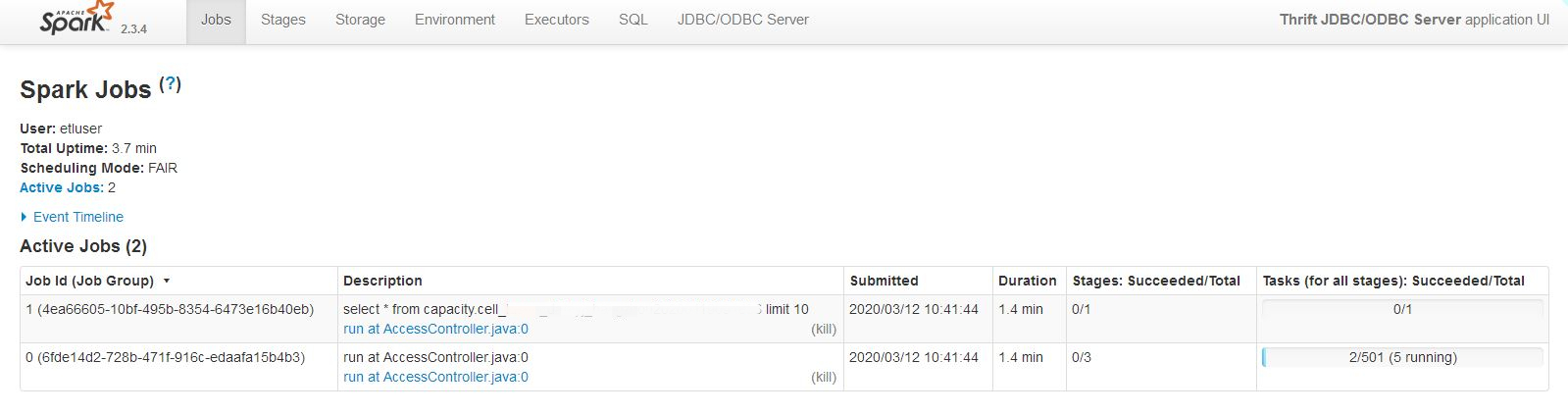
第2次:FAIR模式,不指定提交资源池(即default)
创建fairscheduler.xml文件
<allocations> <pool name="pool1"> <schedulingMode>FAIR</schedulingMode> <weight>5</weight> <minShare>3</minShare> </pool> <pool name="pool2"> <schedulingMode>FAIR</schedulingMode> <weight>2</weight> <minShare>1</minShare> </pool> </allocations>
启动thriftserver
/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/sbin/stop-thriftserver.sh /home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/sbin/start-thriftserver.sh --master yarn --driver-memory 1G --executor-memory 1G --num-executors 2 --executor-cores 2 --conf spark.scheduler.mode=FAIR --conf spark.scheduler.allocation.file=/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf/fairscheduler.xml --hiveconf hive.server2.thrift.bind.host=`hostname -i` --hiveconf hive.server2.thrift.port=9012
执行情况如图,可以看到,调度模式为FAIR,但是默认提交到default资源池,default池默认为FIFO,sql2一直未能执行。
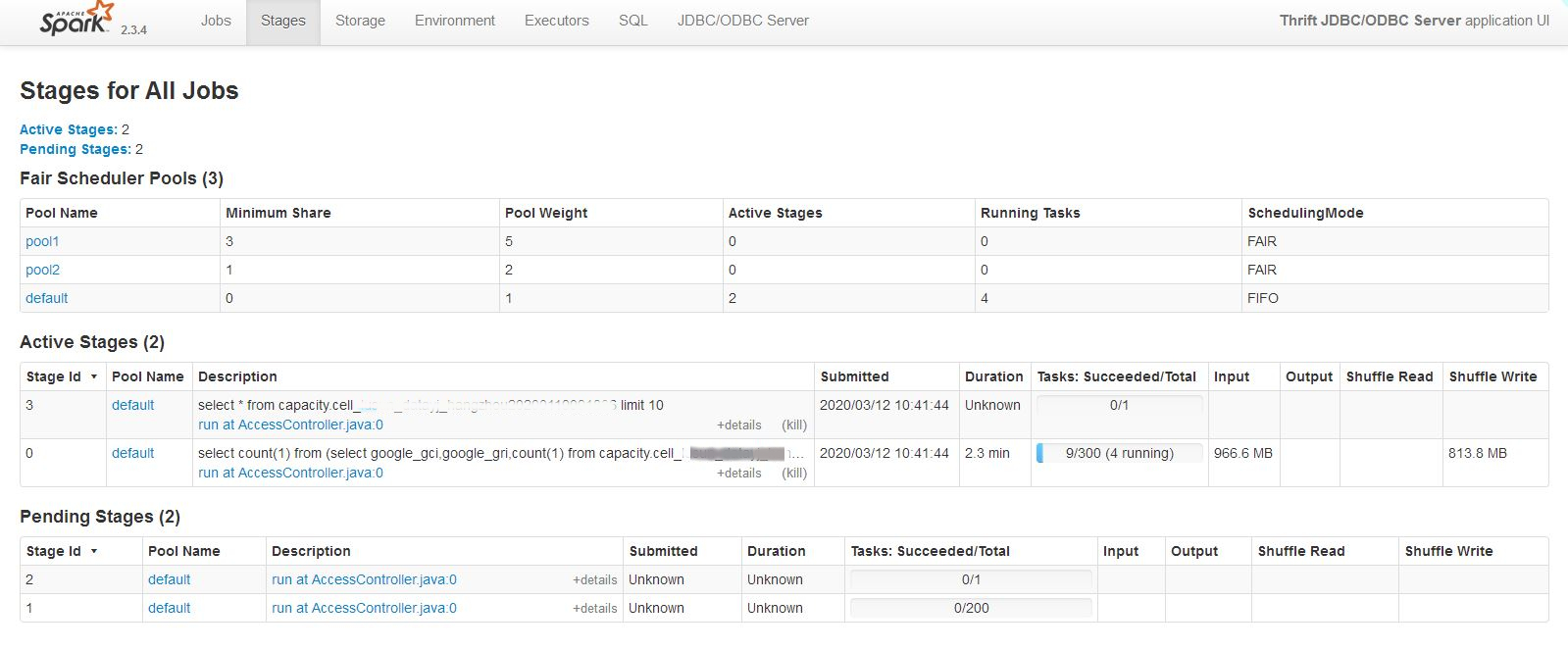
第3次:FAIR模式,提交任务到指定池
set spark.sql.thriftserver.scheduler.pool=pool1;
执行情况如图,可以看到,调度模式FAIR,提交到资源池poll1,后提交的sql2在sql1执行的同时也被执行了。


注意
1.FIFO模式并非一定是sql1先执行完,sql2才可以执行。如果在资源充足的情况下,sql2依旧能
及时执行。但是如果资源被sql1基本吃掉了,那sql2的执行会很慢甚至等到sql1执行完毕才能执行。
2.FAIR模式下,spark在多个job之间以轮询(round robin)的方式去调度task,这样所有的job都可以大致平等的共享集群资源
,更适合多用户的情景。
3.FAIR模式下,可以配置多个资源池,设置不同的优先级/权重,设置一个很高权重(比如1000)也可以让池之间保持一个优先级
,比如这里的权重是1000池当它有job存在时,总会先启动任务。
参考:http://spark.apache.org/docs/2.3.3/job-scheduling.html#scheduling-within-an-application