第一题:用resquests库访问百度主页20次,并返回他的text 和content属性的长度。
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue May 19 10:12:16 2020 4 5 @author: 49594 6 """ 7 8 import requests 9 url = "https://www.baidu.com/" 10 for i in range(20): 11 try: 12 rest = requests.get (url,timeout=30) 13 rest.raise_for_status() 14 r=rest.content.decode('utf-8') 15 print(r) 16 17 except: 18 print("error") 19 print("text属性长度",len(rest.text)) 20 print("content属性长度",len(rest.content))
由于结果篇幅过长,所以只截取部分爬虫内容:
1 <!DOCTYPE html> 2 <!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>'); 3 </script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
长度输出结果如下:
text属性长度 2443
content属性长度 2443
第二题:
这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
a.打印head标签内容和你的学号后两位
b 获取body标签内容
c 获取id为first的标签对象
d 获取并打印html页面中的中文字符
html为:
1 <!DOCTYPE html> 2 3 <html> 4 5 <head> 6 7 <meta charset="utf-8"> 8 9 <title>菜鸟教程(runoob.com)</title> 10 11 </head> 12 13 <body> 14 15 <hl>我的第一个标题学号25</hl> 16 17 <p id="first">我的第一个段落。</p> 18 19 </body> 20 21 <table border="1"> 22 23 <tr> 24 25 <td>row 1, cell 1</td> 26 27 <td>row 1, cell 2</td> 28 29 </tr> 30 31 <tr> 32 33 <td>row 2, cell 1</td> 34 35 <td>row 2, cell 2</td> 36 37 <tr> 38 39 </table> 40 41 </html>
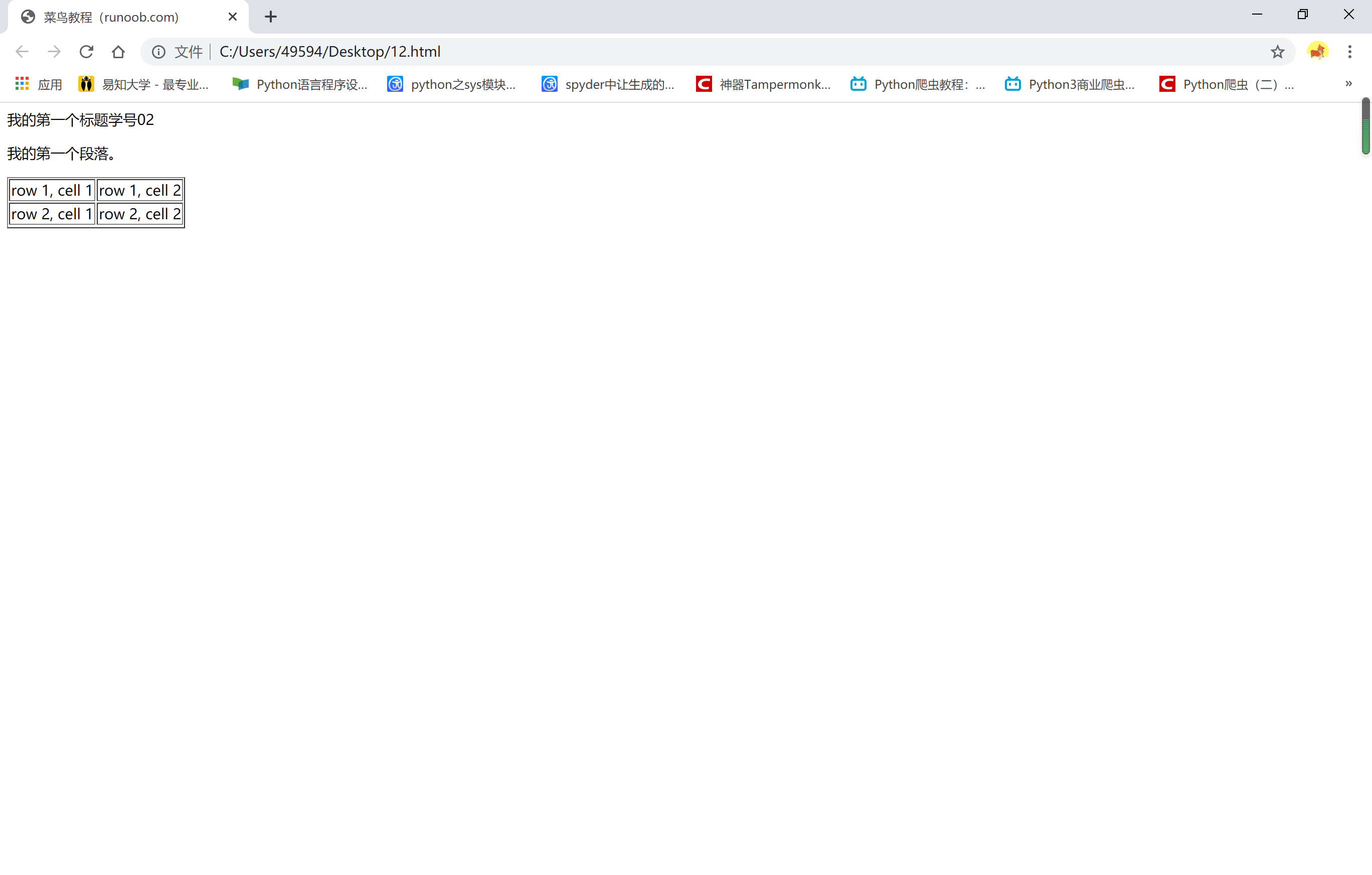
我的结果如下:
打印head标签和我的学号:
None 我的学号:02
获取body标签内容 <body><html1>
<meta charset="utf-8"/>
<title>菜鸟教程(runoob.com)</title>
<hl>我的第一标题</hl>
<p id="first">我的第一个段落。</p>
<table border="1">
<tr>
<td>row 1, cell 1</td>
<td>row 1, cell 2</td>
</tr>
<tr>
<td>row 2, cell 1</td>
<td>row 2, cell 2</td>
</tr><tr>
</tr></table>
</html1></body>
获取id为first的标签对象 [<p id="first">我的第一个段落。</p>]
获取并打印html页面中的中文字符
['菜', '鸟', '教', '程', '我', '的', '第', '一', '标', '题', '我', '的', '第', '一', '个', '段', '落', '。']
第三题:爬取中国大学排名
网址:http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html
代码如下:
1 import csv 2 import os 3 import requests 4 from bs4 import BeautifulSoup 5 allUniv = [] 6 def getHTMLText(url): 7 try: 8 r = requests.get(url, timeout=30) 9 r.raise_for_status() 10 r.encoding ='utf-8' 11 return r.text 12 except: 13 return "" 14 def fillUnivList(soup): 15 data = soup.find_all('tr') 16 for tr in data: 17 ltd = tr.find_all('td') 18 if len(ltd)==0: 19 continue 20 singleUniv = [] 21 for td in ltd: 22 singleUniv.append(td.string) 23 allUniv.append(singleUniv) 24 def writercsv(save_road,num,title): 25 if os.path.isfile(save_road): 26 with open(save_road,'a',newline='')as f: 27 csv_write=csv.writer(f,dialect='excel') 28 for i in range(num): 29 u=allUniv[i] 30 csv_write.writerow(u) 31 else: 32 with open(save_road,'w',newline='')as f: 33 csv_write=csv.writer(f,dialect='excel') 34 csv_write.writerow(title) 35 for i in range(num): 36 u=allUniv[i] 37 csv_write.writerow(u) 38 title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模", 39 "科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化","学生国际化"] 40 save_road="D:\paiming.csv" 41 def main(): 42 url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2018.html' 43 html = getHTMLText(url) 44 soup = BeautifulSoup(html, "html.parser") 45 fillUnivList(soup) 46 writercsv(save_road,20,title) 47 main()
csv文件如下: