强化学习入门第四讲 时间差分方法
上一节我们已经讲了无模型强化学习最基本的方法蒙特卡罗方法。本节,我们讲另外一个无模型的方法时间差分的方法。
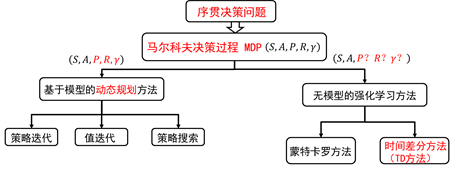
图4.1 强化学习算法分类
时间差分(TD)方法是强化学习理论中最核心的内容,是强化学习领域最重要的成果,没有之一。与动态规划的方法和蒙特卡罗的方法比,时间差分的方法主要不同点在值函数估计上面。
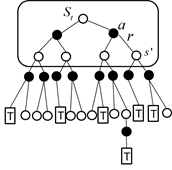
图4.2 动态规划方法计算值函数
(4.1)
方程(4.1)给出了值函数估计的计算公式,从公式中可以看到,DP方法计算值函数时用到了当前状态s的所有后继状态s’处的值函数。值函数的计算用到了bootstapping的方法。所谓bootstrpping本意是指自举,此处是指当前值函数的计算用到了后继状态的值函数。即用后继状态的值函数估计当前值函数。特别注意,此处后继的状态是由模型公式
计算得到的。由模型公式和动作集,可以计算状态s所有的后继状态s’。当没有模型时,后继状态无法全部得到,只能通过试验和采样的方法每次试验得到一个后继状态s’。
无模型时,我们可以采用蒙特卡罗的方法利用经验平均来估计当前状态的值函数。其计算值函数示意图如图4.3所示。
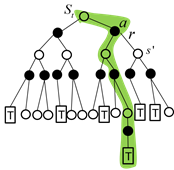
图4.3 蒙特卡罗方法计算值函数
蒙特卡罗方法利用经验平均估计状态的值函数,所谓的经验是指一次试验,而一次试验要等到终止状态出现才结束,如图4.3所示。公式(4.2)中的是状态后直到终止状态所有回报的返回值。
(4.2)
相比于动态规划的方法,蒙特卡罗的方法需要等到每次试验结束,所以学习速度慢,学习效率不高。从两者的比较我们很自然地会想,能不能借鉴动态规划中boot’strapping的方法,在不等到试验结束时就估计当前的值函数呢?
答案是肯定的,这就是时间差分方法的精髓。时间差分方法结合了蒙特卡罗的采样方法(即做试验)和动态规划方法的bootstrapping(利用后继状态的值函数估计当前值函数),其示意图如图4.4所示。
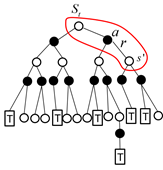
图4.4 时间差分方法计算值函数
TD方法更新值函数的公式为(4.3):
(4.3)
其中称为TD目标,与(4.2)中的相对应,两者不同之处是TD目标利用了bootstrapping方法估计当前值函数。 称为TD偏差。
下面我们从原始公式给出动态规划(DP),蒙特卡罗方法(MC),和时间差分方法(TD)的不同之处。
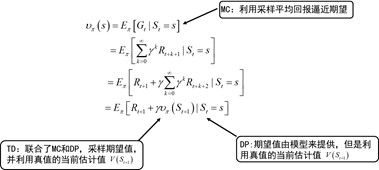
图4.5 DP,MC和TD方法的异同
图4.5给出了三种方法估计值函数时的异同点。从图中可以看到,蒙特卡罗的方法使用的是值函数最原始的定义,该方法利用所有回报的累积和估计值函数。DP方法和TD方法则利用一步预测方法计算当前状态值函数。其共同点是利用了bootstrapping方法,不同的是,DP方法利用模型计算后继状态,而TD方法利用试验得到后继状态。
从统计学的角度来看,蒙特卡罗方法(MC方法)和时间差分方法(TD方法)都是利用样本去估计值函数的方法,哪种估计方法更好呢?既然是统计方法,我们就可以从期望和方差两个指标对两种方法进行对比。
首先蒙特卡罗方法:
蒙特卡罗方法中的返回值 ,其期望便是值函数的定义,因此蒙特卡罗方法是无偏估计。但是,蒙特卡罗方法每次得到的 值要等到最终状态出现,在这个过程中要经历很多随机的状态和动作,因此每次得到的随机性很大,所以尽管期望等于真值,但方差无穷大。
其次,时间差分方法:
时间差分方法的TD目标为,若 采用真实值,则TD估计也是无偏估计,然而在试验中 用的也是估计值,因此时间差分估计方法属于有偏估计。然而,跟蒙特卡罗方法相比,时间差分方法只用到了一步随机状态和动作,因此TD目标的随机性比蒙特卡罗方法中的 要小,因此其方差也比蒙特卡罗方法的方差小。

图4.6 on-policy Sarsa强化学习算法
如图4.6为同策略Sarsa强化学习算法,主要注意的是方框中代码表示同策略中的行动策略和评估的策略都是 贪婪策略。与蒙特卡罗方法不同的是,值函数更新不同。

图4.7 off-policy Qlearning
如图4.7为异策略的Qlearning方法。与Sarsa方法的不同之处在于,Qlearning方法是异策略。即行动策略采用 贪婪策略,而目标策略采用贪婪策略。
从图4.4我们看到,在更新当前值函数时,用到了下一个状态的值函数。那么我们可以以此推理,能不能利用后继第二个状态的值函数来更新当前状态的值函数呢?
答案是肯定的,那么如何利用公式计算呢?
我们用 表示TD目标,则利用第二步值函数来估计当前值函数可表示为: 以此类推,利用第n步的值函数更新当前值函数可表示为:
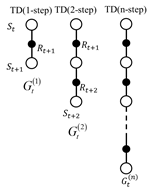
图4.8 n步预测估计值函数
如图4.8所示为利用n步值函数估计当前值函数的示意图。我们再审视一下刚刚的结论:可以利用n步值函数来估计当前值函数,也就是说当前值函数有n种估计方法。
哪种估计值更接近真实值呢?
我们不知道,但是我们是不是可以对这n个估计值利用加权的方法进行融合一下呢?这就是的方法。
我们在前乘以加权因子,为什么要乘这个加权呢?这是因为:
(4.4)
利用来更新当前状态的值函数的方法称为的方法。对于 的理解一般可以从两个视角进行解读。
第一个视角是前向视角,该视角也是的定义。
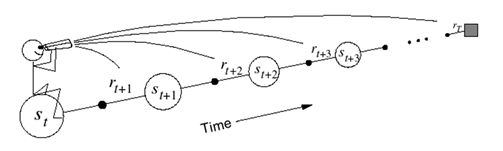
图4.9 的前向视角
如图4.9所示为方法的前向视角解释。假设一个人坐在状态流上拿着望远镜看向前方,前方是那些将来的状态。当估计当前状态的值函数时,的定义中可以看到,它需要用来将来时刻的值函数。也就是说,前向观点通过观看将来状态的值函数来估计当前的值函数。
(4.4)
其中 ,而
利用的前向观点估计值函数时, 的计算用到了将来时刻的值函数,因此需要等到整个试验结束之后。这跟蒙塔卡罗方法相似。那么有没有一种更新方法不需要等到试验结束就可以更新当前状态的值函数呢?
有,这种增量式的更新方法需要利用的后向观点。
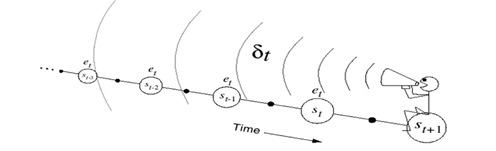
图4.10 的后向观点
如图4.10为后向观点示意图,人骑坐在状态流上,手里拿着话筒,面朝已经经历过的状态流,获得当前回报并利用下一个状态的值函数得到TD偏差后,此人会向已经经历过的状态喊话,告诉这些已经经历过的状态处的值函数需要利用当前时刻的TD偏差进行更新。此时过往的每个状态值函数更新的大小应该跟距离当前状态的步数有关。假设当前状态为,TD偏差为 ,那么处的值函数更新应该乘以一个衰减因子,状态 处的值函数更新应该乘以 ,以此类推。
更新过程为:
(1)
首先计算当前状态的TD偏差:
(2)
更新适合度轨迹:
(3)
对于状态空间中的每个状态s, 更新值函数:
其中称为适合度轨迹。
注意:现在我们比较一下的前向观点和后向观点的异同:
(1)
前向观点需要等到一次试验之后再更新当前状态的值函数;而后向观点不需要等到值函数结束后再更新值函数,而是每一步都在更新值函数,是增量式方法。
(2)
前向观点在一次试验结束后更新值函数时,更新完当前状态的值函数后,此状态的值函数就不再改变。而后向观点,在每一步计算完当前的TD误差后,其他状态的值函数需要利用当前状态的TD误差进行更新。
(3)
在一次试验结束后,前向观点和后向观点每个状态的值函数的更新总量是相等的,都是。
为了说明前向观点和后向观点的等价性,我们从公式上对其进行严格地证明。
首先,当 时,只有当前状态值更新,此时等价于之前说的TD方法。所以TD方法又称为TD(0)方法.
其次,当时,状态s值函数总的更新与蒙特卡罗方法相同:
对于一般的,前向观点等于后向观点:
注意,所谓等价是指更新总量相等。
最后,我们给出算法的伪代码:

图4.11 Sarsa算法的伪代码