
树的定义
形式化定义
树:T={D,R }。D是包含n个结点的有限集合(n≥0)。
当n=0时为空树,否则关系R满足以下条件:
l 有且仅有一个结点d0∈D,它对于关系R来说没有前驱结点,结点d0称作树的根结点。
l 除根结点外,每个结点有且仅有一个前驱结点。
l D中每个结点可以有零个或多个后继结点。
递归定义
树是由n(n≥0)个结点组成的有限集合(记为T)。其中:
l 如果n=0,它是一棵空树,这是树的特例;
l 如果n>0,这n个结点中存在一个唯一结点作为树的根结点(root),其余结点可分为m (m≥0)个互不相交的有限子集T1、T2、…、Tm,而每个子集本身又是一棵树,称为根结点root的子树。 ð 树中所有结点构成一种层次关系!
树的基本术语
度
结点的度:一个结点的子树的个数
树的度:各节点的度的最大值。
通常将度为m的树成为m次树或m叉树
结点
分支结点:度不为0的结点(也称非终端结点)
度为1的结点成为单分支结点,度为2的结点称为双分支结点
叶结点:度为0的结点
路径与路径长度
路径:两个结点di和dj的结点序列(di,di1,di2,…,dj)。其中<dx,dy>是分支。
路径长度:等于路径所通过的结点数目减1(即路径上的分支数目)
结点的层次和树高度
层次:根结点层次为1,它的孩子结点层次为2。以此类推。
树的高度(深度):结点中的最大层次;
有序树和无序树
有序树:若树中各结点的子树是按照一定的次序从左向右安排的,且相对次序是不能随
意变换的
无序树:和上面相反
森林
n(n>0)个互不相交的树的集合称为森林。
只要把树的根结点删去就成了森林。
反之,只要给n棵独立的树加上一个结点,并把这n棵树作为该结点的子树,则森林就变成了一颗树。
树的性质
性质1:树中的结点数等于所有结点的度数之和加1。
证明:树的每个分支记为一个度,度数和=分支和,而再给根节点加个分支
性质2:度为m的树中第i层上至多有mi-1个结点(i≥1)。
性质3 高度为h的m次树至多有 个结点。
性质4 具有*n*个结点的*m*次树的最小高度为élog*m*(*n*(*m*-1)+1)ù。
二叉树的定义
递归定义
二叉树是有限的集合:
这个集合或者是空;
或者由一个根节点和两个互不相交的称为左子树和右子树的二叉树构成;
满二叉树和完全二叉树
满二叉树:所有分支结点都有双分结点,并且叶结点都集中在二叉树的最下一层。
高度为h的满二叉树恰好有2h-1 个结点。
完全二叉树:最多只有下面两层的结点的度数小于2,并且最下面一层的叶结点都依次排列在最左边的位置上
二叉树的性质
注意:结点数总数----n; 叶子结点数----n0;单分支结点数---n1;双分支结点数----n2;
l 性质1 非空二叉树上的叶结点数等于双分支结点数+1,即n0=n2+1;
1度之和=n-1=n1+2n2;
2n=n0+n1+n2;
得:n0+n1+n2-1=n1+2n2;
可得:n0=n2+1;
重要关系:1 n=n1+2n2+1
2 度之和=n-1=n1+2n2;
3 n=n0+n1+n2
l 性质2 非空二叉树上第i层上至多有2i-1个结点(i≥1)。
由树的性质2可推出。
l 性质3 高度为h的二叉树至多有2h-1个结点(h≥1)。
由树的性质3可推出。
l 性质4 完全二叉树性质(含n为结点):
1) n1=0****或n1=1;n1可由n的奇偶决定;

2) 若i≤n/2,则编号为i的结点为分支结点,否则为叶结点。
证:

第一个叶子结点总是n/2+1
3) 除树根结点外,若一个结点的编号为i,则它的双亲结点的编号为i/2。
4) 若编号为i的结点有左孩子结点,则左孩子结点的编号为2i;若编号为I
的结点有右孩子结点,则右孩子结点的编号为2i+1。
二叉树的存储
顺序存储
对于完全二叉树来说非常合适,而对于一般二叉树(特别是单分支结点特别多的)非常不合适;找一个结点的双亲和孩子结点都非常容易。
链式存储结构
| lchild | data | rchild |
|---|---|---|
结点的类型定义
typedef struct node
{ ElemType data;
struct node *lchild, *rchild;
} BTNode;
优点:节省空间;方便访问孩子结点
缺点:寻找双亲不方便
二叉链的空指针数
二叉树的遍历
先序遍历
先访问根节点;
先序遍历左子树;
先序遍历右子树;
void PreOrder(BTNode *b)
{ if (b!=NULL)
{ printf("%c ",b->data); //访问根结点
PreOrder(b->lchild);
PreOrder(b->rchild);
}
}
中序遍历
中序遍历左子树;
访问根结点;
中序遍历右子树;
void InOrder(BTNode *b)
{
if (b!=NULL)
{
InOrder(b->lchild);
printf("%c ",b->data); //访问根结点
InOrder(b->rchild);
}
}
后序遍历
后序遍历左子树;
后序遍历右子树;
访问根节点;
void PostOrder(BTNode *b)
{ if (b!=NULL)
{ PostOrder(b->lchild);
PostOrder(b->rchild);
printf("%c ",b->data); //访问根结点
}
}
二叉排序树
定义
二叉排序树(简称BST)又称二叉查找(搜索)树,其定义为:二叉排序树或者是空树,或者是满足如下性质(BST性质)的二叉树:
若它的左子树非空,则左子树上所有结点值(指关键字值)均小于根结点值;
若它的右子树非空,则右子树上所有结点值均大于根结点值;
左、右子树本身又各是一棵二叉排序树。
二叉排序树的构建,插入,查找与删除
InsertBST(T, key) {
if (T为空) {
创建T;
T->data = key;
T的左孩子 = T的右孩子 = 空;
return;
}
else if (T->data = key)
return;
else if (key < T->data)
InsertBST(T->lchild, key);
else if (key > T->data)
InsertBST(T->rchild, key);
}
int InsertBST(BTree& BT, int k) {
if (BT == NULL) {
BT = new BTNode;
BT->data = k;
BT->lchild = BT->rchild = NULL;
return 1;
}
else if (BT->data == k) {
return 0;
}
else if (k < BT->data) {
return InsertBST(BT->lchild, k);
}
else
return InsertBST(BT->rchild, k);
}
BTree SearchBST(BTree BT, int k) {
if (BT == NULL || BT->data == k)
return BT;
if (k < BT->data)
return SearchBST(BT->lchild, k);
else
return SearchBST(BT->rchild, k);
}
void DeleteBST(BTree & BT) {
BTree q, s;
if (BT->lchild == NULL) {
q = BT;
BT = BT->rchild;
delete q;
}
else if (BT->rchild == NULL) {
q = BT;
BT = BT->lchild;
delete q;
}
else {
q = BT;
s = BT->lchild;
while (s->rchild) {
q = s;
s = s->rchild;
}
BT->data = s->data;
if (q == BT)
BT->lchild = s->lchild;
else
q->rchild = s->lchild;
delete s;
}
}
哈夫曼树
定义
设二叉树具有n个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积的和,叫做二叉树的带权路径长度。
构造哈夫曼树的原则:
权值越大的叶结点越靠近根结点。
权值越小的叶结点越远离根结点。
构造哈夫曼树的算法实现
void CreateHT(HTNode ht[], int n, float s[]) {
int i, j, k, l, r;
float min1, min2;
for (i = 0; i < n; i++) {
ht[i].data = s[i];
}
for (i = n; i < 2 * n - 1; i++) {
min1 = min2 = 32767;
r = l = -1;
for (k = 0; k < i; k++) {
if (ht[k].parent == -1) {
if (ht[k].data < min1) {
min2 = min1;
r = l;
min1 = ht[k].data;
l = k;
}
else if (ht[k].data < min2) {
min2 = ht[k].data;
r = k;
}
}
}
ht[i].data = ht[l].data + ht[r].data;
ht[i].l = l;
ht[i].r = r;
ht[l].parent = ht[r].parent = i;
}
}
哈希表
使用直接定址法、除留余数法或者数字分析法进行哈希表的创建排列
哈希冲突解决方法
开放定址法、拉链法
三.疑难问题及解决方案
疑难问题
PTA题目及样例

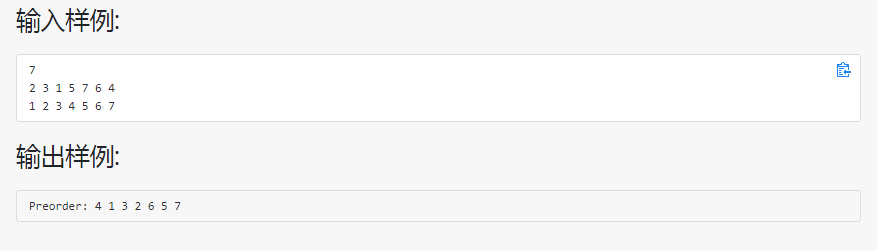
这道PTA题目 根据后序和中序遍历输出先序遍历 ,输入后序和中序遍历结果,输出中序遍历结果,一般想到的思路去构建二叉树,会发现思路不对,行不通,我们可以考虑其他方向,观察,找找后序和中序遍历的规律,寻找突破口。
解决方案
不难发现,后序遍历的最后一个结点一定为二叉树的根结点,根据这个根节点去找中序遍历,则中序遍历根节点的左边全为左子树的结点,右边全为右子树的结点,且左子树对应的长度对应在后序遍历中,后序遍历该段的数值也均为左子树数值,右子树同理,利用这个特点可以设递归函数去解决这个问题,结合代码理解这道题,具体代码实现如下:
#include<iostream>
#include<string>
using namespace std;
#define max 31
void outprintf(int a[], int b[], int n);
int main()
{
int n;
cin >> n;
int a[max], b[max];
for (int i = 0; i < n; i++)
cin >> a[i];
for (int i = 0; i < n; i++)
cin >> b[i];
cout << "Preorder:";
outprintf(a, b, n);
return 0;
}
void outprintf(int a[], int b[], int n)
{
int i;
if (n == 0) return;
for (i = 0; i < n; i++) {
if (b[i] == a[n - 1])
break;
}
int* p;
p = a + i;
cout << " " << a[n - 1];
outprintf(a, b, i);
outprintf(p, b + i + 1, n - i - 1);
}