表名: user_active_day (用户日活表)
表内容:
user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地区) partition_date(日期分区)
需求:
找出20180901至今的xxx地区的用户日活量以及新增用户量
思路:
筛选日期分区和地区,统计user_id的数量为用户日活量,统计user_is_new = 1的数量为新增用户量.
最开始写的hql语句
select partition_date,count(user_id),
count(if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
我们使用count(if())来进行筛选统计,但是效果并没有达到,出现的结果如下
20180901 16737 16737
根本就没有达到筛选的目的,为什么?
这就要从count的机制说起
首先count()是对数据进行计数,说白了就是你来一条数据我计数一条,我不关心你怎么分类,我只对数据计数
每条数据从if()函数出来,还是一条数据,所以count+1
所以count(user_id)跟count(if(user_id))没有任何的区别.
我们稍做修改
select partition_date,count(user_id),
count(distinct if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计,加了distinct去重
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 261
这次看着就像是对了吧,我们加了distinct进行去重
每次来一条数据先过if()然后再进行去重最后统计.但是实际上结果依旧是错误的.
我们来模拟一下筛选统计的过程
我们有这样四条数据
user_id user_is_new
1 1
2 0
3 1
4 0
表中的数据是一条一条遍历的,
(1)当user_id = 1的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 1),
然后我们把user_id = 1进行重复判断,我们用一个模拟容器来模拟去重,
从容器里找user_id = 1的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 1的数据放入,用于下条去重
(2)当user_id = 2的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现没有,不重复,所以通过我们把count+1,然后把0的数据放入,用于下条去重
(3)当user_id = 3的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 3),
然后我们把user_id = 3进行重复判断,
从容器里找user_id = 3的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 3的数据放入,用于下条去重
(4)当user_id = 4的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现重复,是之前user_id = 2的时候过if()转化成0的那条数据,所以count不执行
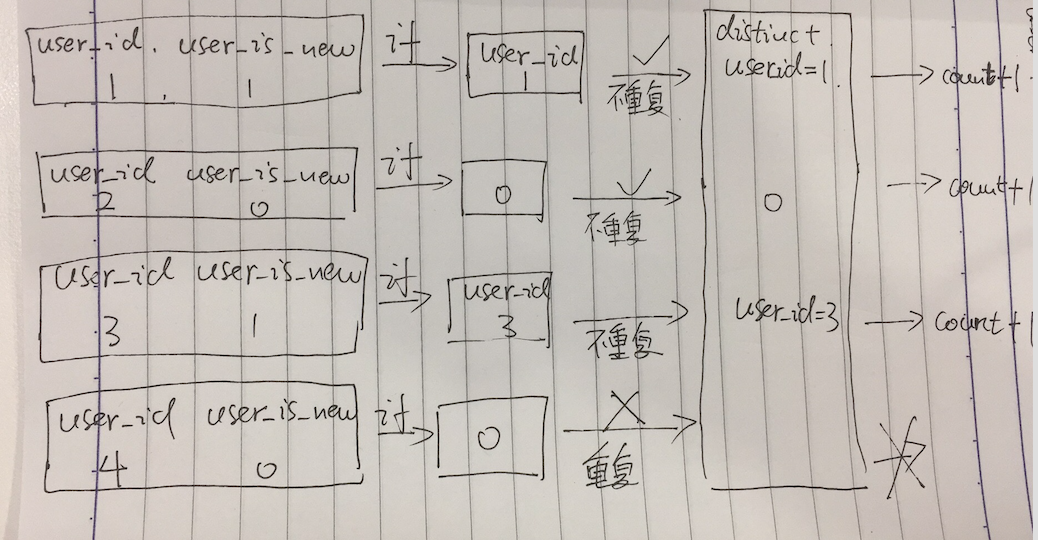
我们通过模拟count(distinct if)过程发现,在count的时候我们把不符合条件的最开始的那条语句也count进去了一次
导致最终结果比正确结果多了1.
我们在原基础语句上再减去1就是正确的hql语句
其实在日常中我们做分类筛选统计的时候一般是用sum来完成的,符合条件sum+1,不符合条件sum+0
select partition_date,count(user_id),
sum(if(user_is_new = 1, 1, 0)) --用sum进行筛选统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 260
sum(if)只试用于单个条件判断,如果筛选条件很多,我们可以用sum(case when then else end)来进行多条件筛选
注意,hive中并没有sum(distinct col1)这种使用方式,我们可以使用sum(col) group by col来达到相同效果.