Google File System
思维导图
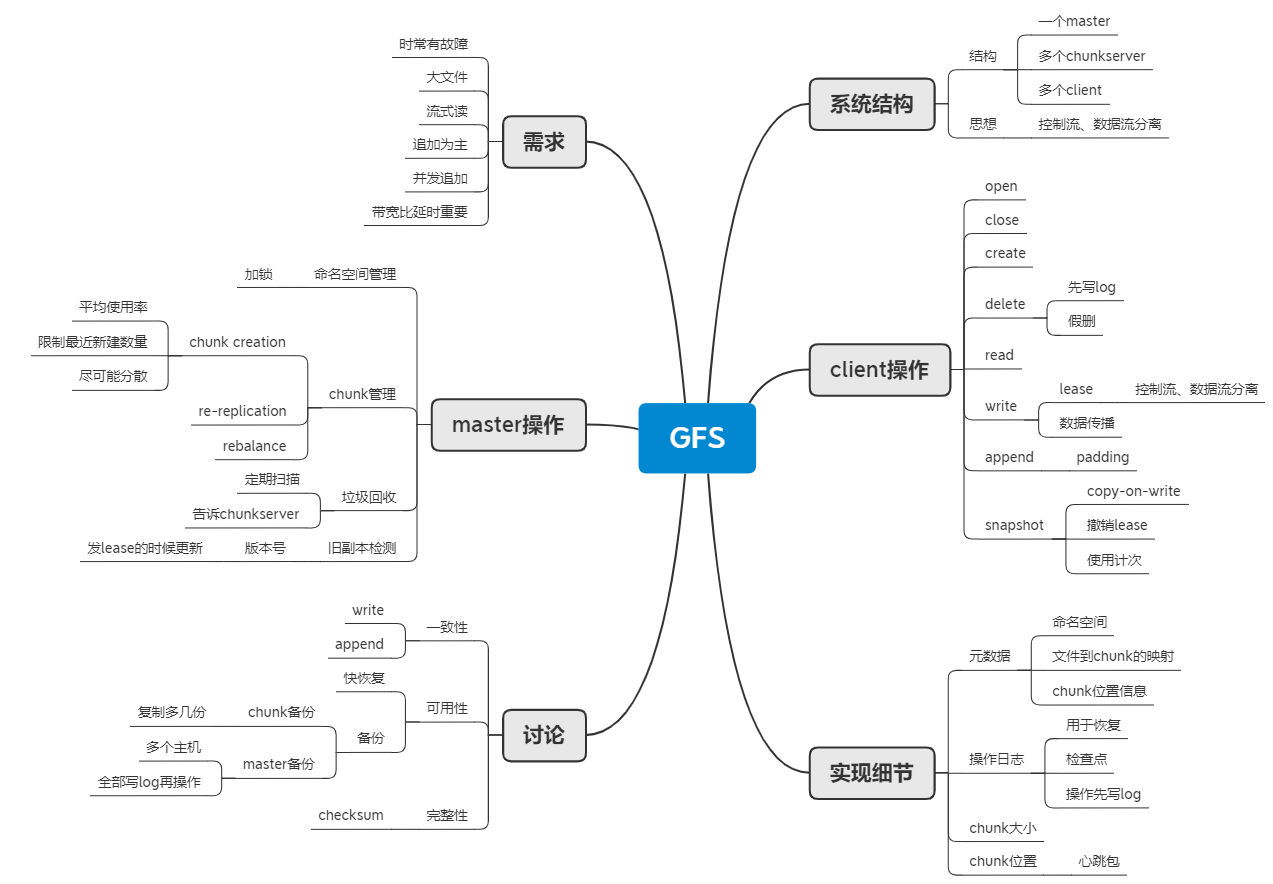
关键词
Master-Chunkserver-Client, Lease-Primary, 心跳包, snapshot-cow 引用计次, 元数据, Log-检查点, 版本号 version number, 垃圾回收, chunk 分配, 一致性-consistency, 可用性-replication, 完整性-checksum,
需求
- 故障时常发生,它要能检测到故障,能容错,能快速恢复。
- 存储大量大文件,能高效管理大文件,支持小文件,但不必优化
- 读取文件只要有两种,大数据量的流式读,小数据量的随机读
- 修改文件主要是追加到文件尾,支持随机写入,但不必要求高效
- 支持多个客户端同时追加内容到文件尾
- 带宽比延时更重要
概念
snapshot:
快速创建文件或目录的副本。
namespace:
文件的命名空间,理解为文件路径,包括文件名字。
lease:
使用 lease 来保证多个副本上的修改一致性,当修改文件时,Master 指定一个副本为 Primary,给它发一个 lease,由Primary控制其他副本以保持修改一致。设计的目的是减少 Master 的管理。
整体结构
结构图:
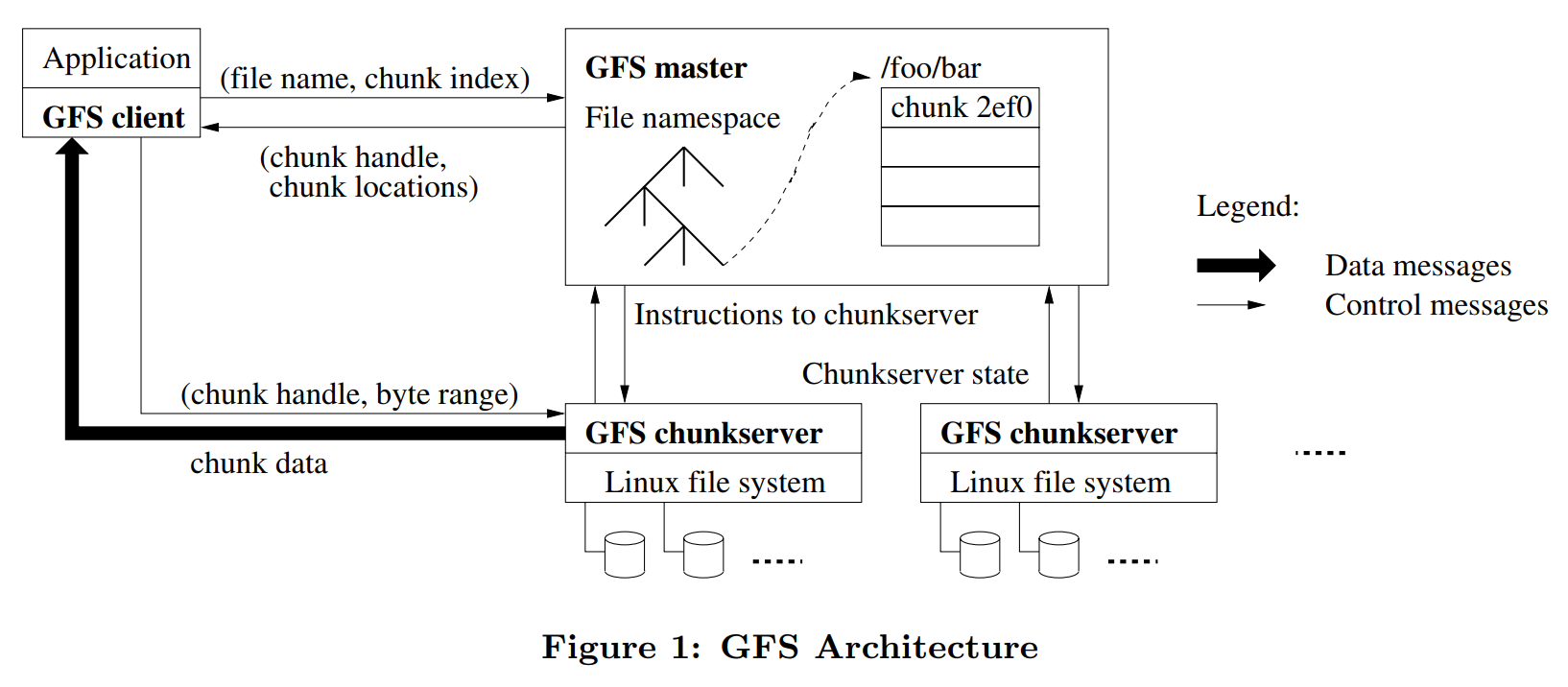
一个 GFS Master,多个 GFS chunkserver,多个 GFS client 同时操作。设计时需要尽可能减少与 Master 之间的交互,避免 Master 成为性能的瓶颈。GFS 最重要的思想是数据流 data flow 和 控制流 control flow 的分离。client 和 master 交互只为了获取元数据, 所有数据传输在 client 和 chunkserver 之间进行。
既然是文件系统,那么最应该关心的问题是文件如何存储。GFS 中将文件分成固定大小的 chunks。每个 chunk 在创建的时候,指定一个 chunk handler,它不可变且唯一,长度为 64bit。在 chunkserver 上,将 chunk 保存为普通的 Linux 文件。为了可靠性,每个 chunk 会创建多个副本,GFS 中是 3 个。
master:
维护元数据,元数据包括命名空间,访问权限,文件和 chunk 的映射,chunk 的当前位置;系统级别的操作有 lease 管理,垃圾回收,chunk 管理,获取 chunkserver 的状态。
chunkserver:
保存 chunk,用心跳包向 master 报告状态,接受 master 和 client 的控制信息。
clinet:
从 master 获取元数据,操作 chunkserver 上的 chunk,支持 open, close, create, delete, read, write, append, snapshot 操作。
接口实现细节
读取
- client 将发送 (filename, chunk index) 到 master
- master 返回 (chunk handler, chunk locations) 给 client
- client 缓存以 (filename, chunk index) 为键的返回信息,缓存在过期或重新 open 的时候刷新。
- client选择最近的 chunkserver 发送 (chunk handler, byte range)。
- chunkserver 返回数据
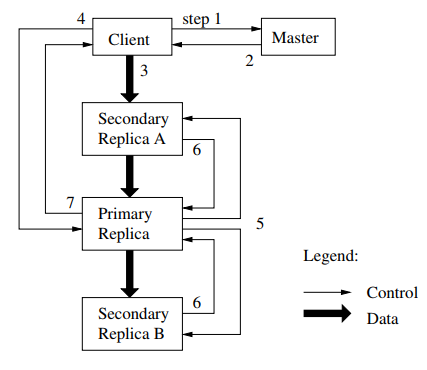
写入
- client 向 master 请求拥有想要写入的 chunk 的副本,其中一个拥有 lease。
- master 接收到请求,如果没有副本有 lease,master 就发一个。master 回复 client 拥有这个 chunk 的 primary 和其他副本。在 primary 不可达或者 lease 过期的时候,client 会重新向 master 请求。
- client 将数据推送到每一个副本,chunkserver 将数据放在 LRU缓存中(LRU:最近最少使用)。为了充分利用每台机器的网络,可以做出如下改进:副本收到数据之后,向没有这个数据的最近副本转发。
- client 向 primary 发送控制信息,要求写入数据。primary 为收到的所有写入请求编号,primary 在本地按照编号写入数据。
- primary 发送写入请求给副本,要求副本按照同样的顺序执行写入操作。
- 副本回复 primary。
- primary 回复 client。如果有副本没有写入成功,那么修改区域将处于不一致状态,client 重新请求写入,执行 3~7 步。
追加
类似写入操作,但有如下几点区别:
- client 将数据推送到拥有最后一个 chunk 的副本。
- primary 会检查追加到这个 chunk 后,是否会超过 chunk 的大小。
- 如是,所有副本填充空白数据直到文件尾,让 client 重新执行同样的追加操作。
- 追加数据未超过 chunk 大小,primary 让其他副本写入同样的位置。
- 追加数据的大小,要求不超过四分之一的 chunk 大小
快照
实现机制是 copy-on-write
- 当 master 接收到了快照请求,master 撤销这个文件所有 chunks 上的 lease。
- 为了创建快照,master 需要修改元数据。在 lease 撤销或者过期后,先向 log 写入快照操作,再复制快照文件或文件夹的元数据。
- 当 master 接收到了有快照的 chunk 修改请求,chunk 的引用次数加1,master 先让chunkserver 本地复制 chunk,再进行修改。(即 copy-on-write)
删除
- 先写 log,再操作
- 进行假删,将文件重命名
- master 进行文件系统扫描时,清理掉超过一定时间的假删文件
其他:打开、关闭、创建,这些都没有提及,网上也找不到资料,只能斗胆猜猜,按照 POSIX 的规定,去猜实现。打开,master 返回文件是否存在等。关闭,猜不到能干什么。创建,master 新增文件的元数据,同样是先写 log 再操作,还需要在副本上创建新的 chunk。
master实现细节
元数据 Metadata
元数据包括命名空间、文件到 chunk 的映射、chunk 的位置信息。前两者保存到本地,由检查点和日志完成。chunk 的位置信息,master 通过向 chunkserver 拉去信息来获得,chunkserver 向master 发送心跳包来发送 chunk 的位置信息。
操作日志
用来记录使元数据变化的操作,日志是元数据操作的持久化存储,日志保存到本地,同时发送到远程的备份机器,可以用于 master 的修复。为了保持日志不超过一定大小,可以使用检查点。master 新建一个日志,同时开一个新的线程来保存检查点的状态,方法应该是将B树复制到一段连续的内存,复制完毕后整个保存到硬盘。连续的目的是为了加载的时候,可以直接映射进来。(这里还有一个问题没搞清楚,看Q&A)
chunk 大小
GFS选择了64MB,当时应该算是比较大的了。选择大的 chunk size,优缺点如下:
优点。一,减少了 client 和 master 的交互,需要 chunk 越大,client 请求的 chunk 次数越少。二,减少了 client 和 chunkserver 的通信开销,chunk 越大,请求的操作越可能在同一个 chunk,因此也越可能在同一个 chunkserver 上。三,元数据的占用空间减少。
缺点。不能负载均衡。chunk 大,有些文件只有一个 chunk,那么存储的 chunkserver 容易成为热点,因为客户端为了请求同一个文件,只能向这些 chunkserver 发出请求。解决方法是,复制多几份。
chunk 位置
chunk 的位置信息,master 通过向 chunkserver 拉去信息来获得,chunkserver 向master 发送心跳包来发送 chunk 的位置信息。
这么做,原因有二:一,主机很多,状态经常改变,简化 master 的设计。二,是否拥有一个 chunk,是 chunkserver 说了算。
master操作细节
namespace 管理和加锁
不像传统的文件系统那样搞一个分层结构,GFS将 namespace 存储为查询表,将路径名映射到元数据。操作之前要加锁,防止死锁的方法为:顺序加锁。
chunk 管理
新建 chunk,需要考虑三个因素。一,将新建的 chunk 放到平均存储少的 chunkserver。二,限制最近新建 chunk 的数量,避免成为热点。虽然新建 chunk 几乎不耗费资源,但是可以预知到新建 chunk 之后会有大量写操作。三,尽可能在分散。如果都放在一个架子上的 chunkserver,这架子的供电或网络出了问题,那么这些 chunkserver 都得出问题。
新建副本。当一个 chunk 的副本少于一定数量的时候,新建副本。
定期平衡副本的分布,可以负载均衡。
垃圾回收
用心跳包和 chunkserver 交换信息,并告诉 chunkserver 哪些文件不在存在。
有如下好处:一,垃圾回收机制提供了清除无效副本的方法。GFS 运行在很多台机器上,难免会发生各种故障。在新建 chunk,删除 chunk 的时候,都有可能发生错误。新建的 chunk 在某些副本上成功,但是存在失败,所以这些 chunk 是 master 不知道不需要的。因此可以用垃圾回收机制回收起来。二,时间自由。将垃圾回收机制运行在后台,定期扫描文件系统,清除不要的东西。在系统比较空闲的时候,就可以开始垃圾回收。三,防止误删。
旧副本检测
给 chunk 加版本号,当回复客户端的修改请求时,给 chunkserver 发 lease 的时候,版本号加1,且回复客户端有效的 chunkserver。master 会忽视过期的 chunk,并在垃圾回收的时候清理掉。
其他细节
缓存
对于数据文件,client 和 chunkserver 都不缓存。client 不缓存因为大多数应用是大文件的流式读,放不下或者没必要。chunkserver 不缓存,因为这个事情交由操作系统来做。
对于元数据文件,client会缓存下来。
讨论
一致性
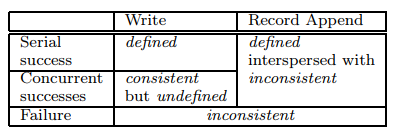
consistent:A file region is consistent if all clients will always see the same data, regardless of which replicas they read from. 所有副本上的数据一致。
defined:A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety. 在一致的基础上,要求客户端能够看到自己写入的”全部”内容。
serial write,一个一个地写,结果是确定的。
concurrent write 的结果可能是混杂着各个线程请求写入的东西,但是成功写入后,内容是一致的,但是客户端看不到自己写入的全部内容。
record append,请看 Q&A。
Failure,部分 chunkserver 成功,部分 chunkserver 失败,这意味着存在不一致的内容。
论文只分析了改写和追加,这里再分析一下 GFS 的其他操作:open, close, create, delete, snapshot. open 和 close不会改变数据,因此不管成功失败都是一致的。create 成功,保持一致;create 失败,部分 chunkserver 新建了 chunk,部分 chunkserver 没有新建 chunk,因此造成了不一致。delete 不管成功失败,都是一致的,因为 delete 仅修改了元数据。snapshot 成功失败都是一致的,仅修改元数据。
可用性
主要靠两个策略,快恢复和副本。
chunk 复制多几份到 chunkserver 上,一旦检测到错误或者 chunkserver 不可用,master 会复制 chunk。master 将日志和检查点复制到几个机器上,在进行一个操作之前,等待所有操作都写入到本地日志和远程主机上时,才真正执行。当检测到 master 故障了,在备份主机上启动 master 进程。此外还引入 shadow master,用于只读访问。在 master 掉线的时候,shadow 仍然可用。shadow 通过读取日志来保持和 master 一致,并且偶尔和 chunkserver 交换信息。
完整性
使用 checksum 来保持数据完整性。
每个 chunkserver 维护自己数据的 checksum,因为并不是所有的 chunk 都是一致的,追加操作会使到数据不一致。
追加操作时,更新最后一个 block 的 checksum,和计算所有新增的 block 的 checksum。因为追加操作是频繁的操作,所以这里不先检验原来的最后一个 block 是否正确,以此来减少计算耗时。当那个 block 确实存在错误的时候,要求能检测到错误。我猜想方法应该是在原来的 checksum 上面,迭代更新 checksum。
写入操作的时候,写入区域的头和尾 block 需要先检验是否正确,再执行写入,然后计算写入区域覆盖的所有 block 的 checksum。
Q&A
Q:流式读取 streaming reads 和 随机读取 random reads 的区别?
A:流式读取文件指针只能从头读到尾;随机读取文件指针可以任意移动。
Q:Copy-on-write 是什么?
A:Copy-on-write (sometimes referred to as "COW") is an optimization strategy used in computer programming. The fundamental idea is that if multiple callers ask for resources which are initially indistinguishable, you can give them pointers to the same resource. This function can be maintained until a caller tries to modify its "copy" of the resource, at which point a true private copy is created to prevent the changes becoming visible to everyone else. All of this happens transparently to the callers. The primary advantage is that if a caller never makes any modifications, no private copy need ever be created. (https://stackoverflow.com/questions/628938/what-is-copy-on-write)
应用举例,有一个类内部有一个容器,创建这个类的拷贝时,不复制容器。原对象和拷贝对象的容器指向同一个地方。当拷贝对象需要修改容器内容的时候,再Copy。它的初衷是明显的,如果共享的资源一直不修改,那么没有必要去创建一个副本。当要修改的时候,复制后再修改。
Q:表中的defined interspersed with inconsistent是什么意思?
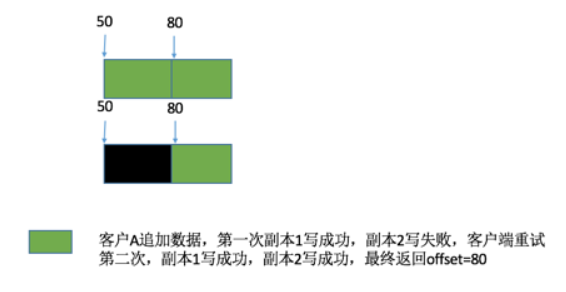
A:可以理解为修改区域是defined,客户端将会看到修改的全部内容。interspersed with inconsistent的意思是可能造成别的区域的不一致。扩展操作的时候,将内容直接写入到 chunk 尾部。如果写入的时候,有副本没有成功,那么 primary 将会返回失败给 client。client 重新调用扩展操作,那么此时将扩展到尾部,这个尾部是之前写入失败后的尾部。那么在第一次写入的那段区间里,内容就是不一致的。在第二次写入的那段内容里,内容是确定的。Write 就不会有这个问题,因为 Write 操作需要指定 offset。参考[3]
Q:论文2.6.3节中,如何实现创建新的检查点而不用 delay 修改?如果接受了修改请求,那么将在哪里做出修改?
A:将操作放到 log 中,等到检查点建立完毕,执行 log 的东西
Q:论文 2.5 节中,什么是lazy space allocation?如何避免internal fragmentation?
A:With lazy space allocation, the physical allocation of space is delayed as long as possible, until data at the size of the chunk size (in GFS's case, 64 MB according the 2003 paper) is accumulated[4]. 当积累了足够多的分配请求的时候,才进行真正的空间分配。内部碎片是将空间分配过去,但是使用者占用了那些空间却不使用。因此 lazy allocation 策略确实可以避免 internal fragmentation。其实 2.5 节想要说的是,这样的一个策略阻碍了使用如此大的 chunk size。
Q:Why is atomic record append at-least-once, rather than exactly once?
A:首先搞清楚问题,append at-least-once,至少 append 一次。如果我 append 成功了,所有副本都 defined,那我还需要 append 吗?不用!干嘛多次一举。at-least-once 是至少一次,失败就继续 append,直到成功为止。exactly once 的意思是,append 失败了,我不再进行 append 操作,而是在原来 append 失败的区域上进行修正,使到结果是 defined。
Q:How does an application know what sections of a chunk consist of padding and duplicate records?
A:padding,使用 checksum 或者在 record 开头放一个 magic number;duplicate,使用唯一的 ID。
Q:application 如何读取数据呢?
A:按照 record 来读取,因此如果读取的 record 是 padding 或者 duplicate,application 可以通过 record 头部的信息来检验。
Q:The paper mentions reference counts -- what are they?
A:snapshot 中用来实现 copy-on-write 的变量,当创建一个 snapshot 的时候,给每个 chunk 添加一个引用计次。当在修改一个 chunk 的时候,先检查引用计次是否大于 1,如是,则先创建一个 chunk 的拷贝,再进行修改。
Q:Suppose S1 is the primary for a chunk, and the network between the master and S1 fails. The master will notice and designate some other server as primary, say S2. Since S1 didn't actually fail, are there now two primaries for the same chunk?
A:成为 primary 的前提是,拿到 lease。因为 lease 的有效时间是 60s,master 可以 S1 的 lease 过期,再给 S2 发 lease。
Q:Did having a single master turn out to be a good idea?
A:性能将成为瓶颈,比如内存大小将会限制元数据的大小,CPU的速度将会限制客户端的数量。
Q:Describe a sequence of events that result in a client reading stale data from the Google File System
A:chunkserver 经历了重启,在重启期间更新了一个 chunk 的数据,而这个 chunkserver 错过了;client 缓存了 chunk 的位置信息,且未过期。于是 client 读取到了 chunkserver 上过期的信息。
参考链接
[1] https://zhuanlan.zhihu.com/p/33944479
[2] https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/gfs.pdf
[3] https://zhuanlan.zhihu.com/p/28155582
[4] https://stackoverflow.com/questions/18109582/what-is-lazy-space-allocation-in-google-file-system