写在前面:自学apue,时间有限,这个系列都是抽时间写的,目前已经看到15章,现在从头做题,如有错误还请指教。
apue3.1:
write和read这样的函数都属于系统调用,这里具体所指的没有缓冲区是没有用户缓冲区,而不是指没有内核缓冲区,这里以我个人的认识认为,这里write和read将数据拷贝到缓冲区后并不直接写到文件中,而是等一定条件发生后才写进去,但是具体机制还需研究。同时这里也暴露了一个问题,每次进行I/O都需要进行系统调用,这无疑是对系统资源的一种浪费,所以这也为后来的标准I/O函数库的产生做了铺垫。
apue3.2:
先上代码:
#include "apue.h" #include <stdio.h> #include <fcntl.h> int dup2_self (const int ofd , const int nfd) ; int main () { int fd; int flag; fd = open ("tempfile" , O_RDWR | O_CREAT | O_TRUNC); flag = dup2(0 , fd); write (fd , "hello " , 6); } int dup2_self (const int ofd , const int nfd) { char *fdptr; int openmax = sysconf (_SC_OPEN_MAX); int tempfd; int count = 0; int fdarr[openmax]; int i; if (ofd > openmax || nfd > openmax) { fprintf (stderr , "the arguement error "); exit (1); } fdptr = malloc (30 * sizeof (char)); sprintf (fdptr , "/proc/%d/fd/%d" , getpid() , ofd); if (access (fdptr , 0) < 0) { fprintf (stderr , "the ofd is not open "); exit (2); } sprintf (fdptr , "/proc/%d/fd/%d" , getpid() , nfd); if (access (fdptr , 0) < 0) { fprintf (stderr , "the nfd is not open "); exit (3); } if (nfd == ofd) return nfd; close (nfd); while (tempfd = dup (ofd)) { if (tempfd == nfd) break; else fdarr[count++] = tempfd; } printf ("%d " , nfd); for ( i = 0 ; i < count ; i++) close (fdarr [i]); return nfd; }
这段代码显然无法做到dup2的原子性,但是在功能上至少可以实现所需要的功能,当然可靠性我也没有非常多的验证,这个最近本的实现让我弄清楚了很多问题:第一——dup2的使用规则,其实就是将文件描述符和文件描述标志的关系去掉,重新引导到另外一个文件描述标志中上。第二——dup的使用方法,它总是返回最小的可用的文件描述符值,比如在这里nfd(这里我在linux上将这个值打印出来是3)已经close后,再dup后就直接还是3,可见close掉后还是可用的文件描述符。第三——如何查看一个进程所打开的文件描述符在/proc/pid/fd/#就可以。最后结果就是我往main中的fd write的时候,它会在标准输出显示。
——————————————————————————————————————————————————分割线2016.6.1
apue3.3:
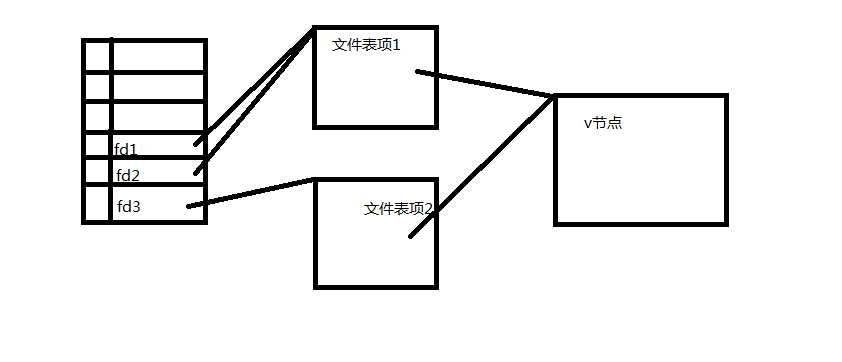
这里我可以很容易的看见dup的作用是将函数返回的文件标志指向和自己一样的文件表项,而open的作用是使得函数返回的描述符指向另外一个文件表项,但是两者都会指向同一个V节点,那么这两者有什么不同吗?答案是,文件表项中拥有文件状态标识,当前文件的偏移,也就是说,假设现在fd1 fd2 fd3都在文件开头位置,如果我向fd1中写入一定字节后,再向fd2写入一定字节那么fd2的字节会显示在fd1后面,这时我再向fd3中写一定字节后就会覆盖前两个描述符的字节。F_SETFD这里的作用是设置文件描述符标识,而这里只有一个值,FD_CLOEXEC,属于每个文件描述符的属性。而F_SETFL则是和文件状态标识有关系,这个值在文件表项当中的。所以很容易看出fcntl fd1时F_SETFD只影响其自身。F_SETFL则影响fd1和fd2.
apue3.4:
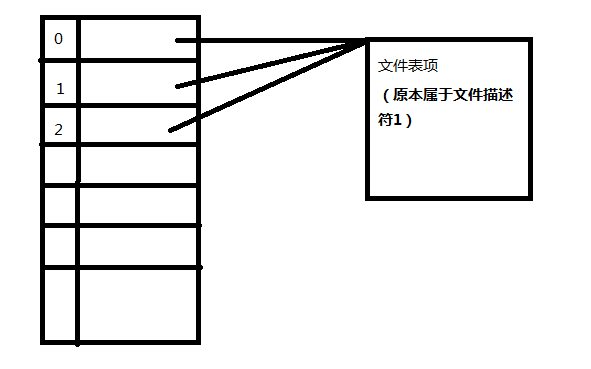
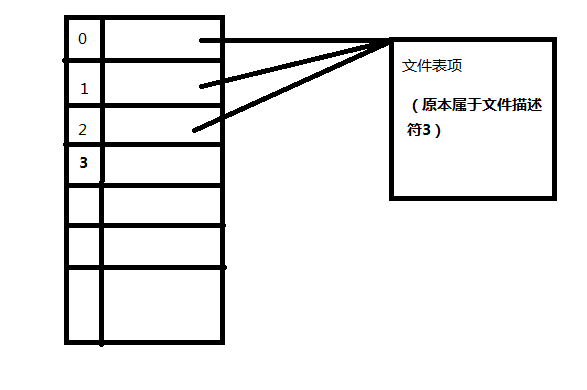
这里我只给出两种情况最后的图,前者是fd的值为1时的情况,后者是fd的值为2的情况。具体原因不在赘述,能弄清dup2_self的实现,这种题目就是水到渠成。
——————————————————————————————————————————————————分割线2016.6.2
apue3.5:
这道题目是很有趣的一道题目,这个问题其实从根本上让我们认识清楚了shell命令行中的重定向到底是怎么进行的,其实就是修改标准输入输出,标准错误的文件描述符的指向,文件描述符指向shell制定的文件的文件表项。地一个例子是首先将标准输出指向outfile的文件表项,再将标准错误的指向标准输出的文件表项,其结果就是两者都指向了同一个文件表项就是outfile的文件表项。第二个例子,首先将标准错误的文件表项指向标准输出的文件表项,这一步之后两者都指向终端的标准输出,后面再将标准输出指向outfile文件的表项,其结果就是两者指向不同的文件表项。
apue3.6:
先上代码:
/************************************************************************* > File Name: apue3_6.c > Author: jeff zhu > Mail: 908190355@qq.com > Created Time: 2016年06月03日 星期五 12时53分05秒 ************************************************************************/ #include "apue.h" #include <fcntl.h> //#define TEST_RD #define TEST_WR int main () { int fd; char buf[1024]; int n; char flag[] = "write ok "; if ((fd = open ("testfile" , O_RDWR | O_APPEND)) < 0) err_sys ("open error"); if (lseek (fd , 0 , SEEK_SET) < 0) err_sys ("lseek error"); #ifdef TEST_RD while ((n = read (fd , buf , 1024)) > 0) if (write (STDOUT_FILENO , buf , n) != n) err_sys ("write error"); if (n < 0) err_sys ("write error"); #endif #ifdef TEST_WR if (write (fd , flag , strlen (flag)) != strlen (flag)) err_sys ("write error"); #endif exit (0); }
这个代码,书的作者的意图很明显,希望我们主要到这样的细节——O_APPEND的作用,书上答案的解释是,read可以任意用lseek函数指定,但是write函数即使使用lseek重新定位,但是仍然会自动定位到文件的末尾将只能的内容写到文件中。在我的代码中testfile是在当前文件夹中随意建的一个文件,里面有一定的内容。当进行读测试的时候可以直接将testfile文件中的内容读到屏幕上,而进行写测试的时候,却在文件尾显示"write ok",这个答案给的结果一样。这里我认为O_APPEND这样设计的原因,其实在书上3.11节已经给出了解释,这是为了多进程的考虑,当出现竞争条件的时候,这样的设计不至于出现进程之间相互覆盖的情况。
——————————————————————————————————————————————————分割线2016.6.3
写在后面:哈哈,第三章已经更新完了。