1. Wireshark对C插件的支持
每个解析器解码自己的协议部分, 然后把封装协议的解码传递给后续协议。
因此它可能总是从一个Frame解析器开始, Frame解析器解析捕获文件自己的数据包细节(如:时间戳), 将数据交给一个解码Ethernet头部的Ethernet frame解析器, 然后将载荷交给下一个解析器(如:IP), 如此等等. 在每一步, 数据包的细节会被解码并显示.
可以用两种可能的方式实现协议解析. 一是写一个解析器模块, 编译到主程序中, 这意味着它将永远是可用的. 另一种方式是实现一个插件(共享库/DLL), 它注册自身用于处理解析。
插件形式和内置形式的解析器之间的差别很小. 在Windows平台, 通过列于libwireshark.def中的函数, 我们可以访问有限的函数, 但它们几乎已经够用了.
比较大的好处是插件解析器的构建周期要远小于内置. 因此以插件开始会使最初的开发工作变得简单, 而最终代码的布署会和内置解析器一样。
另见 README.developer 文件doc/README.developer包含更多有关实现解析器(而且在某些情况下, 比本文档要新一些)的信息.
2. 编译构建C解析器
首先需要决定解析器是要以built-in方式,还是以plugin方式实现。plugin方式实现比较容易上手。
解析器初始化:
#include "config.h" #include <epan/packet.h> #define FOO_PORT 9877 static int proto_foo = -1; void proto_register_foo(void) { proto_foo = proto_register_protocol ( "FOO Protocol", /* name */ "FOO", /* short name */ "foo" /* abbrev */ ); }
首先include一些必需的头文件。proto_foo用来记录我们的协议,当将此解析器注册到主程序时,它的值将会更新。把所有非外部使用的变量和函数声明为static是一个好的编程实践,可以避免名字空间污染。一般情况下这不是问题,除非我们的解析器非常大,分成了多个文件。
我们#define了协议的UDP端口FOO_PORT。
现在我们已经有了与主程序交互所需的基本东西了。接下来实现2个解析器构建函数(dissector setup functions)。
首先调用proto_register_protocol()函数来注册协议。可以给它3个名字用来将来在不同的地方显示。比如full和short name用于“Preferences”和“Enabled protocols”对话框。abbrev name用于显示过滤器。
接下来我们需要handoff例程。
void proto_reg_handoff_foo(void) { static dissector_handle_t foo_handle; foo_handle = create_dissector_handle(dissect_foo, proto_foo); dissector_add_uint("udp.port", FOO_PORT, foo_handle); }
首先创建一个dissector handle,它和foo协议及执行实际解析工作的函数关联。接下来将此handle与UDP端口号关联,以便主程序在看到此端口上的UDP数据时调用我们的解析器。
标准wireshark解析器习惯是把proto_register_foo()和proto_reg_handoff_foo()做为解析器代码的最后2个函数。
最后我们来编写一些解析器代码。目前将它做为基本的占位符。
static void dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree) { col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO"); /* Clear out stuff in the info column */ col_clear(pinfo->cinfo,COL_INFO); }
此函数用于解析交给它的packets。packet数据放在名为tvb的特殊缓存中。对此随着我们对协议细节了解的深入将会变得非常熟悉。packet_info结构包含有关协议的一般数据,我们应该在此更新信息。tree参数是细节解析发生的地方。
现在我们进行最小化的实现。第1行我们设置我们协议的文本,以示用户可以看到协议被识别了。另外唯一做的事情是清除INFO列中的所有数据,如果它正在被显示的话。
此时,我们已经准备好基本的解析器,可以进行编译和安装了。它什么也不做,除了识别协议并标识它。
为了编译此解析器并创建插件,除了packet-foo.c中的源代码,还有一堆必需的支持文件,它们是:
- Makefile.am - This is the UNIX/Linux makefile template
- CMakeLists.txt - 使用cmake编译时所需的脚本
- Makefile.common - This contains the file names of this plugin
- Makefile.nmake - This contains the Wireshark plugin makefile for Windows
- moduleinfo.h - This contains plugin version info
- moduleinfo.nmake - This contains DLL version info for Windows
- packet-foo.h, packet-foo.c - This is your dissector source
- plugin.rc.in - This contains the DLL resource template for Windows
这些文件的例子可以在plugins/gryphon中找到,把所有与gryphon相关的东西都改成foo即可。plugin.rc.in不需要改动,windows编译不需要的文件也不需要改动。
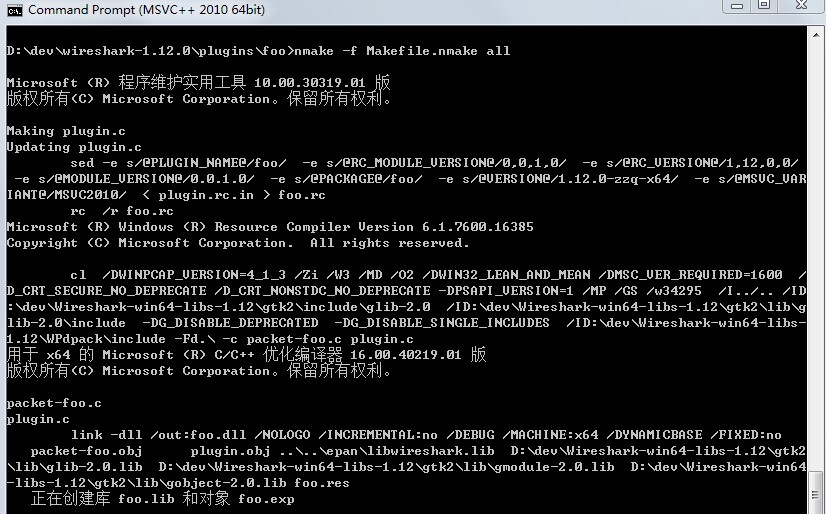
把以上文件准备好、修改好之后,cmd进入plugins/foo目录,运行
nmake -f Makefile.nmake xxx
来进行编译,就像编译wireshark源码一样。编译好之后生成foo.dll,将它拷贝到编译好的wireshark的plugins目录(可能会有中间目录,视情况)。
还可以修改plugins目录下面的Makefile.nmake文件,在PLUGIN_LIST中加入新插件的目录名,这样下次编译wireshark时会一起编译你的插件。
如果是在Mac OSX系统中编译插件(CMake方式),需要修改主目录下的CMakeLists.txt,搜索plugin字符串,找到set(PLUGIN_SRC_DIRS下面的行,在路径中加入plugins/foo(plugins目录的Makefile.am文件可能不需要修改,其中SUBDIRS项中列出了各插件的源码目录) ;然后如同之前文章所述,进入build目录,执行make –j 6 plugins,即可编译插件们。
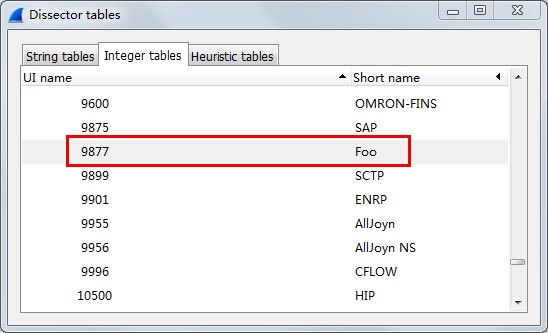
然后启动wireshark,打开Dissector Tables窗口,可以查到以下信息,说明wireshark已经正确加载我们的插件。
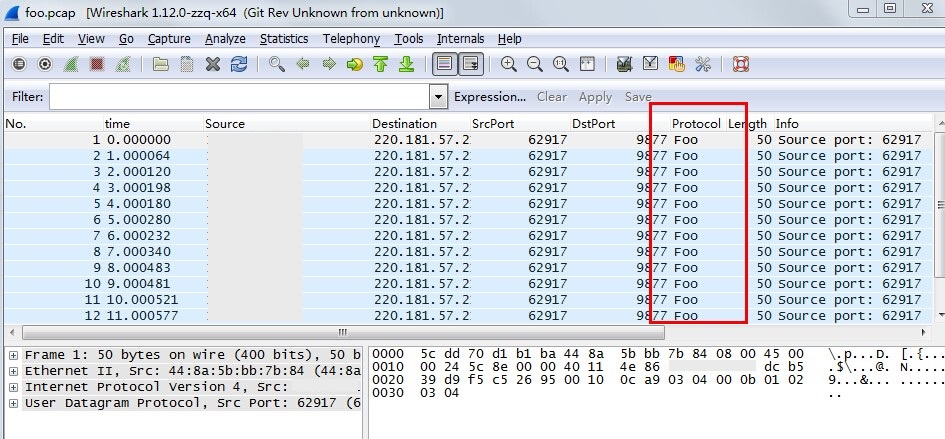
打开foo.pcap,效果如下图所示,此时没有协议解析树,只在报文列表中添加了协议名:
3. 完善C解析器
接下来可以做一些复杂一点的解析工作。最简单的事情是对载荷进行标记。
首先创建一个subtree用来放解析结果。这有助于在detailed display中更佳显示。对解析器的调用有2种情况。一种情况用于获取packet的摘要,另一种情况用于解析packet的细节。这两种情况由tree指针的不同来区别。如果tree指针为NULL,用于获取简略信息。如果是非NULL,则需要解析协议的各个细部。记住这些后,让我们来增强我们的解析器。
static void dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree) { col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO"); /* Clear out stuff in the info column */ col_clear(pinfo->cinfo,COL_INFO); if (tree) { /* we are being asked for details */ proto_item *ti = NULL; ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA); } }
这里所做的是把一个subtree加入到解析中。此subtree会保存此协议的所有细节,且不会在不需要时弄乱显示。
我们还可以标记被此协议所消费的数据区域。在目前的情况下,这统治是传递过来的所有数据,因为我们假定此协议不再封装其他协议。因此,我们用proto_tree_add_item()往tree里添加新的节点,标识它的协议名,用tvb缓冲区做为数据,并消费此数据的0到最后1个字节(-1表示结束)。ENC_NA(not applicable)是编码参数。
在这些改变之后,在detailed display中就会有此协议的标识,且选中它将会高亮此packet的剩余内容。如下图所示:

现在,让我们进行下一步,添加一些协议解析。这一步我们需要创建2个表来帮助解析。这需要在proto_register_foo()函数中添加一些代码。
在proto_register_foo()的前面添加了2个static数组。这些数组在proto_register_protocol()调用之后被注册。
void proto_register_foo(void) { static hf_register_info hf[] = { { &hf_foo_pdu_type, { "FOO PDU Type", "foo.type", FT_UINT8, BASE_DEC, NULL, 0x0, NULL, HFILL } } }; /* Setup protocol subtree array */ static gint *ett[] = { &ett_foo }; proto_foo = proto_register_protocol ( "FOO Protocol", /* name */ "FOO", /* short name */ "foo" /* abbrev */ ); proto_register_field_array(proto_foo, hf, array_length(hf)); proto_register_subtree_array(ett, array_length(ett)); }
变量hf_foo_pdu_type和ett_foo也需要在此文件的前面声明。
static int hf_foo_pdu_type = -1; static gint ett_foo = -1;
现在我们可以用一些细节来增加协议的显示。
if (tree) { /* we are being asked for details */ proto_item *ti = NULL; proto_tree *foo_tree = NULL; ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA); foo_tree = proto_item_add_subtree(ti, ett_foo); proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, 0, 1, ENC_BIG_ENDIAN); }
现在解析开始看起来更加有趣了。我们开始破解此协议的第1个比特。packet起始处的一个字节数据定义了foo协议的packet type。
proto_item_add_subtree()调用往协议树中增加了一个子节点。此节点的展开是由ett_foo变量控制的。它会记住节点是否应该展开,在你在packet中移动的时候。所有后续的解析会添加到此树中,就像在接下来的调用中看到的那样。proto_tree_add_item向foo_tree添加了新项,并用hf_foo_pdu_type来控制此项的格式。pdu type是1个字节的数据,从0开始。我们假定它是网络字节序(也叫big endian),因此用ENC_BIG_ENDIAN。对于1个字节的数来说,没用字节序之说,但这是好的编程实践。
我们来看static数组中的定义细节:
- hf_foo_pdu_type - 此节点的索引
- FOO PDU Type - 此项的标识
- foo.type - 过滤用的字符串。它使我们可以在过滤器框中输入foo.type=1的语句
- FT_UINT8 - 指出此项是一个8bit的无符号整数。
- BASE_DEC - 对于整型来说,它令其打印为一个10进制数。还可以是16进制(BASE_HEX)或8进制(BASE_OCT)。
我们目前忽略结构中的其余成员。
如果此时编译并安装此插件,我们会看到它开始显示一些看起来有用的东西。
现在我们来完成这个简单协议的解析。我们需要添加更多的变量在hf数组中,以及更多的函数调用。
static int hf_foo_flags = -1; static int hf_foo_sequenceno = -1; static int hf_foo_initialip = -1; ... static void dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree) { gint offset = 0; ... if (tree) { /* we are being asked for details */ proto_item *ti = NULL; proto_tree *foo_tree = NULL; ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA); foo_tree = proto_item_add_subtree(ti, ett_foo); proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, offset, 1, ENC_BIG_ENDIAN); offset += 1; proto_tree_add_item(foo_tree, hf_foo_flags, tvb, offset, 1, ENC_BIG_ENDIAN); offset += 1; proto_tree_add_item(foo_tree, hf_foo_sequenceno, tvb, offset, 2, ENC_BIG_ENDIAN); offset += 2; proto_tree_add_item(foo_tree, hf_foo_initialip, tvb, offset, 4, ENC_BIG_ENDIAN); offset += 4; } ... } void proto_register_foo(void) { ... ... { &hf_foo_flags, { "FOO PDU Flags", "foo.flags", FT_UINT8, BASE_HEX, NULL, 0x0, NULL, HFILL } }, { &hf_foo_sequenceno, { "FOO PDU Sequence Number", "foo.seqn", FT_UINT16, BASE_DEC, NULL, 0x0, NULL, HFILL } }, { &hf_foo_initialip, { "FOO PDU Initial IP", "foo.initialip", FT_IPv4, BASE_NONE, NULL, 0x0, NULL, HFILL } }, ... ... } ...

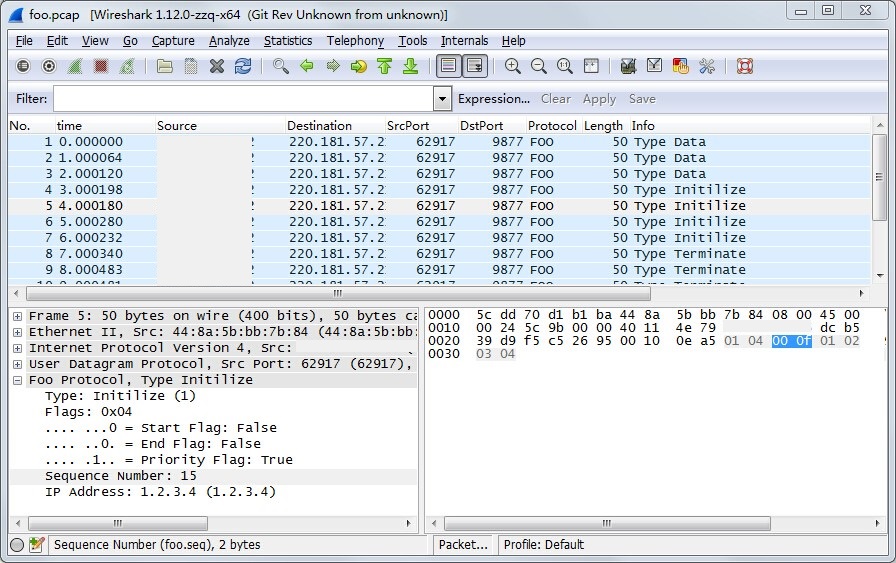
再修改一些细节,比如flag的位显示方式、foo协议树子节点字符串,packet列表中Info列的显示等等,最后效果如下:
4. 完整代码
/* packet-foo.c * Routines for Foo protocol packet disassembly * By zzq */ #include "config.h" #include <epan/packet.h> #include <epan/prefs.h> //#include <epan/dissectors/packet-tcp.h> #include "packet-foo.h" #define FOO_PORT 9877 #define FOO_NAME "Foo Protocol" #define FOO_SHORT_NAME "Foo" #define FOO_ABBREV "foo" static int proto_foo = -1; static int hf_foo_pdu_type = -1; static int hf_foo_flags = -1; static int hf_foo_seqno = -1; static int hf_foo_ip = -1; static gint ett_foo = -1; static const value_string pkt_type_names[] = { {1, "Initilize"}, {2, "Terminate"}, {3, "Data"}, {0, NULL} }; #define FOO_START_FLAG 0x01 #define FOO_END_FLAG 0x02 #define FOO_PRIOR_FLAG 0x04 static int hf_foo_start_flag = -1; static int hf_foo_end_flag = -1; static int hf_foo_prior_flag = -1; void proto_register_foo(void); void proto_reg_handoff_foo(void); static int dissect_foo(tvbuff_t*, packet_info*, proto_tree*, void*); void proto_register_foo(void) { static hf_register_info hf[] = { { &hf_foo_pdu_type, { "Type", "foo.type", FT_UINT8, BASE_DEC, VALS(pkt_type_names), 0x0, NULL, HFILL } }, { &hf_foo_flags, { "Flags", "foo.flags", FT_UINT8, BASE_HEX, NULL, 0x0, NULL, HFILL } }, { &hf_foo_start_flag, { "Start Flag", "foo.flags.start", FT_BOOLEAN, 8, NULL, FOO_START_FLAG, NULL, HFILL } }, { &hf_foo_end_flag, { "End Flag", "foo.flags.end", FT_BOOLEAN, 8, NULL, FOO_END_FLAG, NULL, HFILL } }, { &hf_foo_prior_flag, { "Priority Flag", "foo.flags.prior", FT_BOOLEAN, 8, NULL, FOO_PRIOR_FLAG, NULL, HFILL } }, { &hf_foo_seqno, { "Sequence Number", "foo.seq", FT_UINT16, BASE_DEC, NULL, 0x0, NULL, HFILL } }, { &hf_foo_ip, { "IP Address", "foo.ip", FT_IPv4, BASE_NONE, NULL, 0x0, NULL, HFILL } } }; static gint *ett[] = { &ett_foo }; proto_foo = proto_register_protocol ( FOO_NAME, FOO_SHORT_NAME, FOO_ABBREV); proto_register_field_array(proto_foo, hf, array_length(hf)); proto_register_subtree_array(ett, array_length(ett)); } static int dissect_foo(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void* data) { guint8 packet_type = tvb_get_guint8(tvb, 0); col_set_str(pinfo->cinfo, COL_PROTOCOL, "FOO"); /* Clear out stuff in the info column */ col_clear(pinfo->cinfo,COL_INFO); col_add_fstr(pinfo->cinfo, COL_INFO, "Type %s", val_to_str(packet_type, pkt_type_names, "Unknown (0x%02x)")); /* proto details display */ if(tree) { proto_item* ti = NULL; proto_tree* foo_tree = NULL; gint offset = 0; ti = proto_tree_add_item(tree, proto_foo, tvb, 0, -1, ENC_NA); proto_item_append_text(ti, ", Type %s", val_to_str(packet_type, pkt_type_names, "Unknown (0x%02x)")); foo_tree = proto_item_add_subtree(ti, ett_foo); proto_tree_add_item(foo_tree, hf_foo_pdu_type, tvb, offset, 1, ENC_BIG_ENDIAN); offset += 1; proto_tree_add_item(foo_tree, hf_foo_flags, tvb, offset, 1, ENC_BIG_ENDIAN); proto_tree_add_item(foo_tree, hf_foo_start_flag, tvb, offset, 1, ENC_BIG_ENDIAN); proto_tree_add_item(foo_tree, hf_foo_end_flag, tvb, offset, 1, ENC_BIG_ENDIAN); proto_tree_add_item(foo_tree, hf_foo_prior_flag, tvb, offset, 1, ENC_BIG_ENDIAN); offset += 1; proto_tree_add_item(foo_tree, hf_foo_seqno, tvb, offset, 2, ENC_BIG_ENDIAN); offset += 2; proto_tree_add_item(foo_tree, hf_foo_ip, tvb, offset, 4, ENC_BIG_ENDIAN); offset += 4; } return tvb_reported_length(tvb); } void proto_reg_handoff_foo(void) { static dissector_handle_t foo_handle; foo_handle = new_create_dissector_handle(dissect_foo, proto_foo); dissector_add_uint("udp.port", FOO_PORT, foo_handle); }