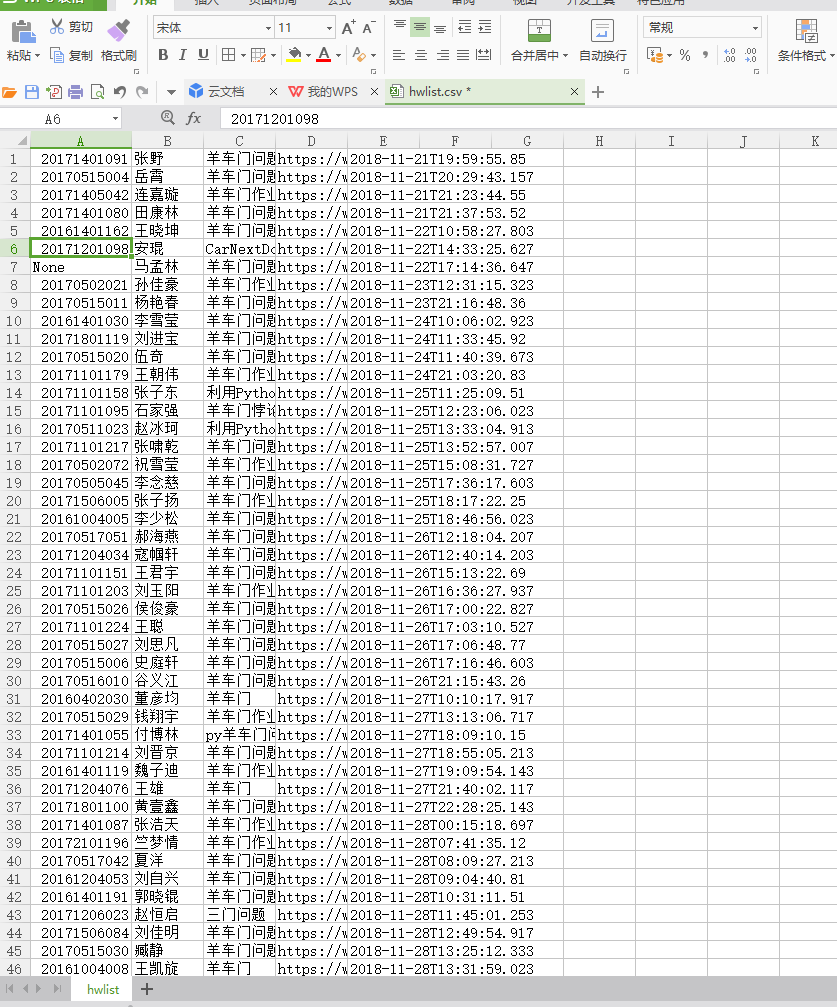
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
虽然遇到了一些问题,在他人与百度的帮助下还是解决了不少
1.scv文件的建立
with open 的使用,并从他人那得知几种打开方法 ‘’w‘’的没有就新建有就打开 ‘r'的只读
2.ImportError: No module named 'requests'(找不到requests模块)
问了几个人都用的spy,我用的python3.5运行总会出现这个,自行百度找到了一些方法解决
解决方法:由于我安装的python的时候,也选择安装了pip,所以这里只分享自己实践过的方式。我的python安装的目录是D:/Python
①cmd
②cd D:/Python
③pip install requests
等待系统自动加载安装.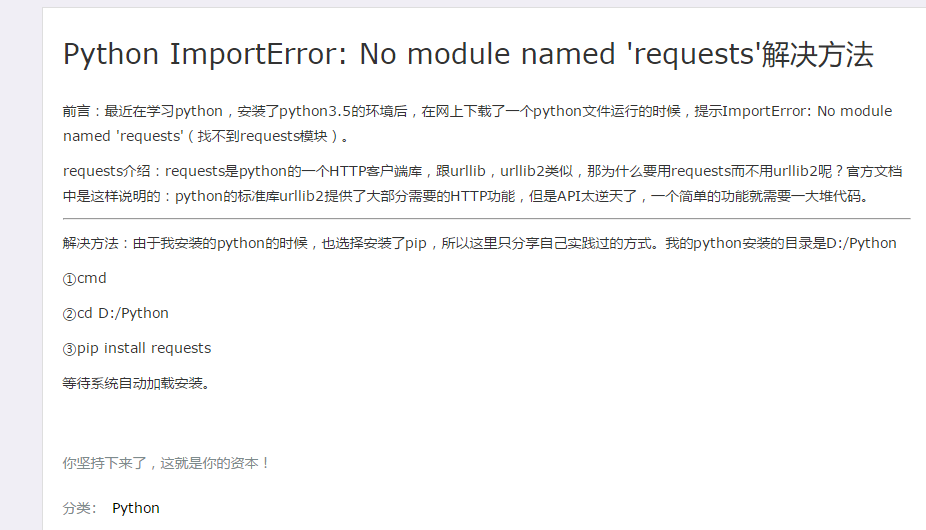
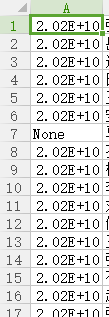
3.结果显示问题
最后代码完成的时候,打开文件,原本是学号的一行变成了如图所示的形式,询问后发现是单元格长度问题,拉长就能解决
4.keyerror
为了简短,网址直接放入get里,ST指代studentno,N指name,T指title,U指url,DA指dataadded,zzu是自己习惯使用的一串字符
但是出现了keyerror的错误,查明后是因为python字典中没有这些关键词,本想偷懒似乎不行
5.PermissionError: [Errno 13] Permission denied
百度后查明是文件打开着我又再次运行的结果
import requests import json url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743" r = requests.get(url) r.encoding = r.apparent_encoding datas = json.loads(r.text)['data'] print(datas) with open('G:\hwlist.csv','w') as zzu: for index in datas: final=str(index['StudentNo'])+','+index['RealName']+','+index['Title']+','+index['Url']+','+index['DateAdded']+' ' zzu.write(final)
6.最后效果(本来是要考虑报错问题的,鉴于题目需求没有插上,时间也不怎么够,选做任务只能留着解决了,还是在许多人帮助下完成的)