20162311 实验三-查找与排序 实验报告
目录
一、查找与排序-1
(一) 实验目的

(二) 实验过程
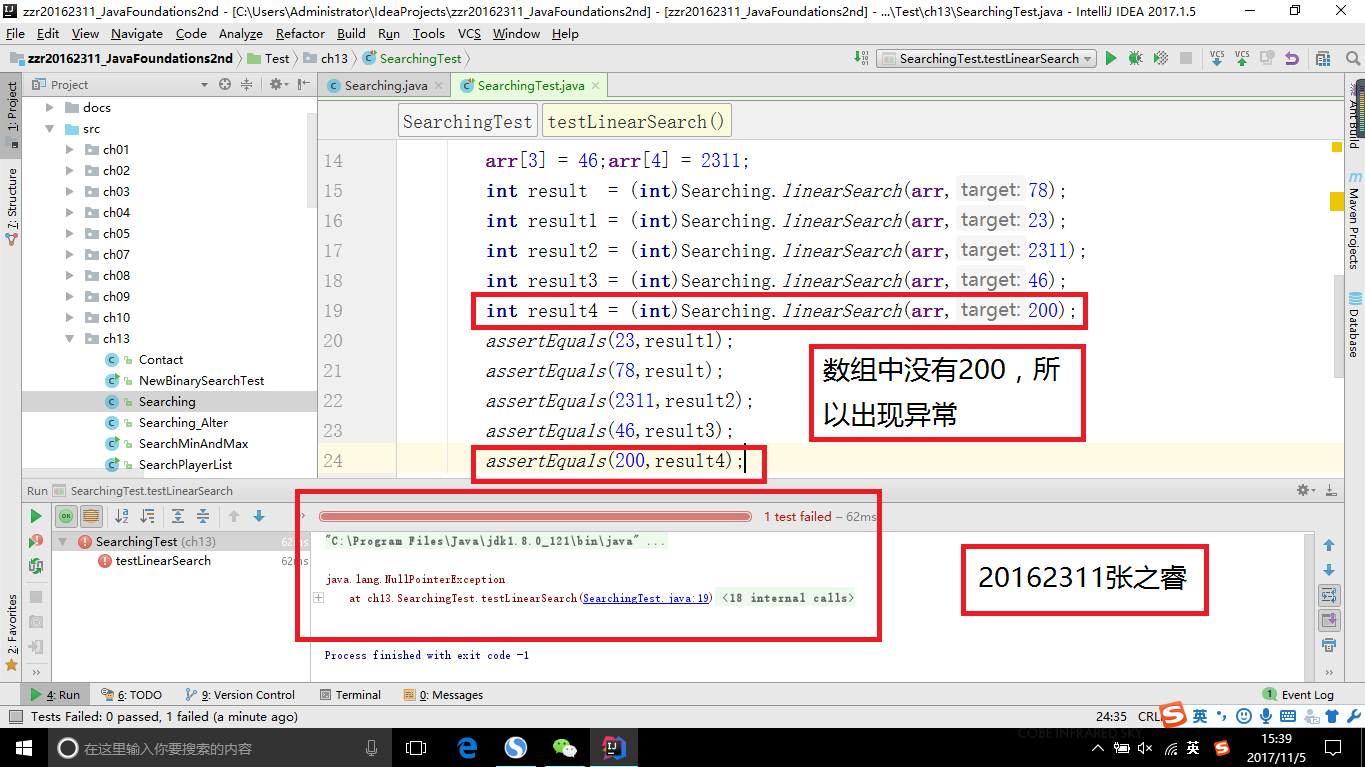
Searching.java和Sorting.java是书上已经写好的类,只需进行junit测试就行。为了体现查找的异常情况,我在线性查找中添加了一个在数组中不存在的测试用例,二分查找则通过逆序(即降序)来体现异常情况
测试截图
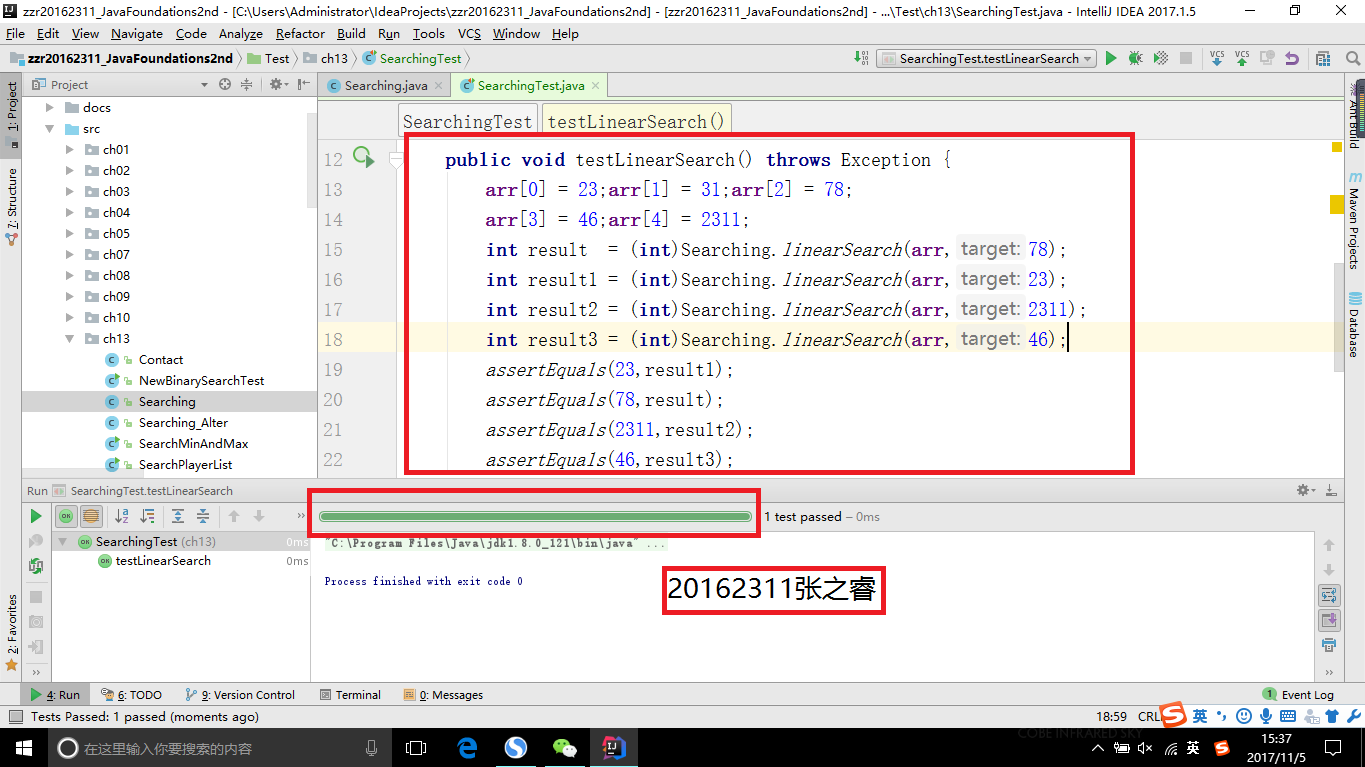
- 线性查找正常
- 线性查找异常
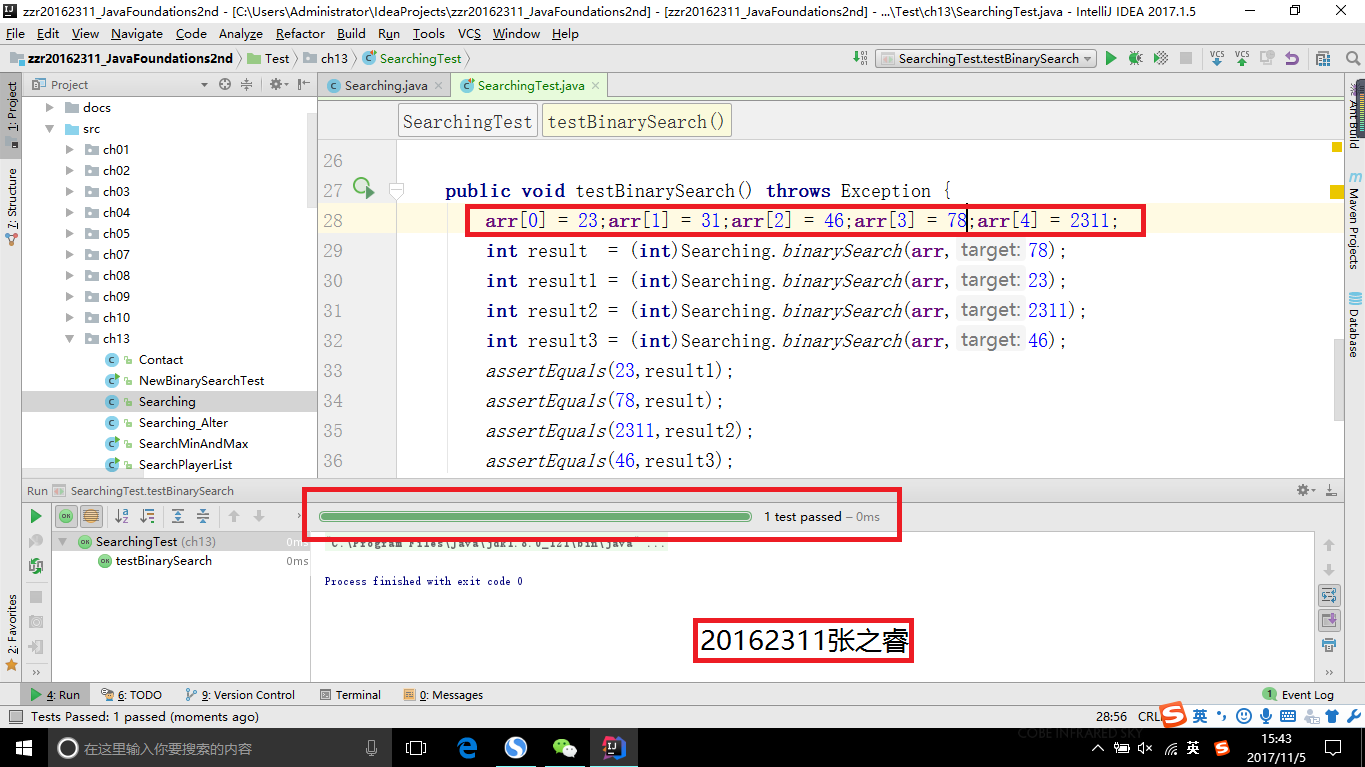
- 二分查找正序
- 二分查找逆序

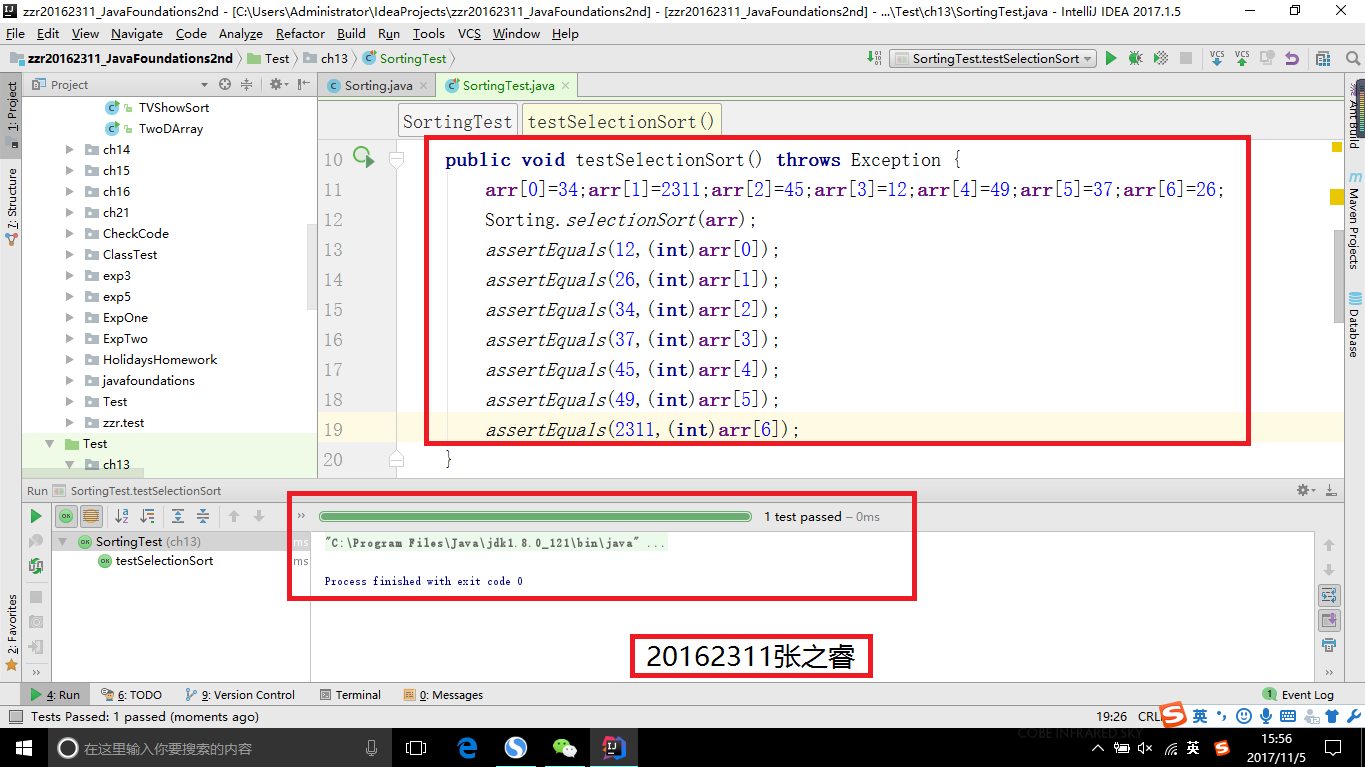
- 选择排序
- 插入排序
- 冒泡排序
- 快速排序
- 归并排序
(三) 代码链接
二、查找与排序-2
(一) 实验目的

(二) 实验过程
首先把
Searching.java和Sorting.java放入cn.edu.besti.cs1623.zzr123包中,然后新建一个Test文件夹,把书上的两个测试代码放入其中,然后分别在IDEA和命令行下运行
测试截图
- 重构代码
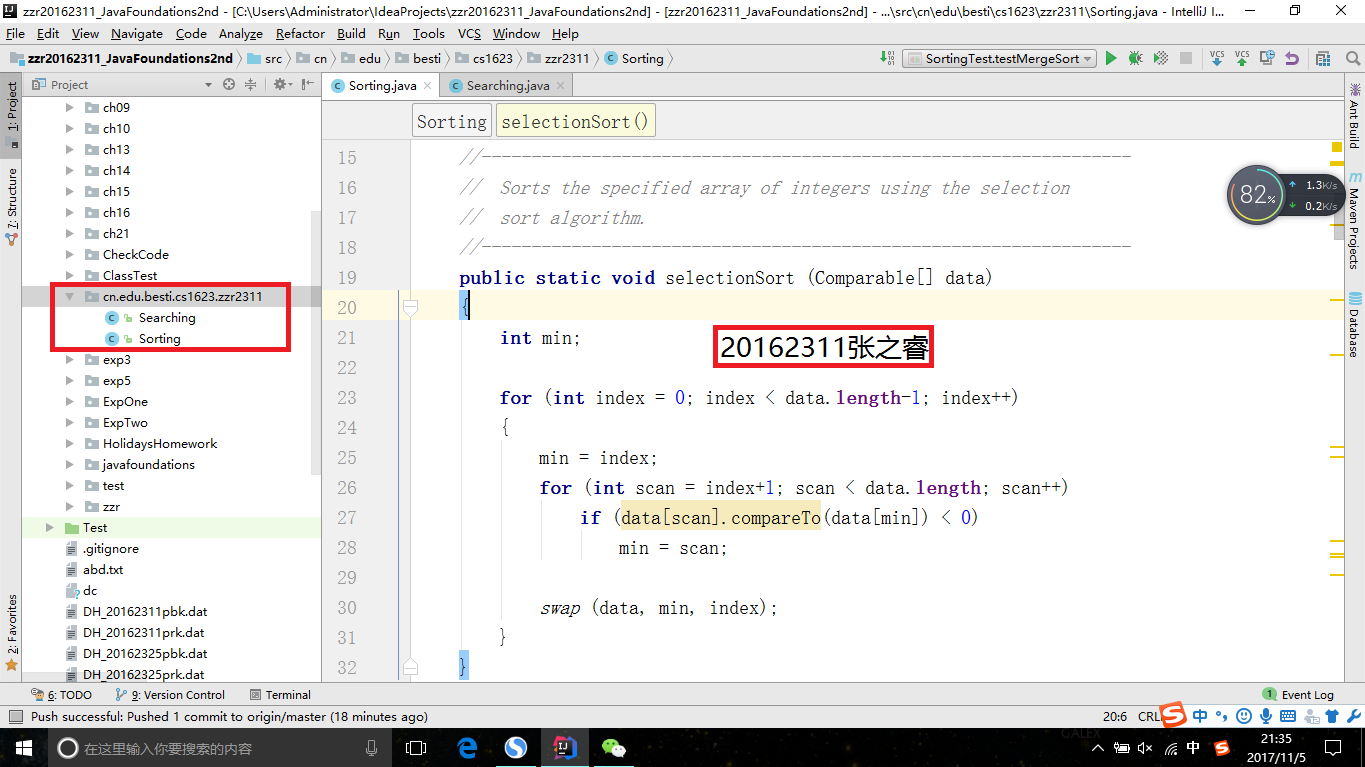
- IDEA运行测试代码
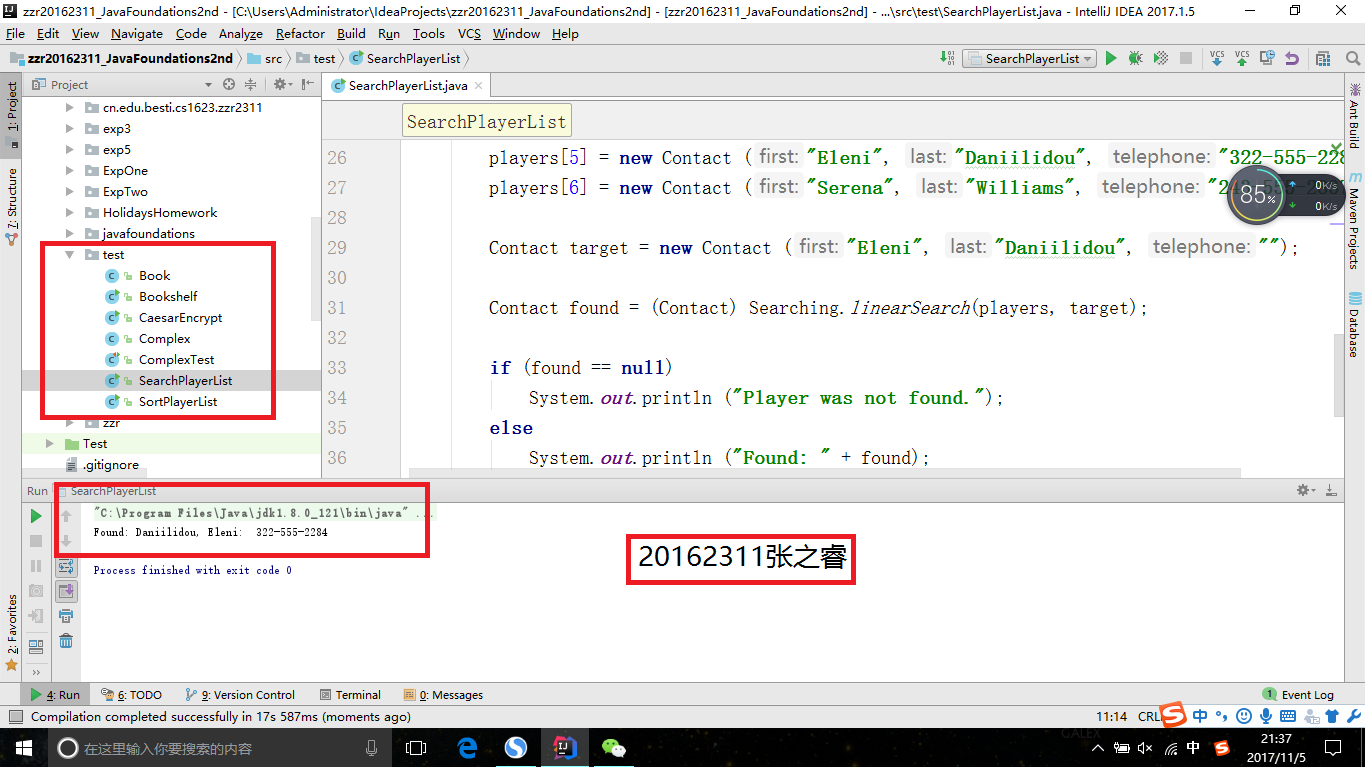
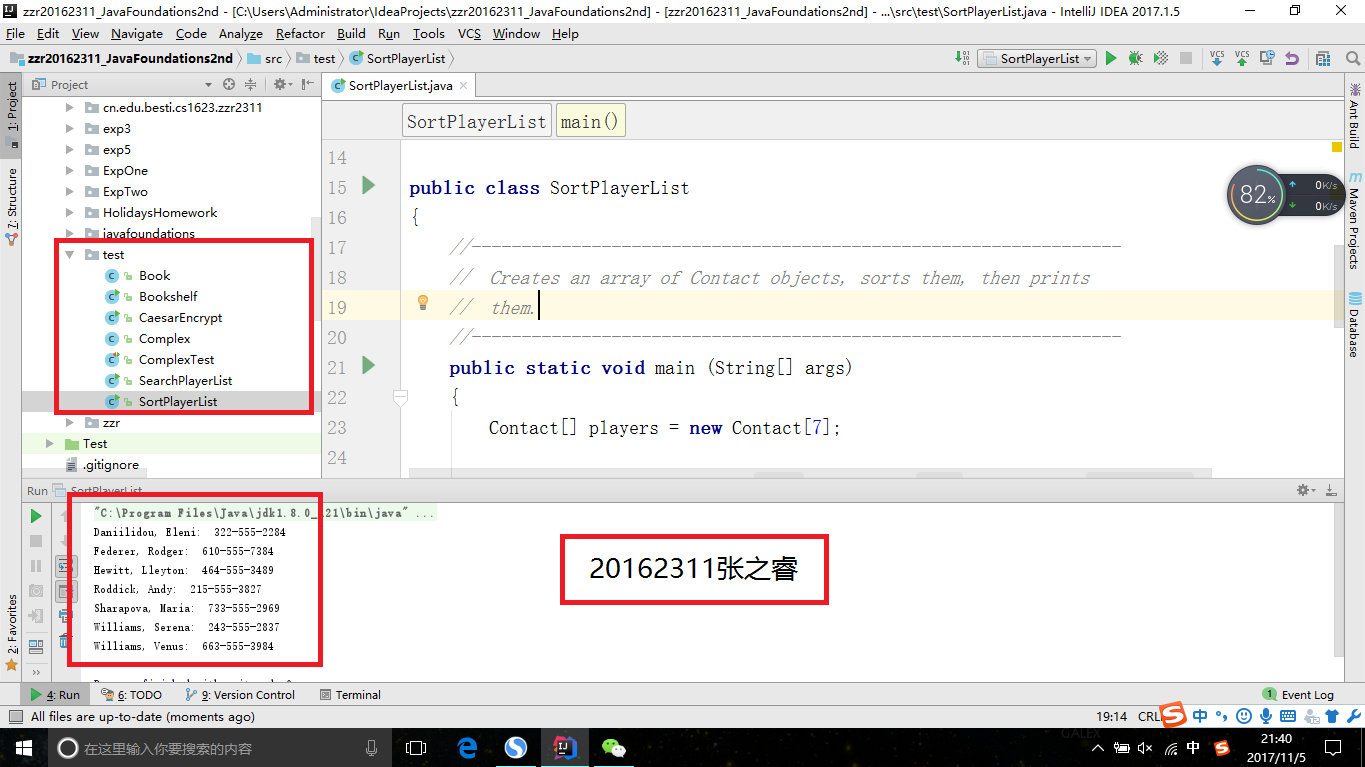
- 命令行运行测试代码
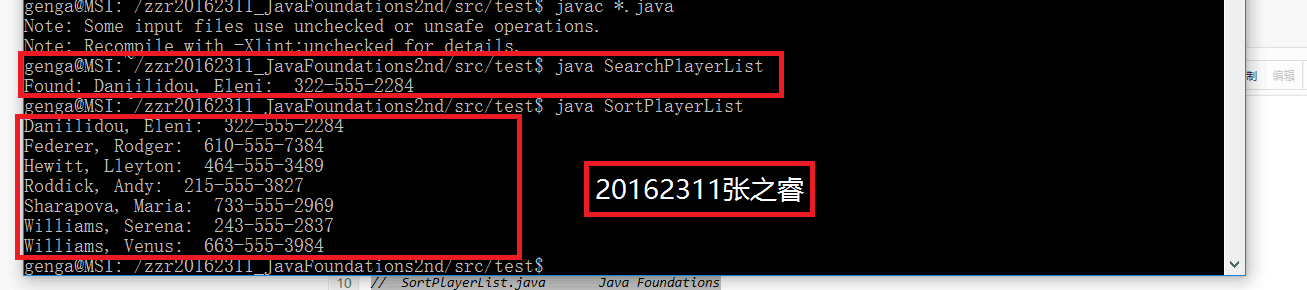
(三) 代码链接
三、查找与排序-3
(一) 实验目的
参考《[Data Structure & Algorithm] 七大查找算法》

(二) 实验过程
参考的博客中给出了七大查找方法,其中顺序查找和二分查找之前已经实现并测试了,我需要实现剩下的五种查找方法并测试
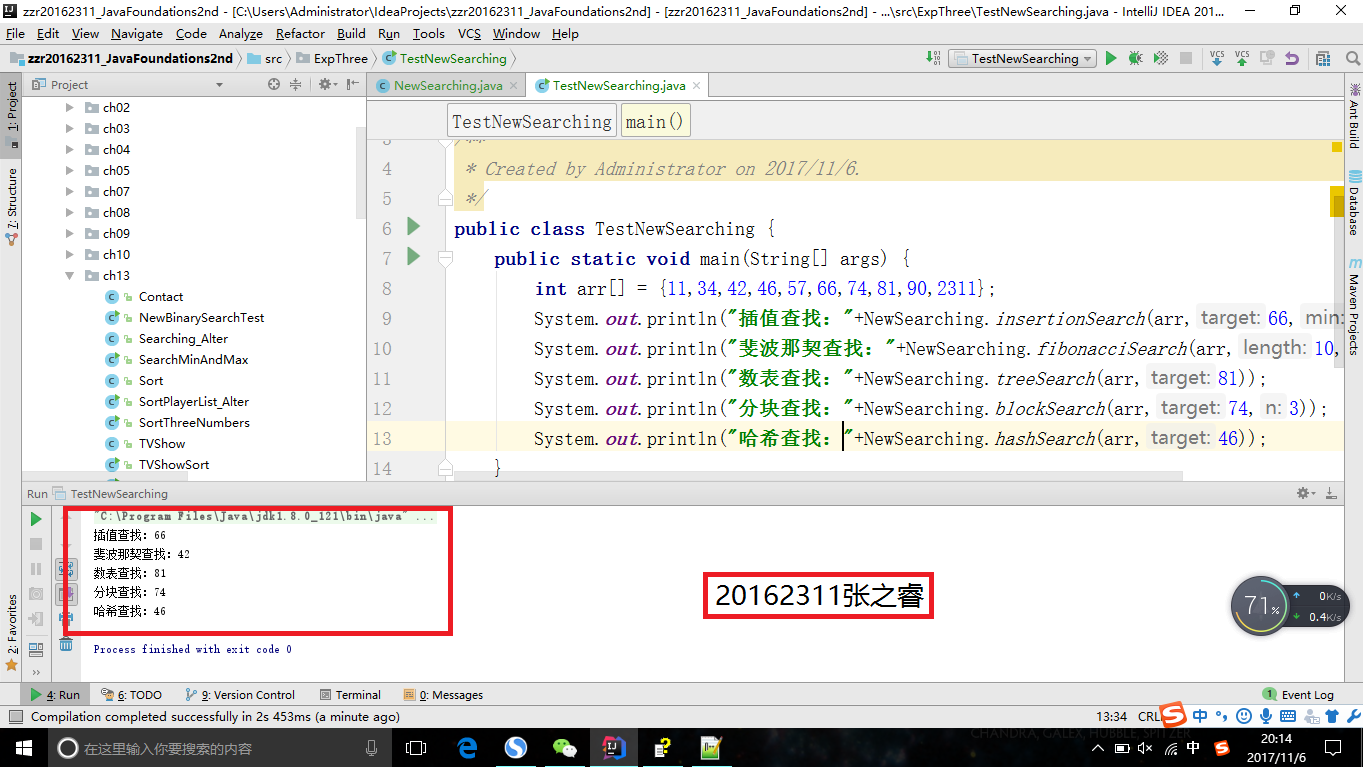
- 插值查找
插值查找类似于二分查找,只不过二分查找每次是取中点作为查找点,从而排除一半的数据,插值查找是将查找点的选择改进为自适应选择,即更加靠近查找对象。
public static int insertionSearch(int[] data, int target,
int min, int max)
{
int mid = min+(target-data[min])/(data[max]-data[min])*(max-min);
if(data[mid] == target)
return data[mid];
else
if(data[mid]>target)
return insertionSearch(data, target, min, mid-1);
else
return insertionSearch(data, target, mid+1, max);
}
- 斐波那契查找
也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。首先需要构造一个斐波那契数组
//构造一个斐波那契数组
private static void fibonacci(int F[])
{
F[0]=0;
F[1]=1;
for(int i=2;i<MAX_SIZE;i++)
F[i]=F[i-1]+F[i-2];
}
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。他要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1;
开始将k值与第F(k-1)位置的记录进行比较(及mid=low+F(k-1)-1),比较结果也分为三种
1)相等,mid位置的元素即为所求
2)>,low=mid+1,k-=2;
说明:low=mid+1说明待查找的元素在[mid+1,high]范围内,k-=2 说明范围[mid+1,high]内的元素个数为n-(F(k-1))= Fk-1-F(k-1)=Fk-F(k-1)-1=F(k-2)-1个,所以可以递归的应用斐波那契查找。
3)<,high=mid-1,k-=1。
说明:low=mid+1说明待查找的元素在[low,mid-1]范围内,k-=1 说明范围[low,mid-1]内的元素个数为F(k-1)-1个,所以可以递归 的应用斐波那契查找。
/*定义斐波那契查找法*/
//data为要查找的数组,length为数组长度,target为要找的目标
public static int fibonacciSearch(int data[],int length,int target)
{
int min = 0;
int max = length-1;
int F[] = new int[MAX_SIZE];
fibonacci(F);
int k=0;
while(length>F[k]-1)//计算length位于斐波那契数列的位置
k++;
int []temp;//将数组data扩展到F[k]-1的长度
temp= Arrays.copyOf(data,F[k]-1);
for(int i=length;i<F[k]-1;i++)
temp[i]=data[length-1];
while(min<=max)
{
int mid=min+F[k-1]-1;
if(target<temp[mid])
{
max=mid-1;
k-=1;
}
else if(target>temp[mid])
{
min=mid+1;
k-=2;
}
else
{
if(mid<length)
return data[mid]; //若相等则说明mid即为查找到的位置
else
return data[length-1]; //若mid>=n则说明是扩展的数值,返回n-1
}
}
return -1;//未查找到
}
- 数表查找
我这里的数表查找是用的之前实现的二叉查找树实现的,先构造一颗二叉查找树,然后将要查找的数组中的元素依次添加到二叉查找树中,再调用其中的find方法即可
//数表查找,利用二叉查找树实现
public static Comparable treeSearch(int []data,int target)
{
LinkedBinarySearchTree<Integer> bsTree = new LinkedBinarySearchTree<>();
for(int i=0;i<data.length;i++){
bsTree.add(data[i]);
}
return bsTree.find(target);
}
- 分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
详情参考《数据结构Java版的查找算法实现》
(1)算法思想:
将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
(2)算法流程:
- step1 先选取各块中的最大关键字构成一个索引表;
- step2 查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。
/**
* 分块查找
* 采用数组保存区块的极值和起始下标
* @param data 查找数组
* @param n 分块个数
*/
public static int blockSearch(int []data,int target,int n) {
HashMap<Integer, Integer> block = new HashMap<>();
int tem = data[0];
for (int i = 0; i < data.length - 1; i++) {
if (i % n == 0) { //起始分块
if ((i + n) >= data.length - 1) { //判断是否是最后一个区块 最后一个区块元素可能小于或大于前面区块元素
for (int j = i; j < data.length; j++) { //区块内查找极值
if (data[j] > tem) {
tem = data[j];
}
}
//保存区块极值和起始下标
block.put(tem, i);
} else {
for (int j = i; j < i + n; j++) { //区块内查找极值
if (data[j] > tem) {
tem = data[j];
}
}
//保存区块极值和起始下标
block.put(tem, i);
//初始化区块比较值
tem = data[i + n - 1];
}
}
}
//获取索引极值进行排序
Iterator<Integer> ite = block.keySet().iterator();
int[] index1 = new int[block.size()];
int i = 0;
while (ite.hasNext()){
index1[i++] = ite.next();
}
//索引极值从小到大排序
Arrays.sort(index1);
//查找元素所在区块
for (int j = 0; j < index1.length; j++) {
if (target <= index1[j]){ //小于索引值说明在此区块内进行查找
int start = block.get(index1[j]);
int end = 0;
if (j != index1.length -1){
end = block.get(index1[j+1]);
}else {
end = data.length;
}
//查找区块元素位置
for (int k = start; k < end; k++) {
if (target == data[k]){
return data[k];
}
}
}
}
return -1;//找不到返回-1
}
- 哈希查找
构造一个HashMap,把查找数组中的元素作为value,它的hash值作为key,每次查找通过计算目标的hash值直接找到目标
//哈希查找
public static int hashSearch(int data[],int target)
{
HashMap<Integer,Integer> hashMap = new HashMap<>();
for(int i=0;i<data.length;i++)
hashMap.put(Integer.hashCode(data[i]),data[i]);
int key = Integer.hashCode(target);
if(hashMap.containsKey(key))
return hashMap.get(key);
return -1;//找不到返回-1
}
6.测试截图
(三) 代码链接
四、查找与排序-4
(一) 实验目的

(二) 实验过程
依次实现四种排序方法
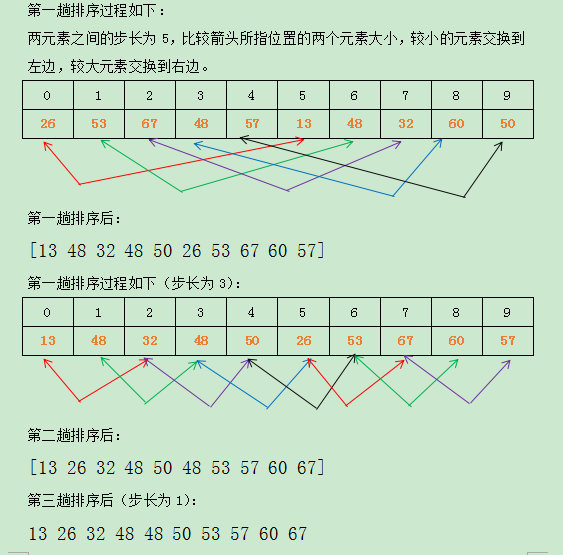
- 希尔排序
希尔排序是插入排序的一种,其基本原理是,现将待排序的数组元素分成多个子序列,使得每个子序列的元素个数相对较少,然后对各个子序列分别进行直接插入排序,待整个待排序列“基本有序”后,最后在对所有元素进行一次直接插入排序。详情可参考《【排序算法】希尔排序原理及Java实现》
//希尔排序
public static void shellSort(Comparable []data)
{
Comparable temp;
int dataLength = data.length / 2;
int pointer;
while (dataLength != 0) {
for (int i = dataLength; i < data.length; i++) {
temp = data[i];
pointer = i - dataLength;
while (pointer >= 0 && temp.compareTo(data[pointer])<0) {
data[pointer + dataLength] = data[pointer];
pointer -= dataLength;
if (pointer > data.length) {
break;
}
data[pointer + dataLength] = temp;
}
}
dataLength /= 2;
}
}
- 堆排序
堆排序的实现可利用教材上的最大堆,先构造一个最大堆,然后将要排序的数组依次放入堆中,再依次取出,只不过得到的是降序排列,只需将第一个取出的元素放在数组最后位置接下来依次类推,即可得到升序排列
//堆排序
public static void heapSort(int []data)
{
LinkedMaxHeap<Integer> heap = new LinkedMaxHeap<>();
int length = data.length;
for(int i=0;i<length;i++)
heap.add(data[i]);
for(int j=0;j<length;j++)
data[length-1-j] = heap.removeMax();
}
- 桶排序
桶排序是一种以空间换时间的排序方法,桶排序的基本思想是:把数组 arr 划分为n个大小相同子区间(桶),每个子区间各自排序,最后合并。
计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。详情参考《计数排序和桶排序(Java实现)》
(1)找出待排序数组中的最大值max、最小值min
(2)我们使用 动态数组ArrayList 作为桶,桶里放的元素也用 ArrayList 存储。桶的数量为(max-min)/arr.length+1
(3)遍历数组 arr,计算每个元素 arr[i] 放的桶
(4)每个桶各自排序
(5)遍历桶数组,把排序好的元素放进输出数组
//桶排序
public static void bucketSort(int []arr) {
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
//桶数
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for (int i = 0; i < bucketNum; i++) {
bucketArr.add(new ArrayList<Integer>());
}
//将每个元素放入桶
for (int i = 0; i < arr.length; i++) {
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
//对每个桶进行排序
for (int i = 0; i < bucketArr.size(); i++) {
Collections.sort(bucketArr.get(i));
}
int index = 0;
for (int i = 0; i < bucketNum; i++)
{
for (int j = 0; j < bucketArr.get(i).size(); j++)
{
arr[index] = bucketArr.get(i).get(j);
index++;
}
}
}
- 二叉树排序
利用二叉查找树进行排序,二叉查找树的中序遍历就是树中元素的升序排列,所以我先构造一颗二叉查找树,然后把元素添加进去,得到中序遍历,在依次放入数组中即可
//二叉树排序
public static void binaryTreeSort(int []data)
{
LinkedBinarySearchTree<Integer> bsTree = new LinkedBinarySearchTree<>();
int length = data.length;
for(int i=0;i<length;i++)
bsTree.add(data[i]);
ArrayList<Integer> list = (ArrayList<Integer>) bsTree.inorder();
for(int j=0;j<length;j++)
data[j] = list.remove(0);
}
5.测试截图

(三) 代码链接
五、查找与排序-5
(一) 实验目的

(二) 实验过程
课上没完成,课后补博客,详见博客《20162311 编写Android程序测试查找排序算法》
六、遇到的问题和解决办法
- 问题1:做第二个实验时,用命令行编译始终无法通过,明明已经导入相关的包,但总是找不到一些类
- 解决办法:问王老师,老师看了代码也说没问题,找不出什么毛病,后来用了同学的电脑上的Linux bash,clone了我的项目再到命令行下编译运行才成功
七、总结
本次的实验主要目的是加强对排序和查找算法的理解,之前已经学过一些算法,也做过相关测试,但都是书上实现好的,这次是要自己补充实现一些书上没有的查找和排序的算法。通过自己去实现,我们能更好的理解和掌握这些算法,而不是仅仅停留在使用的层面上