github项目地址
具体分工
队伍里只有我一个人。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 180 | 180 |
| Development | 开发 | 180 | 180 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 180 | 180 |
| · Coding | · 具体编码 | 180 | 180 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 |480 |600
解题思路描述与设计实现说
-
爬虫的使用
使用Jsoup的select语法进行元素查找。通过select("[id=papertitle]")和select("[id=abstract]")得到论文题目和论文摘要。
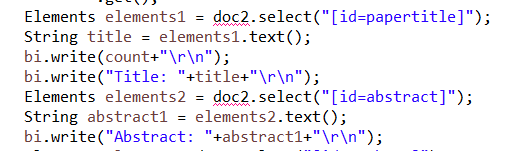
得到作者和pdf的链接。并都输出到result.txt中。
result.txt文件地址 -
代码组织与内部实现设计(类图)
-
说明算法的关键与关键实现部分流程图
- 算法的关键
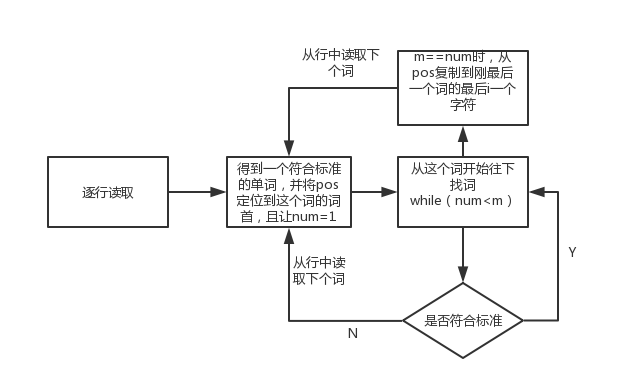
先判断命令行的参数。读取到一个符合标准的词①后,设词首的位置为begin。从这个词往后找m-1个词来构成词组。如果往后找的词符合标准则继续往后找,直到找到m-1个连续的符合标准的词。并把最后一个词的最后一个字母的位置设为end。从begin复制到end。并把得到的词组存入新的map中。如果往后找到的词是不符合标准的,则跳出查找,并回到行中从词①后继续查找。
- 算法的关键
- 附加题设计与展示

新增了作者与pdf的地址
result.txt文件地址
- 关键代码解释
int fir = y;
while ((temp[y] >= 'a'&&temp[y] <= 'z') || (temp[y] >= '0'&&temp[y] <= '9')) {
word.append(temp, y, 1);
y++;
if (y > temp.size())break;
}
if (Judge(word)) {
pos = fir;
string tempword;
int flag = 0;
int flag1 = 0;
int flag2 = 0;
int cc = 0;
m = 1;
maa[word]++;
if (w == 0) ma[word] ++;
else if (w == 1)
{
if (x == 7) {
for (int u = 0; u < 10; u++) {
ma[word] ++;
}
}
else if (x == 10)
{
ma[word] ++;
}
}
while (m != mm)
{
if (m != mm && y >= temp.size()) break;
for (int k = y; k < temp.size(); ) {
if (temp[k] < 48 || ((57 < temp[k]) && (temp[k] < 97)) || temp[k]>122)
{
k++; if (k >= temp.size()) { flag1 = 1; break; }
continue;
}
else {//发现一个单词
while ((temp[k] >= 'a'&&temp[k] <= 'z') || (temp[k] >= '0'&&temp[k] <= '9')) {
tempword.append(temp, k, 1);
k++;
if (k > temp.size())break;
}
if (Judge(tempword)) {
m++;
if (m != mm && k >= temp.size()) {
flag = 1;
break;
}
if (m == mm) {
words.append(temp, pos, k - pos);
//pos = y + 1;
if (w == 0) mas[words]++;
if (w == 1) {
if (x == 7)
for (int u = 0; u < 10; u++)
mas[words]++;
if (x == 10)
mas[words]++;
}
break;
}
}
else
{
pos = k + 1;
tempword.clear();
flag2 = 1;
break;
}
tempword.clear();
}
}
if (flag == 1) break;
if (flag1 == 1) break;
if (flag2 == 1) break;
}
words.clear();
}
先判断命令行的参数。读取到一个符合标准的词①后,设词首的位置为begin。从这个词往后找m-1个词来构成词组。如果往后找的词符合标准则继续往后找,直到找到m-1个连续的符合标准的词。并把最后一个词的最后一个字母的位置设为end。从begin复制到end。并把得到的词组存入新的map中。如果往后找到的词是不符合标准的,则跳出查找,并回到行中从词①后继续查找。
输入
WordCount.exe -i input.txt -m 3 -n 3 -w 1 -o output.txt
运行结果
characters:1184323
words:120299
lines:1958
<convolutional neural networks>: 196
<generative adversarial networks>: 178
<convolutional neural network>: 159
性能分析
输入的命令行为:
WordCount.exe -i input.txt -m 3 -n 3 -w 1 -o output.txt
/*
*统计input.txt文件中的字符数、单词数、有效行数、出现次数排在前3的3个单词长的词组,并采用权重累计频数,最终统计结果输出到output.txt
*/
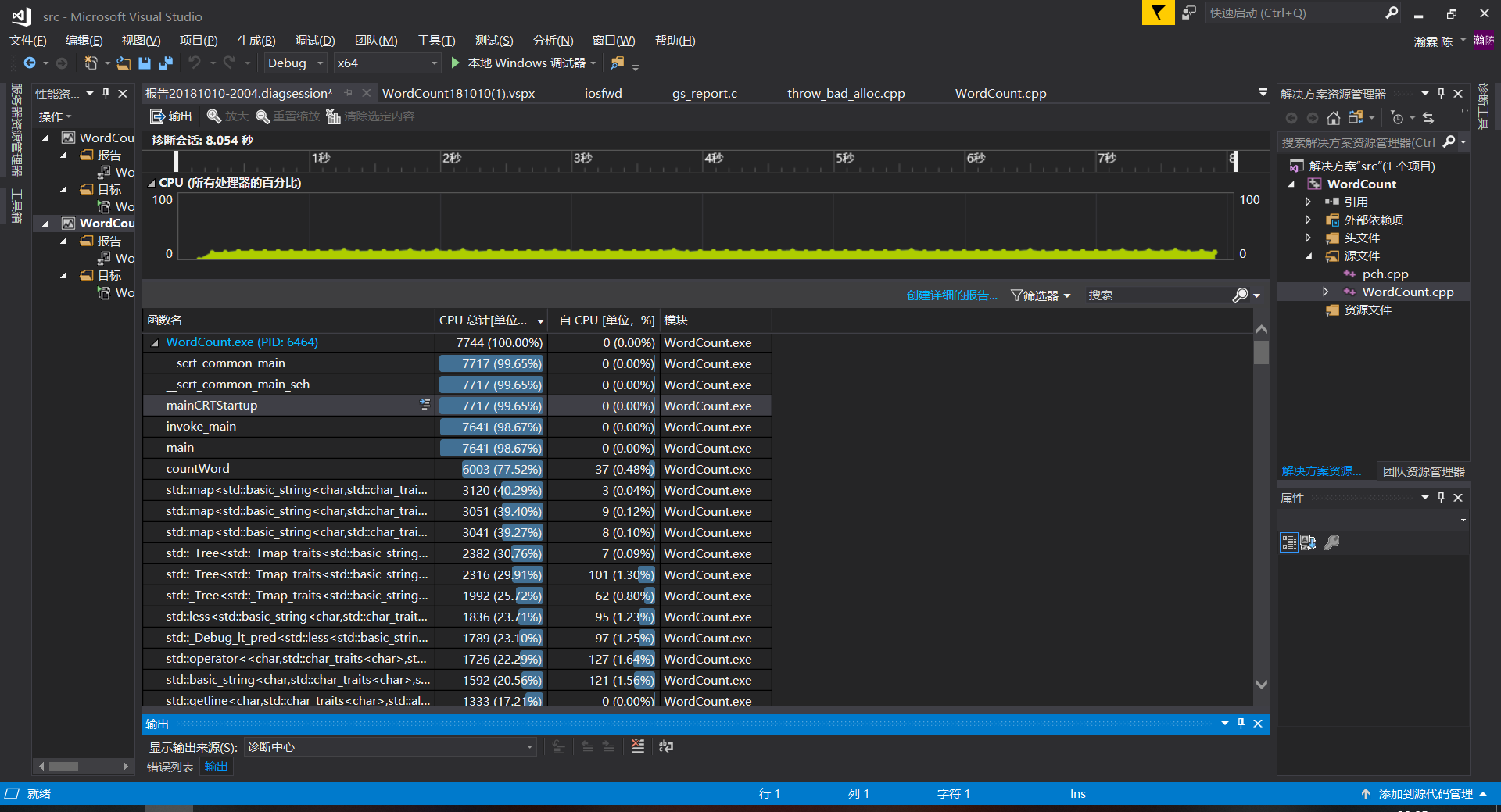

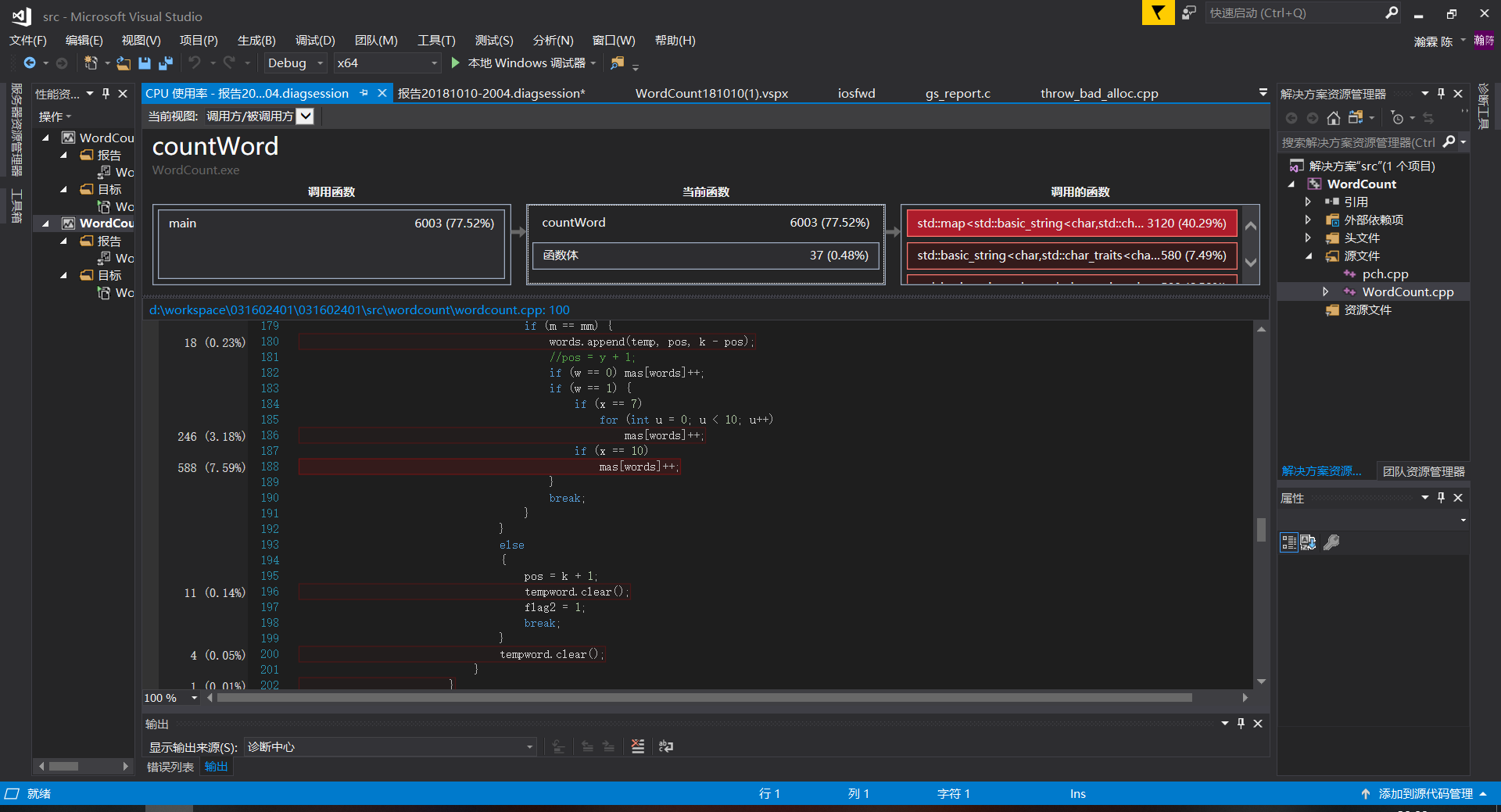
共花费8.054秒,countword函数中其中四个将词存入map中的花费最多时间。
-
Github的代码签入记录
-
遇到的代码模块异常或结对困难及解决方法
问题:命令行输入时发生错误。解决:先输入字符串试一下。结果:解决了。
问题:获取词组时程序会发生死循环。解决:设置断点,找到死循环的地方。 -
评价你的队友
队伍里只有我一个人。
需要提高的地方:代码的规范性。 -
学习进度条
第N周 |新增代码(行)| 累计代码(行)| 本周学习耗时(小时) |累计学习耗时(小时)| 重要成长
---|---|---|---|---|---
1|100|100|3|3|学习了map和vector的操作
4|50|150|3|6|学习了简单的爬虫
5|100|250|3|9|