0.PTA得分截图

1.本周学习总结(0-5分)
1.1 总结图内容
图存储结构
邻接矩阵:适合稠密图
邻接矩阵的解析:
不带权的图:如果i,j之间有边,则G.edge[i][j]=1,如果没有边,则G.edge[i][j]=0
带权图:如果i,j之间有边,则G.edge[i][j]=权值。 如果没有边,且i=j,则G.edge[i][j]=0;若i!=j的话,G.edge[i][j]=正无穷
且根据邻接矩阵建图,时间复杂度为:O(n2),与顶点个数有关
对于需要用邻接矩阵的建图,且顶点个数较多,可能超过了栈空间。可以用指针做法,动态申请空间。也可以使用全局变量或静态变量,但是强烈不建议,在多文件编程中非常不方便
邻接矩阵结构体及建图代码:

带权节点图的代码由以下代码稍作修改便可以
结构体:
typedef struct //图的定义
{ int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,弧数
} MGraph;
建图代码:
void CreateMGraph(MGraph& g, int n, int e)//建图
{
g.n = n; g.e = e;
int x, y;//x,y对应两条边
for (int i = 0; i < n; i++)//初始化图结构
for (int j = 0; j < n; j++)
g.edges[i][j] = 0;
for (int i = 0; i < e; i++)
{
cin >> x >> y;
g.edges[x][y] = 1;
g.edges[y][x] = 1;//有向图删掉这句
}
}
1邻接表:适合稀疏图

邻接表结构体及其代码:
typedef struct ANode
{
int adjvex;//该节点的编号
struct ANode* nextarc;//指向下一节点的指针
}ANode;
typedef struct VNode
{
int data;//顶点信息
ANode* firstarc;//指向第一个节点
}VNode;
typedef struct AdjGraph
{
VNode adjvex[MAXSIZE];
int N, M;//N表示顶点个数,M表示边数
}AdjGraph,*Graph;
建图代码:
void CreatGraph(Graph& G, int N, int M)//建立图结构
{
int x, y;//保存两条邻边
ANode* p;
G->N = N; G->M = M;
for (int i = 1; i <= N; i++) //初始化链表的next
{
G->adjvex[i].firstarc = NULL;
}
for (int i = 1; i <= M; i++)
{
cin >> x >> y;
p = new ANode;
p->adjvex = x;
p->nextarc = G->adjvex[y].firstarc;
G->adjvex[y].firstarc = p;
//无向图,有向图只用写入一个就ok
p = new ANode;
p->adjvex = y;
p->nextarc = G->adjvex[x].firstarc;
G->adjvex[x].firstarc = p;
}
}
图遍历及应用。包括DFS,BFS.如何判断图是否连通、如何查找图路径、如何找最短路径。
深度优先遍历(DFS)
深度优先搜索遍历的过程
(1)从图中某个初始顶点v出发,首先访问初始顶点v。
(2)选择一个与顶点v相邻且没被访问过的顶点w为初始顶点,再从w出发进行深度优先搜索,直到图中与当前顶点v邻接的所有顶点都被访问过为止。
具体图解:

具体代码:
void DFSTraverse(Graph G) { //对于非连通图的情况,需要加上这个函数来遍历图
for (v=0; v<G.vexnum; ++v)
visited[v] = 0; // 访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS(G,v); // 对尚未访问的顶点调用DFS
}
void DFS(ALGraph *G,int v) //深度遍历DFS
{ ArcNode *p;
visited[v]=1; //将该节点置为已访问
printf("%d ",v);
p=G->adjlist[v].firstarc;
while (p!=NULL)
{
if (visited[p->adjvex]==0) DFS(G,p->adjvex); //如果该节点未访问,则遍历该节点
p=p->nextarc; //如果该节点已访问,则遍历下一个节点
}
}
广度优先遍历(BFS)
广度优先搜索遍历的过程是:
(1)访问初始点v,接着访问v的所有未被访问过的邻接点。
(2)按照次序访问每一个顶点的所有未被访问过的邻接点。
(3)依次类推,直到图中所有顶点都被访问过为止。
广度遍历图解:

具体代码:
void DFSTraverse(Graph G) { //对于非连通图的情况,需要加上这个函数来遍历图
for (v=0; v<G.vexnum; ++v)
visited[v] = 0; // 访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) BFS(G,v); // 对尚未访问的顶点调用DFS
}
void BFS(Graph G, int i)//从第i个节点开始广度遍历
{
ANode* p;
p = new ANode;
queue<int> queue;
queue.push(i);
visited[i] = 1; //置为已访问
while (!queue.empty())
{
i = queue.front();
queue.pop();
p = G->adjvex[i].firstarc;
cout<<i;//输出节点
while (p != NULL)
{
if (visited[p->adjvex] == 0)//如果该节点未访问
{
queue.push(p->adjvex);
visited[p->adjvex] = 1; //置为已访问
}
p = p->nextarc;
}
}
}
判断图是否连通
判断图是否连通思路:
由于DFS,BFS都是由一个顶点出发,遍历整个连通图的。
所以只要由一个顶点遍历之后,检查visited[]是否全部为1,如果全为1,说明为连通图,否则是非连通图
求不带权无向连通图的最短路径
伪代码:
队列结构体
typedef struct
{ int data; //顶点编号
int parent; //前一个顶点的位置
} QUERE;
void ShortPath(AdjGraph *G,int u,int v)
{
qu[rear].data=u;//第一个顶点u进队
while队不空循环
{ front++;
w=qu[front].data; //出队顶点w
if (w==v) 根据parent关系输出路径break;
while遍历邻接表
{
rear++;//将w的未访问过的邻接点进队
qu[rear].data=p->adjvex;
qu[rear].parent=front;
}
}
}
//还可以用pta上的解法来做:
代码如下:
struct GNode{
int Nv;
int Ne;
AdjList List;
}Graph,*PtrToGNode;
//运用path[]保存前一个顶点,dish[]数组保存最短路径,类似于迪杰斯特拉算法
void Unweighted( Graph G, Queue Q, int dist[], int path[], Vertex S )
{
Vertex V, W;
NodePtr ptr;
dist[S] = 0;
Enqueue(S, Q);
while ( !IsEmpty(Q) )
{
V = Dequeue( Q );//出队列一个顶点
for ( ptr=G->List[V].FirstEdge; ptr; ptr=ptr->Next) //遍历邻接表
{
W = ptr->AdjV;
if ( dist[W] == INFINITY ) {
dist[w]=dist[v]+1;;
path[W] = V;
Enqueue(W,Q);;
}
}
}
}
最小生成树相关算法及应用
生成树的概念
一个连通图的生成树是一个极小连通子图,它含有图中全部n个顶点和构成一棵树的(n-1)条边。不能回路。一个图的生成树不唯一
深度优先生成树:由深度优先遍历得到的生成树称为深度优先生成树;
广度优先生成树:由广度优先遍历得到的生成树称为广度优先生成树;
最小生成树:生成树中其中权值之和最小的生成树称为图的最小生成树,且最小生成树不唯一,但其权值一定相同
普里姆算法(prim)
图解:

算法思想:
初始化开始顶点,到其他顶点为侯选边,选出最小边,加入集合,再次修改侯选边,选出最小边,如此循环,直到所有顶点选中
代码层面用closest[i]数组表示顶点i的前一个顶点,lowcost[i]表示顶点i到集合的最小边,lowcost[i]==0表示已经访问过
代码详细解析:
void Prim(MGraph G)//prim算法
{
int closest[1000];//记录顶点i的前一个顶点
int lowcost[1000];//记录顶点i到集合的最小边
int k;
for (int i = 1; i <= G.N; i++)//初始化数组closest[i],lowcost[i]
{
closest[i] = 1; lowcost[i] = G.deges[1][i];
}
for (int i = 1; i < G.N; i++)//访问N-1个节点
{
int min = INT_MAX;//初始化最小值
for (int j = 1; j <= G.N; j++)//找出lowcost[i]数组中的最小值,加入集合
{
if (lowcost[j] < min && lowcost[j] != 0)
{
min = lowcost[j]; k = j;
}
}
lowcost[k] = 0;//将该节点置为已访问
for (int j = 1; j <= G.N; j++)//修改lowcost数组,closest数组的值
{
if (lowcost[j] != 0 && G.deges[k][j] < lowcost[j])//如果新加入的顶点到j顶点的权重 小于 原来顶点到j顶点的权重,则修改其最小值
{
lowcost[j] = G.deges[k][j];//修改lowcost[j]的最小值
closest[j] = k;//修改j顶点的前一个顶点为k
}
}
}
}
prim算法应用
适用于稠密图,且算法复杂度只关于顶点,图存储结构用邻接矩阵,算法复杂度为O(n2)
克鲁斯卡尔算法(kruskal)
图解:
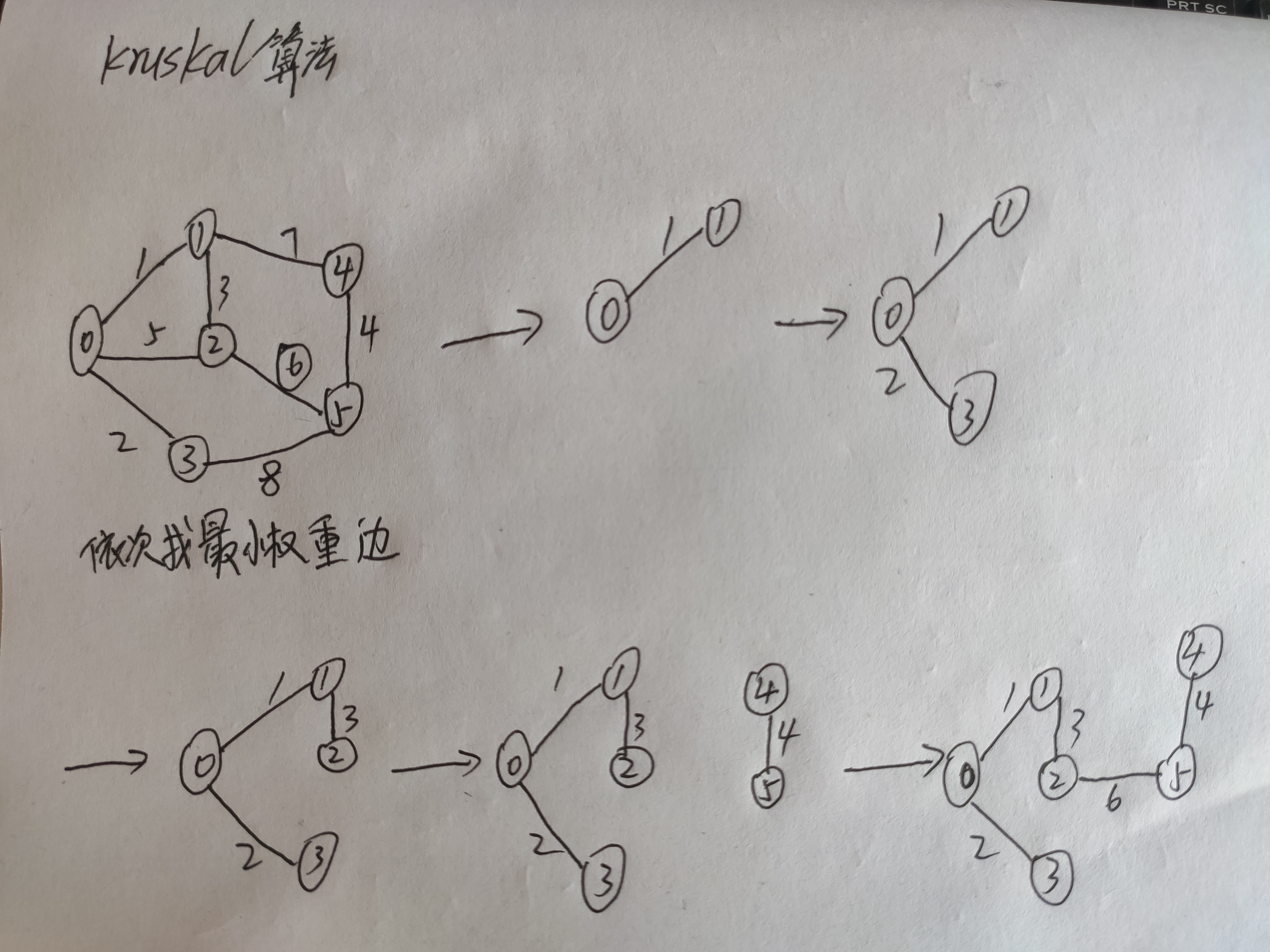
算法思想:
将所有边起始顶点和终止顶点以及权重保存下来,用快排或堆排根据权重排序,选出最小边加入集合,假若邻边都在同一个集合内,则直接选下一条边,直到边完
代码层面则用vets[i]数组表示该顶点的集合,若相同,则属于同一个集合
代码详细解析:
void Kruskal(Graph G)//普鲁斯卡尔算法
{
ANode* p;
Edge E[MAXSIZE];
int vets[MAXSIZE];//集合辅助数组
int k = 1;
for (int i = 1; i <= G->N; i++)//将所有边放入数组中
{
p = new ANode;
p = G->adjvex[i].firstarc;//遍历每个顶点
while (p != NULL)//将每条边的起点终点权值写入数组中
{
E[k].start = i;
E[k].tail = p->adjvex;
E[k].w = p->weight;
p = p->nextarc;
k++;
}
}
sort(E+1, E + G->M, cmp);//排序
for (int i = 1; i <= G->N; i++)//初始化辅助数组,使它本身成一个集合
{
vets[i] = i;
}
int start, tail;//保存起始终止节点
for (int j = 1, k = 1; k < G->N; j++)//k表示构造第k条边,j表示数组E从j开始
{
start = E[j].start; tail = E[j].tail;
int sn1, sn2;//保存两个顶点所属的集合编号
sn1 = vets[start]; sn2 = vets[tail];//必须用sn1,sn2保存,直接用vets[start],vets[tail]不行
if (sn1 != sn2)//如果两顶点属于不同集合
{
k++;//将构造边数加一
for (int i = 1; i <= G->N; i++)
{
if (vets[i] == sn2)//将节点所属集合合并
{
vets[i] = sn1;
}
}
}
}
}
算法应用:
公路村村通等等关于最小生成数的,适用于稀疏,且算法复杂度只关于边,图存储结构用邻接表,,可以用并查集改进该算法,时间复杂度为elog2e
最短路径相关算法及应用,可适当拓展最短路径算法
最短路径概念及相关介绍
最短路径概念:在带权有向图中A点(源点)到达B点(终点)的多条路径中,寻找一条各边权值之和最小的路径,即最短路径。
最短路径和最小生成树不同:最小生成树是经过所有顶点的,而最短路径不一定经过所有顶点
求最短路径一般有两种算法:求一顶点到其他各点的最短路径一般用 Dijkstra(迪杰斯特拉)算法,而求任意两点间的最短路径时,一般选用用Floyd(弗洛伊德)算法
Dijkstra(迪杰斯特拉算法)
图解:

算法思想:
从起始顶点选出一条距离起始顶点最小距离边V1, 若起始顶点直接到Vj顶点的距离大于起始顶点经过V1到Vj的距离的话,则修改其距离值。重复上述步骤,直到所有顶点全被包含
代码层面:用数组dist[]表示源点V0到每个终点的最短路径长度,path[]表示短路径序列的前一顶点的序号。-1表示没有路径。用一个数组s[]表示该顶点是否被选中,1代表选中,0代表还未选中
具体代码解析如下:
void Dijkstra(MGraph g, int v)//源点v到其他顶点最短路径
{
int dish[MAXV], path[MAXV];//定义dish[],path[]数组
int s[MAXV];//辅助,用来看该节点是否访问过
for (int i = 0; i < g.n; i++)//初始化s[],dish[],path[]数组的
{
s[i] = 0;
dish[i] = g.edges[v][i];
if (g.edges[v][i] < INF)
path[i] = v;
else
path[i] = -1;
}
s[v] = 1;//表示v顶点已经访问过
int min;
int u=0;//保存最小路径顶点
for (int i = 0; i < g.n-1; i++)
{
min = INF;
for (int j = 0; j < g.n; j++)
{
if (s[j] == 0 && dish[j] < min)//找出dish[]数组中的最小值
{
u = j;
min = dish[j];
}
}
s[u] = 1;//表示该顶点已访问
for (int j = 0; j < g.n; j++)
{
if (s[j] == 0)//表示该顶点未访问过
{
if (g.edges[u][j] < INF && dish[u] + g.edges[u][j] < dish[j])//j顶点与u有邻边,且小于原来的值
{
dish[j] = dish[u] + g.edges[u][j];//修改j的dish
path[j] = u;//前驱顶点改变
}
}
}
}
Dispath(dish,path,s,g.n,v);//输出路径
}
Dijkstra(迪杰斯特拉算法)应用:
计算机网络路由,旅游规划等等关于最小路径的应用
时间复杂度为:O(n2)
弗洛伊德(Floyd)算法
图解:

算法思想:
用二维数组A[][[]表示各点的最短路径,path[][]表示前一个顶点,分别遍历每个顶点,在遍历每个顶点的每条边,找出最短路径的路径,写入A[][],path[][];遍历完成后,即得到每两个顶点间的最短路径;
时间复杂度为O(n3)。求每两个顶点间的最短路径,用迪杰斯特拉算法也可以完成,在它的外面加上以每个顶点为起点遍历就可以完成,时间复杂度也为O(n3)
算法具体代码解析:
void Floyd(MGraph g)
{
int A[MAXV][MAXV];
int path[MAXV][MAXV];
int i,j,k,n=g.n;
for(i=0;i<n;i++) //A[][],path[]数组初始化
for(j=0;j<n;j++)
{
A[i][j]=g.edges[i][j];
path[i][j]=-1;
}
for(k=0;k<n;k++) //三重循环,遍历每个顶点
{
for(i=0;i<n;i++) //再遍历每个顶点的每条边
for(j=0;j<n;j++)
if(A[i][j]>(A[i][k]+A[k][j])) //如果存在最短路径,则修改A,Path数组的值
{
A[i][j]=A[i][k]+A[k][j];
path[i][j]=k;
}
}
//循环完成后,即得出每两个顶点间的最短路径,保存在两个二维数组里
}
弗洛伊德(Floyd)算法应用:
计算机网络路由等等,与迪杰特斯拉算法差不多,只是这样求两个顶点间的最短路径更加简洁,方便
拓扑排序、关键路径
拓扑排序
拓扑排序介绍:
拓扑排序的图必须是有向无环图,在这个图中寻找拓扑序列的过程叫做拓扑排序
拓扑排序可以用来检测图中是否有回路
图解:

拓扑排序伪代码:
void TopSort(AdjGraph *G)
{
初始化count=0
while 遍历邻接表,计算出每个顶点的入度,即count
for将入度为0(count==0)的顶点入栈或队列
while栈不为空
出栈一个顶点,输出
while遍历该顶点的领接表
修改每个顶点的入度,即减一
将入度为0的顶点入栈
}
拓扑排序应用:
可以用于排课等需要先后顺序的事件,还可以用来检验图中是否有回路
关键路径
概念介绍:
AOE-网(带权有向无环图) 概念:
用顶点表示事件,用有向边e表示活动,边的权c(e)表示活动持续时间。是一个带权的有向无环图
源点:入度为0的顶点 汇点:出度为0的点
关键路径:从源点到汇点的最长路径
关键活动:关键路径中的边
图解:

1.2.谈谈你对图的认识及学习体会。
学习完了图和树这两个章节,也算学完了非线性结构的基本概念及知识。
在学习树结构时,最大的难点便是递归的设计,以及代码比较难调试,并不能直观的看到结果
而在学习图结构时,感觉概念不难理解,但是求各类问题好多算法,且自己现在根本没有能力写出具体代码,都是哪里不会看哪里,但起码的算法理解我是明白的,问题就是具体代码的问题
图这个结构,解决的是多对多问题,仔细看起来树的一对多结构和一对一结构都是它的子集。而图结构主要解决的便是多对多关系中的最小生成树(经过全部顶点),最短路径(不用经过全部顶点),关键路径,遍历全部顶点的问题等等
2.阅读代码(0--5分)
2.1 题目及解题代码

解题代码:

2.1.1 该题的设计思路
如果节点属于第一个集合,将其着为蓝色,否则着为红色。只有在二分图的情况下,可以给图着色:一个节点为蓝色,说明它的所有邻接点为红色,它的邻接点的所有邻接点为蓝色,依此类推。
代码层面中:使用数组(或者哈希表)记录每个节点的颜色: color[node]。颜色可以是 0, 1,或者未着色(-1 或者 null)。
使用栈完成深度优先搜索,存储着下一个要访问节点的顺序。在 graph[node] 中,对每个未着色邻接点,着色该节点并将其放入到栈中。

2.1.2 该题的伪代码

2.1.3 运行结果

2.1.4分析该题目解题优势及难点。
该解法将一个我感觉摸不着头脑的题目转化成了类似于pta上图着色的问题,只不过这里是给它上色,pta是判断上色是否正确。转化成上色后就很好理解了该题的基本思路。
还有就是该题使用栈完成了深度优先搜索,存储着下一个要访问节点的顺序,不同于以前的递归调用深度遍历
2.2 题目及解题代码
解题代码:

2.2.1 该题的设计思路
使用深度优先搜索的方法判断图中的每个节点是否能走到环中。对于每个节点,我们有三种数组表示的方法:
用visited[0]表示该节点没有出度,是终点;用visited[1]表示该节点已访问;用visited[2]表示该节点安全
当我们第一次访问一个节点时,我们把它从 visited[该顶点]为0 变成 visited[该顶点]为1 ,并继续搜索与它相连的节点。
如果在搜索过程中我们遇到一个 visited[该顶点]为1 的节点,那么说明找到了一个环,此时退出搜索,所有的 visited[该顶点]为1 节点保持不变(即从任意一个 visited[该顶点]为1 的节点开始,都能走到环中)
如果搜索过程中,我们没有遇到 visited[该顶点]为1 的顶点,那么在回溯到当前节点时,我们把它从 visited[该顶点]为1 变成 visited[该顶点]为2 ,即表示它是一个安全的节点。
2.2.2 该题的伪代码

2.2.3 运行结果

2.2.4分析该题目解题优势及难点。
优势:用visited[]数组巧妙地表示了该节点的状态情况,运用了DFS来看它有没有环
主要这题就是看它每个顶点是不是连通的,不是连通的就是安全节点。难点就是递归的的设计及如何处理每个顶点的状态比较难弄
2.3 题目及解题代码

解题代码:

2.3.1 该题的设计思路
先将每个节点度为1的节点保存,然后一层层地删除,直到图的节点为1个或者两个为止(由题意可知,最小高度树的根节点一定是一个或者两个)
类似于拓扑排序,只不过像他的变式,换了一种方式来出题
2.3.2 该题的伪代码

2.3.3 运行结果
2.3.4分析该题目解题优势及难点。
这题的思路刚开始我想的是用广度遍每个节点,保存高度和根节点。最后比较高度,最小的根节点即为答案,但这种做法可能会超时
而题目的这种做法,可以说是很巧妙了像拨洋葱一样,层层剥开,剩下的心便是高度最小的根节点,效率时间也可以说是最小化了