创建表
1、建表语句如下所示:
DROP TABLE IF EXISTS `p_user`;
CREATE TABLE `p_user` (
`id` int(11) NOT NULL auto_increment,
`name` varchar(10) default NULL,
`sex` char(2) default NULL,
PRIMARY KEY (`id`)
);
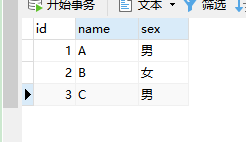
INSERT INTO `p_user` VALUES ('1', 'A', '男');
INSERT INTO `p_user` VALUES ('2', 'B', '女');
INSERT INTO `p_user` VALUES ('3', 'C', '男');
然后给name字段创建Unique索引,请自行百度。
explain函数验证索引是否有效
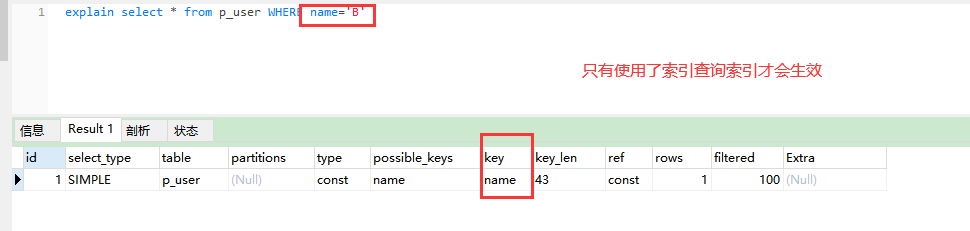
第一步:使用列表name查询验证索引。
1、使用索引列时索引才会生效,语句如下:
explain select * from p_user WHERE name='B'
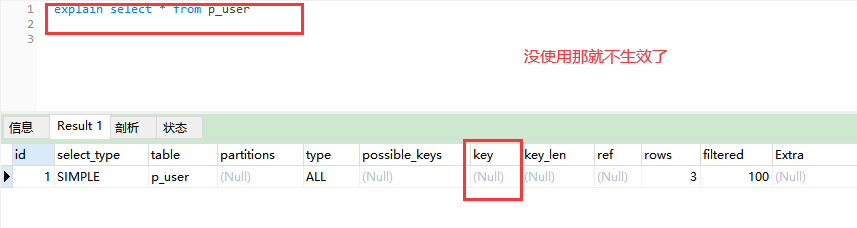
2、不使用索引查询:
explain select * from p_user
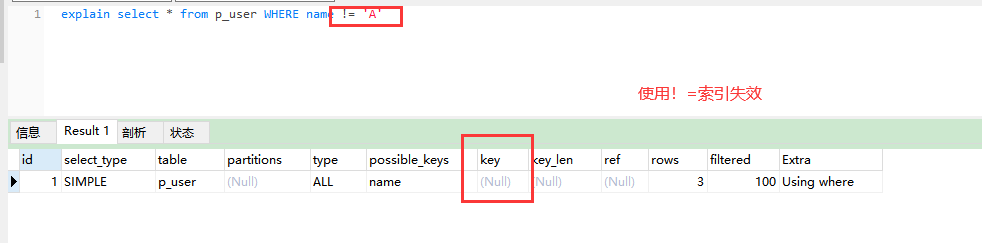
第二步:失效的索引。
1、使用语句:
explain select * from p_user WHERE name != 'A'
第三步:复合场景。
1、使用语句:
explain select * from p_user WHERE name='B' AND name != 'A'
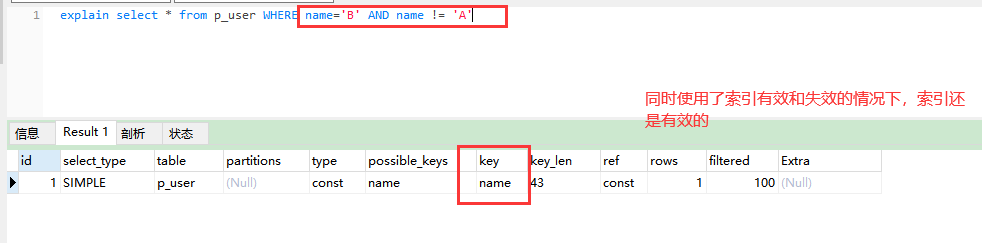
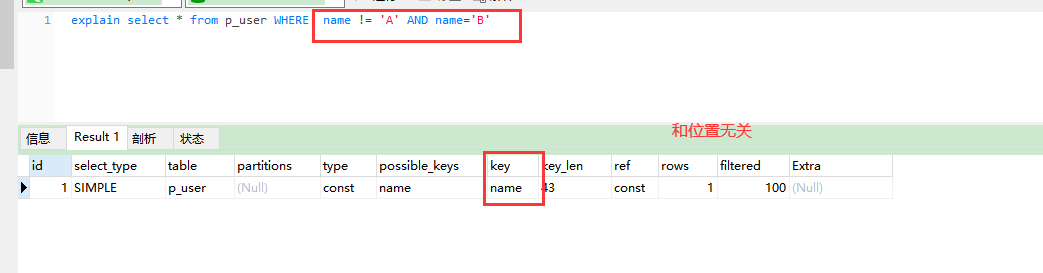
explain函数介绍
explain显示了MySQL如何使用索引来处理select语句以及连接表。他可以帮助选择更好的索引和写出更优化的查询语句
explain显示了很多列,各个关键字的含义如下:
- table:顾名思义,显示这一行的数据是关于哪张表的;
- type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为:const、eq_reg、ref、range、indexhe和ALL;
- possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从where语句中选择一个合适的语句;
- key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MySQL会选择优化不足的索引。这种情况下,可以在Select语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引;
- key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好;
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数;
- rows:MySQL认为必须检查的用来返回请求数据的行数;
- Extra:关于MySQL如何解析查询的额外信息。
- 具体的各个列所能表示的值以及含义可以参考MySQL官方文档介绍,地址:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
造成索引失效的场景
- where 子句中使用 != 或 <> 操作符,引擎将放弃使用索引而进行全表扫描。
- where 子句中使用 or 来连接条件,将导致引擎放弃使用索引而进行全表扫描,即使其中有条件带索引也不会使用,这也是为什么尽量少用 or 的原因。
- 对于多列索引,不是使用的一部分,则不会使用索引。
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不会使用索引。
- like的模糊查询以 % 开头,索引失效。
- 在 where 子句中对字段进行表达式操作,导致引擎放弃使用索引而进行全表扫描。
- 在 where 子句中对字段进行函数操作,导致引擎放弃使用索引而进行全表扫描。
- 在 where 子句中的 “=” 左边进行函数、算术运算或其他表达式运算,导致系统将可能无法正确使用索引。
- 不适合键值较少的列(重复数据较多的列)。假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。再加上访问索引块,一共要访问大于200个的数据块。如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。