SELECT语句执行的过程是:
1>. FROM
2>. WHERE
3>. GROUP BY
4>. HAVING
5>. SELECT
6>. ORDER BY
WHERE子句在SELECT子句之前执行,所以在SELECT中的列别名,WHERE中当然是不会认识的。
Order by和Top语句一起的时候,执行的顺序就不同了。先order by 进行排序,然后在取Top前X条记录。
eg:SELECT TOP 10000 * FROM OrderDetail
ORDER BY OrderDetailID DESC
上面语句是取OrderDetail表中的最后1W条记录。
-----------------------------------------------------------------------------------------------------------------------
一.FOR XML PATH 简单介绍FOR XML PATH 有的人可能知道有的人可能不知道,其实它就是将查询结果集以XML形式展现,有了它我们可以简化我们的查询语句实现一些以前可能需要借助函数活存储过程来完成的工作。那么以一个实例为主。
使用FOR XML PATH('')),1,1,'')语句。
例如表
fieldname
-----------
AAA
BBB
CCC
串联之后就是字符串: AAA,BBB,CCC
首先呢!我们在增加一张学生表,列分别为(stuID,sName,hobby),stuID代表学生编号,sName代表学生姓名,hobby列存学生的爱好!那么现在表结构如下:
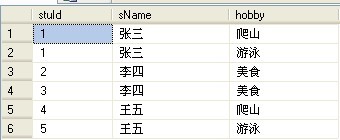
这时,我们的要求是查询学生表,显示所有学生的爱好的结果集,代码如下:
SELECT sName,
(SELECT hobby+',' FROM student
WHERE sName=A.sName
FOR XML PATH('')) AS StuList
FROM student A
GROUP BY sName
) B
结果如下: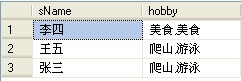
分析: 好的,那么我们来分析一下,首先看这句:
WHERE sName=A.sName
FOR XML PATH('')
这句是通过FOR XML PATH 将某一姓名如张三的爱好,显示成格式为:“ 爱好1,爱好2,爱好3,”的格式!
那么接着看:
剩下的代码首先是将表分组,在执行FOR XML PATH 格式化,这时当还没有执行最外层的SELECT时查询出的结构为:

可以看到StuList列里面的数据都会多出一个逗号,这时随外层的语句:SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby 就是来去掉逗号,并赋予有意义的列明!
二、with (nolock)的介绍和使用。
为了性能,往往会在表后面加一个nolock,或者是with(nolock),其目的就是查询是不锁定表,从而达到提高查询速度的目的。
什么是并发访问:同一时间有多个用户访问同一资源,并发用户中如果有用户对资源做了修改,此时就会对其它用户产生某些不利的影响,例如:
1:脏读,一个用户对一个资源做了修改,此时另外一个用户正好读取了这条被修改的记录,然后,第一个用户放弃修改,数据回到修改之前,这两个不同的结果就是脏读。(即B用户读取了一个A用户没有提交事务的数据(rollback transaction),这样读出来的数据是属于脏数据)
小结:NOLOCK 语句执行时不发出共享锁,允许脏读 ,等于 READ UNCOMMITTED事务隔离级别
。nolock确实在查询时能提高速度,但它并不是没有缺点的,起码它会引起脏读。
nolock的使用场景(个人观点):
NOLOCK 可能把没有提交事务的数据也显示出来.
1:数据量特别大的表,牺牲数据安全性来提升性能是可以考虑的;
2:允许出现脏读现象的业务逻辑,反之一些数据完整性要求比较严格的场景就不合适了,像金融方面等。
3:数据不经常修改的表,这样会省于锁定表的时间来大大加快查询速度。
综上所述,如果在项目中的每个查询的表后面都加nolock,这种做法并不科学,起码特别费时间,不如行版本控制来的直接有效。而且会存在不可预期的技术问题。应该有选择性的挑选最适合的表来放弃共享锁的使用。
最后说下nolock和with(nolock)的几个小区别:
1:SQL05中的同义词,只支持with(nolock);
2:with(nolock)的写法非常容易再指定索引。
跨服务器查询语句时 不能用with (nolock)
只能用nolock
同一个服务器查询时
则with (nolock)和nolock都可以用
比如
SQL code
select * from [IP].a.dbo.table1 with
(nolock) 这样会提示用错误select * from a.dbo.table1
with (nolock) 这样就可以
三、数据表死锁
如果对某一个进行了事务操作,如果该操作最后完成没有提交事务或者回滚事务。则表差生死锁状态。
例如:
BEGIN TRANSACTION
insert into tableA values(。。。。)
此时没有Commit transaction或者Rollback transaction操作,则tableA将被死锁。
四、Output和Output into 语句的使用。
参考CSDN资料:http://msdn.microsoft.com/zh-cn/library/ms177564(SQL.105).aspx#
A. 将 OUTPUT INTO 用于简单 INSERT 语句
以下示例将行插入soloreztest表,并使用 OUTPUT 子句将语句的结果返回到 @mytable table 变量中
declare @mytable table
(
id int identity(1,1) primary key,
name varchar(50)
)
insert into soloreztest output inserted.name into @mytable values('147')
select * from soloreztest
select * from @mytable
结果是:

output into子句是将向soloreztest表里面的数据同步的插入的@mytable的表变量里面
output 子句则只是用于显示被改变的数据INSERTED 或 DELETED 前缀
inserted 前缀:用于检索新插入表中或是更新后的数据的数据 可用与insert和update语句中不能在delete语句中出现
deleted 前缀: 用于检索被删除或是更新前的数据 可用与delete和update语句中不能在insert 语句中出现
B. 将 OUTPUT 用于 DELETE 语句
以下实例是将在表中soloreztest删除行是放回被删除行的信息
delete soloreztest output deleted.* where id=2
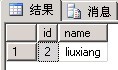
同理以上也可使用会 output into语句将被删除的信息插入到一个新表中
C. 将 OUTPUT 用于 UPDATE
以下实例将在表中更新数据是使用output 返回修改前的数据和修改后的数据
update soloreztest set name='zz' output inserted.name,deleted.name where id=3

inserted.name:表示的是在 soloreztest表中更新后的数据内容。
deleted.name :表示的是在soloreztest表中的更新前的数据内容。
四、with as 语句
参考文章:http://www.cnblogs.com/fygh/archive/2011/08/31/2160266.html
好处:
1) WITH AS存储过程中使用,声明了就一定要用,不然会报错.
2) 存储过程中如果有select 好像就一定得有into......
3) 复杂的查询会产生很大的sql,with as语法显示一个个中间结果,显得有条理些,可读性提高
4) 前面的中间结果可以被语句中的select或后面的中间结果表引用,类似于一个范围仅限于本语句的临时表,在需要多次查询某中间结果时可以提升效率
例子:
with t as (select * from emp where depno=10)
select * from t where empno=xxx
再举个简单的例子
with a as (select * from test)
select * from a;
其实就是把一大堆重复用到的SQL语句放在with as 里面,取一个别名,后面的查询就可以用它
这样对于大批量的SQL语句起到一个优化的作用,而且清楚明了
是个临时存储,一般是在存储过程里使用的
可以做多个表的连接,结果集的连接查询

