一,大数据的基本公式:

机器学习就是在获得很多组的x数据和y数据以后获得F映射的一个过程
深度学习是机器学习的一部分,就是在获得data后提取出x数据的过程
如果数据y用来模仿人类的行为,例如自动驾驶等,就称其为人工智能
二,机器学习方法分类:
1,有监督学习
就是数据y包含已经有的结果标签
用处:回归,分类
2,无监督学习
只有数据x,没有结果数据y
用处:聚类,降维,排序,密度估计,关联规则挖掘
3,强化学习
没有数据,通过模拟和观察生成数据进行学习
三,机器学习基本概念:
数据集:一组样本的集合
样本:一条数据的一行
特征:样本里面每一个可变的数据
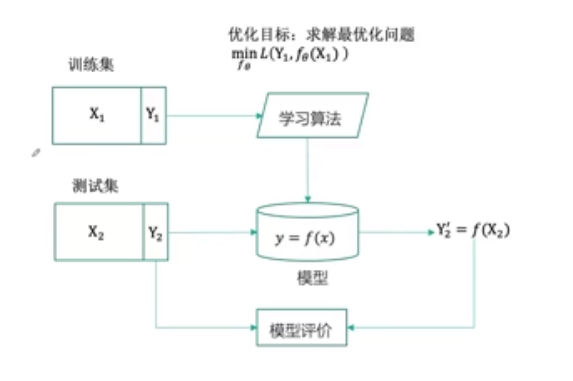
训练集:用来训练模型
测试集:用于测试模型
模型:建立数据x和数据y的映射关系
损失函数:和实际值进行对比
优化目标:
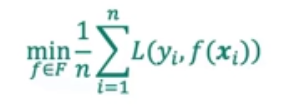
机器学习一般流程:
四, 常见问题
过度拟合问题:模型过于复杂,导致对已知数据预测很好,对未知预测很差
解决方法:

模型选择:
交叉验证,重复使用数据
机器学习的数学结构:
度量结构:
以文章相似度为例:
以字为坐标,字频为坐标值,将其表示为一个向量,然后两个文章求余弦,得出相似度
网络结构:
提取中心句为例:
将文本分成句子,将句子进行相似度比对,将句子连成网络形式
选出出度,入度最大的即为中心句
代数结构:
集合结构:
..........