它具有检错和纠错的功能。海明码中的全部传输码字是由原来的信息和附加的奇偶校验位组成的。每一个这种奇偶校验位和信息位被编在传输码字的特定位置上。这种系统组合方式能找出错误出现的位置,无论是原有信息位,还是附加校验位。
设海明码校验位为k,信息位为m,则它们之间的关系应满足m+k+1≤2的k次方。
下面以原始信息101101为例,讲解海明码的推导与校验过程。
(1)确定海明码校验位长
m是信息位长,则m=6 。根据上述关系式m+k+1≤2的k次方,得到7+k≤2的k次方。解得最小k为4,即校验位为4。信息位加校验位总长度为10位。
(2)推导海明码
1.填写原始信息。从理论上讲,海明码校验位可以放在任何位置,但习惯上校验位被从左到右安排在1、2、4、8、...的位置上。原始信息则从左至右填入剩下的位置。如图1所示,校验位处于B1、B2、B4、B8位,剩下位为信息位,信息位依从左至右的顺序先行填写完毕。
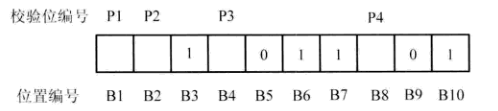
图1 填入原始信息位
2.计算校验位。依据公式得到校验位:
P1=B3⊕B5⊕B7⊕B9=1⊕0⊕1⊕0=0 P2=B3⊕B6⊕B7⊕B10=1⊕1⊕1⊕1=0 P3=B5⊕B6⊕B7=0⊕1⊕1=0 P4=B9⊕B10=1⊕1=0注:⊕表示异或运算。
这个公式常用,但是死记硬背很困难,要换个方式去理解记忆。
把除去1、2、4、8(校验位位置值编号)之外的3、5、6、7、9、10这些值转换为二进制位,如表1所示。
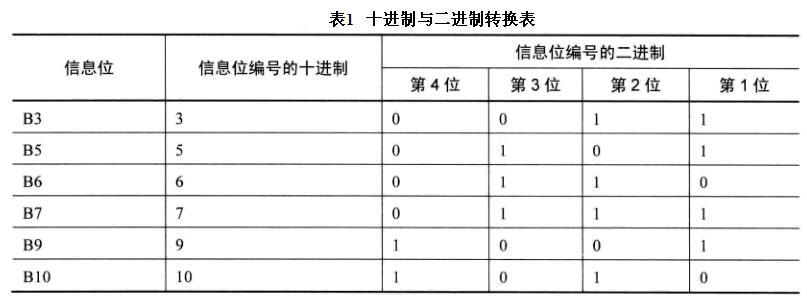
将所有信息编号的二进制的第1位为1的Bi进行“异或”操作,结果填入P1。即上述的结果P1=B3⊕B5⊕B7⊕B9=1⊕0⊕1⊕0=0;
同理,将所有信息编号的二进制的第2位为1的Bi进行“异或”操作,结果填入P2。即上述结果P2=B3⊕B6⊕B7⊕B10=1⊕1⊕1⊕1=0;
以此类推,将所有信息编号的二进制的第3位为1的Bi进行“异或”操作,结果填入P3;将所有信息编号的二进制的第4位为1的Bi进行“异或”操作,结果填入P4。
将计算好的结果,填入校验位后得到图2。
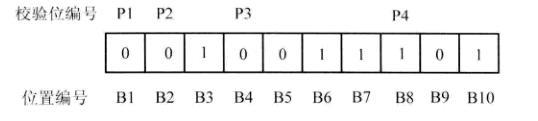
图2 加入校验码后的信息
(3).校验
将所有信息位位置编号1~10的值转换为二进制位,如表2所示。
表2 十进制与二进制转换表

将所有信息编号的二进制的第1位为1的Bi进行“异或”操作,得到X1;
将所有信息编号的二进制的第2位为1的Bi进行“异或”操作,得到X2;
将所有信息编号的二进制的第3位为1的Bi进行“异或”操作,得到X4;
将所有信息编号的二进制的第4位为1的Bi进行“异或”操作,得到X8。
即公式:
X1=B1⊕B3⊕B5⊕B7⊕B9 X2=B2⊕B3⊕B6⊕B7⊕B10 X4=B4⊕B5⊕B6⊕B7 X8=B8⊕B9⊕B10得到一个形式为X8X4X2X1的二进制,转换为十进制,结果为0,则无错;结果非0(假设结果为Y),则错误发生在第Y位。
假设起始端发送加了上述校验码信息之后(即0010011101),目的端收到的信息为0010111101,如图3所示。
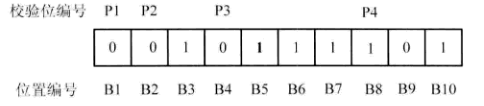
图3 接收信息
依据上一个公式,得到:
X1=B1⊕B3⊕B5⊕B7⊕B9=0⊕1⊕1⊕1⊕0=1 X2=B2⊕B3⊕B6⊕B7⊕B10=0⊕1⊕1⊕1⊕1=0 X4=B4⊕B5⊕B6⊕B7=0⊕1⊕1⊕1=1 X8=B8⊕B9⊕B10=1⊕0⊕1=0则将X8X4X2X1=0101的二进制转换为十进制,结果为5,非0,错误,而且错误发生在第5位。