考虑用机器学习建立一个邮件过滤系统,来将邮件分成垃圾邮件和非垃圾邮件。
首先我们建立一个词典,里面包含了邮件中所有的不重复单词。我们用长度为词典中单词数目的特征向量来表示一封邮件。如下所示:

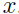 表示一封邮件,如果该邮件包含有词典中的第i个单词,那么
表示一封邮件,如果该邮件包含有词典中的第i个单词,那么 ,否则
,否则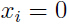 .
.
为了建模 ,作一个很强的假设,假设词典中的每个单词是否包含在某一封邮件中是彼此独立的,这个假设其实显然不正确(一封垃圾邮件出现了“发票”字样,往往就会出现“贷款等字样”),但是这种“错误(Naive)”假设在应用中却有着不俗的表现,所以今天才有学习讨论的意义。这种假设就被称为朴素贝叶斯假设(Naive Bayes (NB) assumption),因之而生的算法就是朴素贝叶斯分类器(Naive Bayes classifier).
,作一个很强的假设,假设词典中的每个单词是否包含在某一封邮件中是彼此独立的,这个假设其实显然不正确(一封垃圾邮件出现了“发票”字样,往往就会出现“贷款等字样”),但是这种“错误(Naive)”假设在应用中却有着不俗的表现,所以今天才有学习讨论的意义。这种假设就被称为朴素贝叶斯假设(Naive Bayes (NB) assumption),因之而生的算法就是朴素贝叶斯分类器(Naive Bayes classifier).
假设词典中有50000个单词,在朴素贝叶斯假设下:
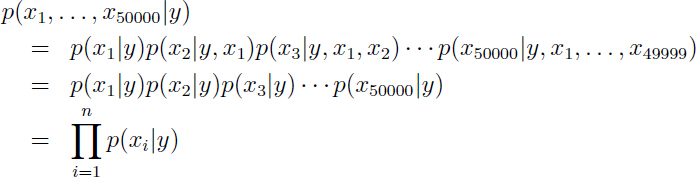
模型的参数:
Φi|y=1 = p(xi = 1|y = 1), Φi|y=0 = p(xi =1|y = 0), Φy = p(y = 1).
对于给定的训练集{x(i),y(i);i=1, 2, ..., m},得到如下联合似然函数:

参数的最大似然估计为:

“∧”是表示“与”运算。
拟合出这些参数之后,我们可以对新邮件 进行预测:
进行预测:

自然p(y=0|x)=1-p(y=1|x),
比较属于两个类别的概率哪一个高,选出较高的概率对应的类别就是最终预测的类别。
拉普拉斯平滑(Laplace smoothing)
假如你第一次向NIPS(机器学习领域的顶级会议)投稿,于是在你的这封邮件中就会出现单词“nips”,假设“nips”是词典中的第35000个单词,那么根据上述分类器,
参数的最大似然估计就会如下:
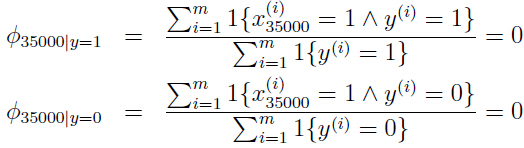
因为在之前的邮件中nips从来都没有出现过,所以在任何一种类型的邮件(垃圾邮件或者非垃圾邮件)中,第35000个单词出现的概率都是0.
因此,当系统试图预测一封邮件包含“nips”是否是垃圾邮件的时候,按照上面说的方法:

这是因为 中包含有p(x35000|y) =0. 下面好好分析产生这种现象的原因。
中包含有p(x35000|y) =0. 下面好好分析产生这种现象的原因。
统计中一种不恰当的现象:把之前从未发生的事件发生的概率估计为0.例如,给定m个独立事件集合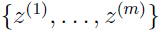 ,最大似然估计如下:
,最大似然估计如下:
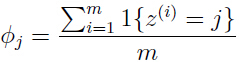
正如前面叙述的一样,假若某几个事件之前从未发生过,根据上面的式子,这就会导致一些 为0,这就是问题所在。为了避免这个问题,我们采用
为0,这就是问题所在。为了避免这个问题,我们采用
拉普拉斯平滑(Laplace smoothing),把上面的式子调整为:

对于这个等式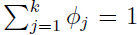 仍然满足.但是再也不会出现为0的现象了.
仍然满足.但是再也不会出现为0的现象了.
返回到朴素贝叶斯分类器,通过拉普拉斯平滑,可以得到参数的估计如下:
