上一专题GMM-HMM声学模型中讲述了其理论知识,这一章利用理论搭建一套GMM-HMM系统,来识别连续0123456789的英文语音。
本系统是单音素,未涉及后面三音子的训练以及决策树的内容。
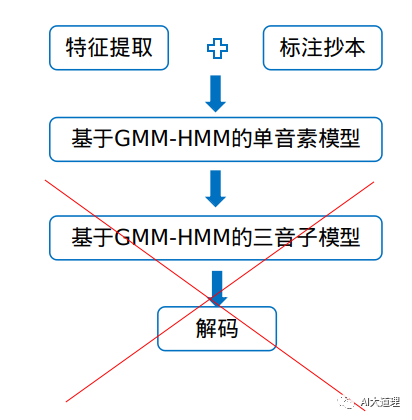
在GMM专题和HMM专题中分别讲述了其训练都是EM算法,那么融合形成GMM-HMM模型后会如何训练?是应用一个EM算法还是分别应用EM算法呢?
1 Viterbi解码
在HMM专题中,HMM解码有两种方法,分别为Viterbi算法和近似算法,本系统采用Viterbi算法进行解码。
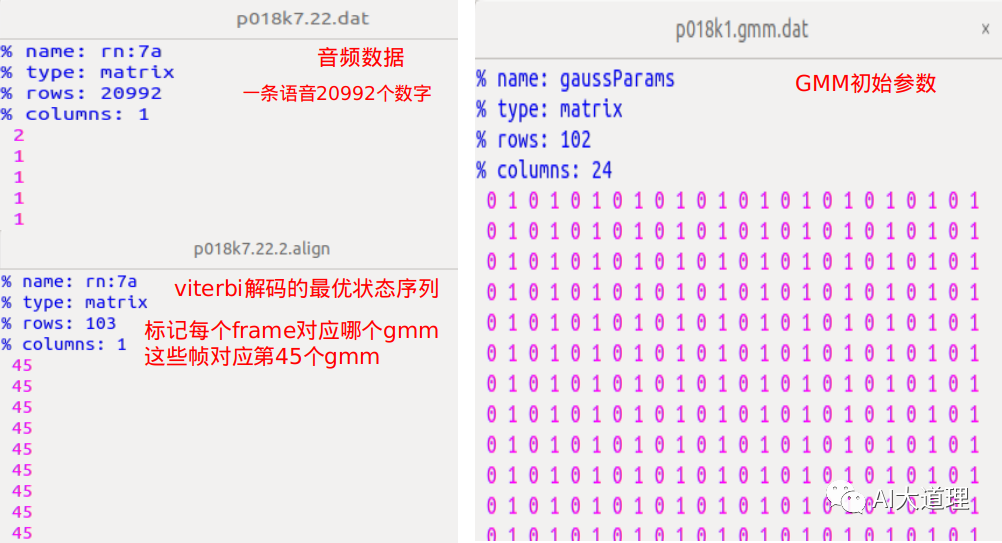
针对一句语料进行解码,提取该句语料特征:68*12,其中,68表示帧数,12表示MFCC特征。
预先训练了HMM对由孤立数字组成的数据的观察概率,这就是初始模型,将用来解码(识别、预测、测试)。
即给定模型λ=(A,B,Π)和观测序列O={o1,o2,...oT},求给定观测序列条件下,最可能出现的对应的状态序列。
Viterbi解码作为识别结果(预测结果),可以在此基础上进行优化训练模型。
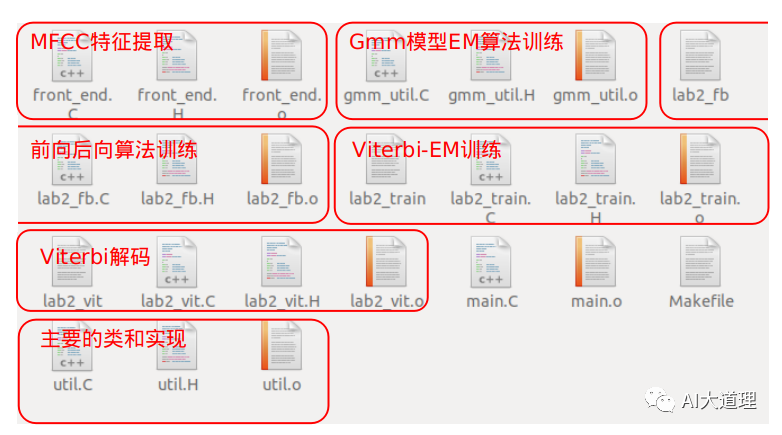
系统文件:

![]()
src/
![]()
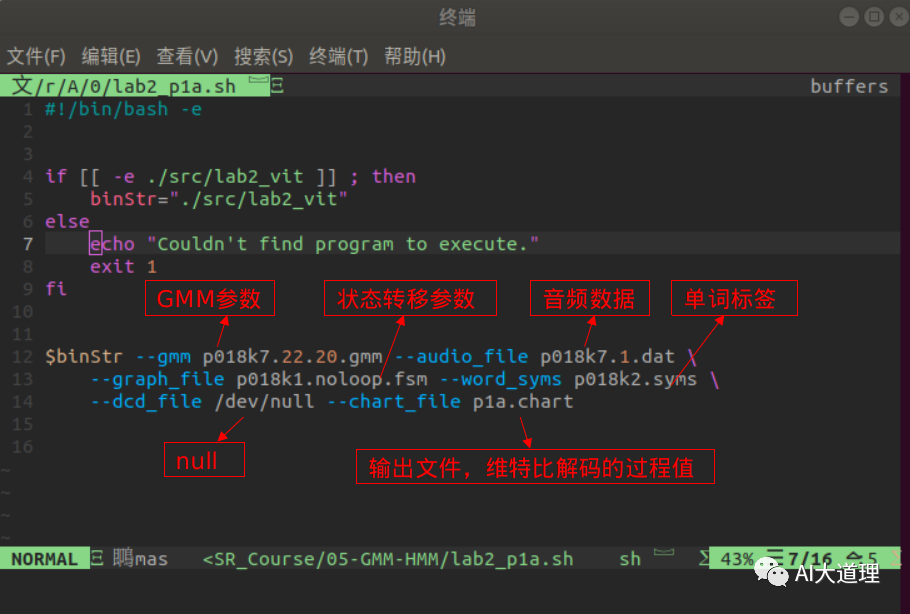
步骤一:传入音频数据
输入:GMM参数、状态转移参数、音频数据、单词标签
输出:chart
![]()

![]()
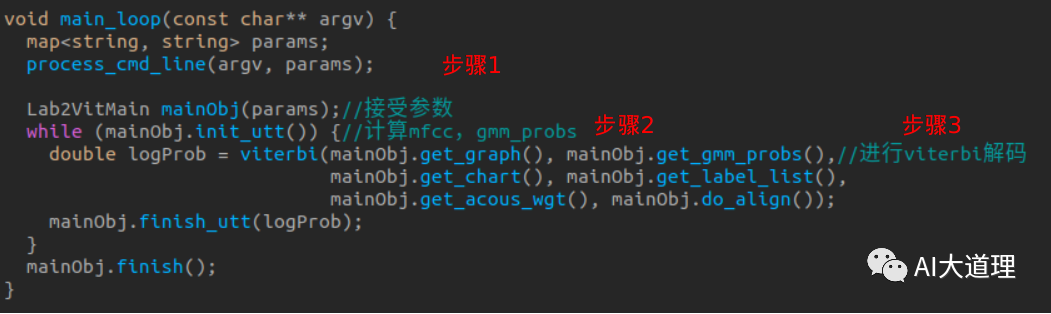
步骤二:前段信号处理(计算mfcc,gmm_probs等)
![]()
mainObj.init_utt():
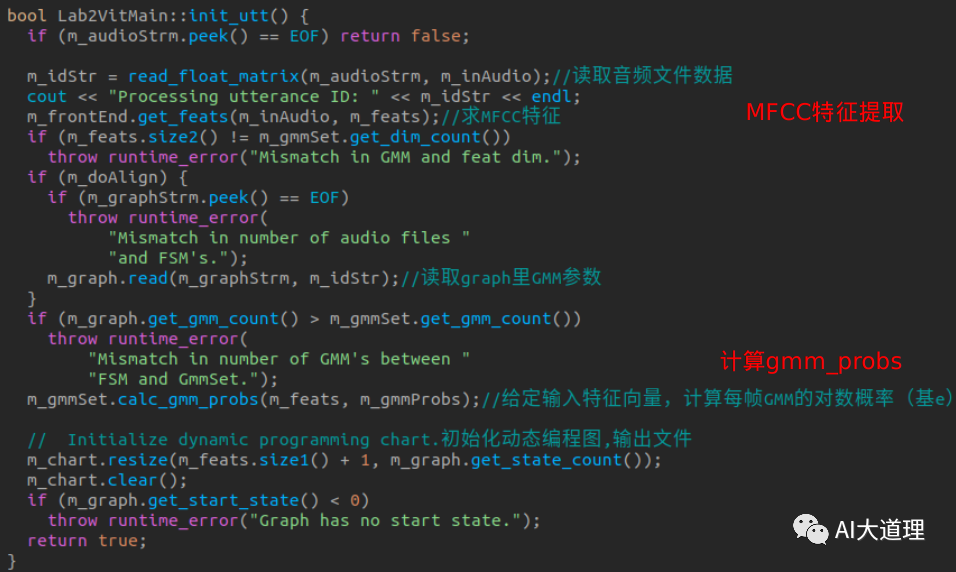
![]()
计算每帧MFCC特征:
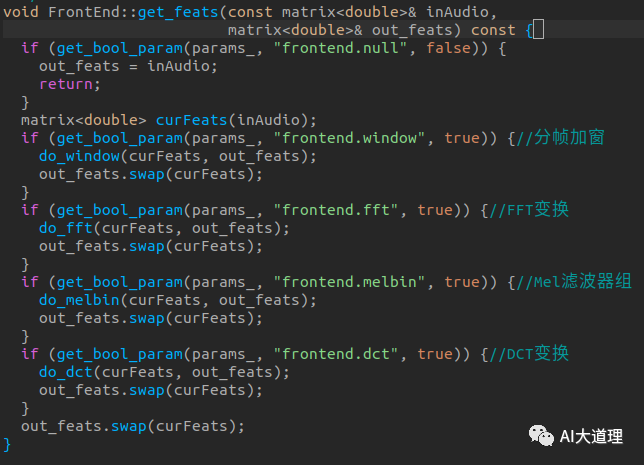
![]()
计算每帧gmm_probs:
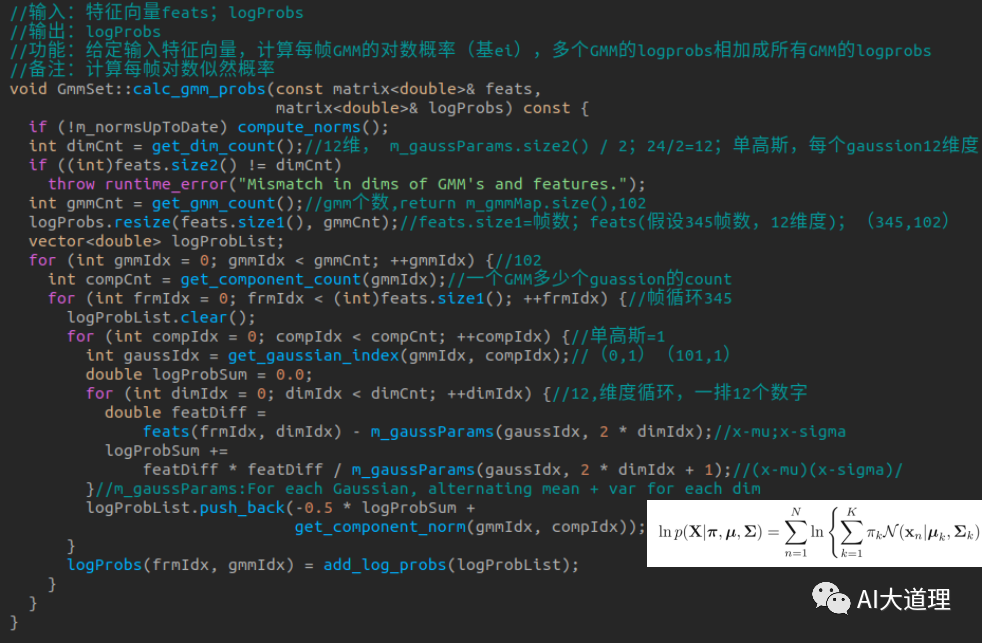
![]()
步骤三:Viterbi解码
随机数字串的识别网络:
串接HMM
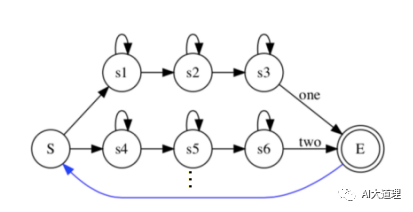
![]()
随机数字串的解码网络:
第一帧可从任意一个数字的HMM的开始状态开始,对比所有路径,选择概率最大的那条路径作为解码结果。
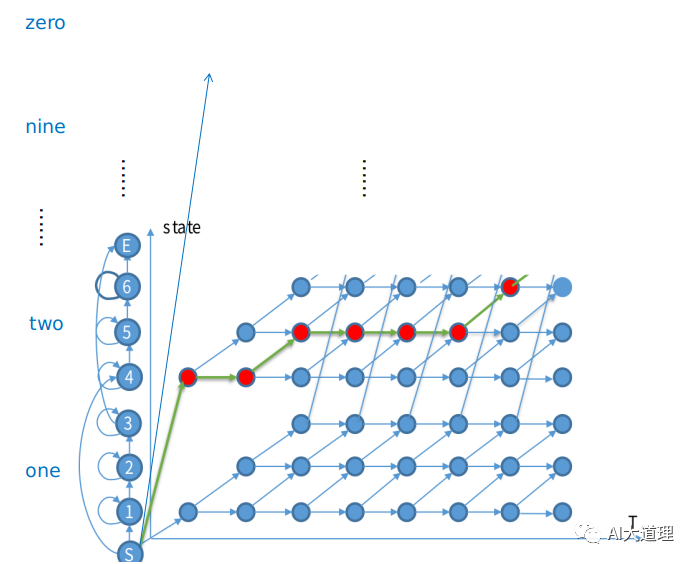
![]()
Viterbi算法流程:

![]()
算法实现:
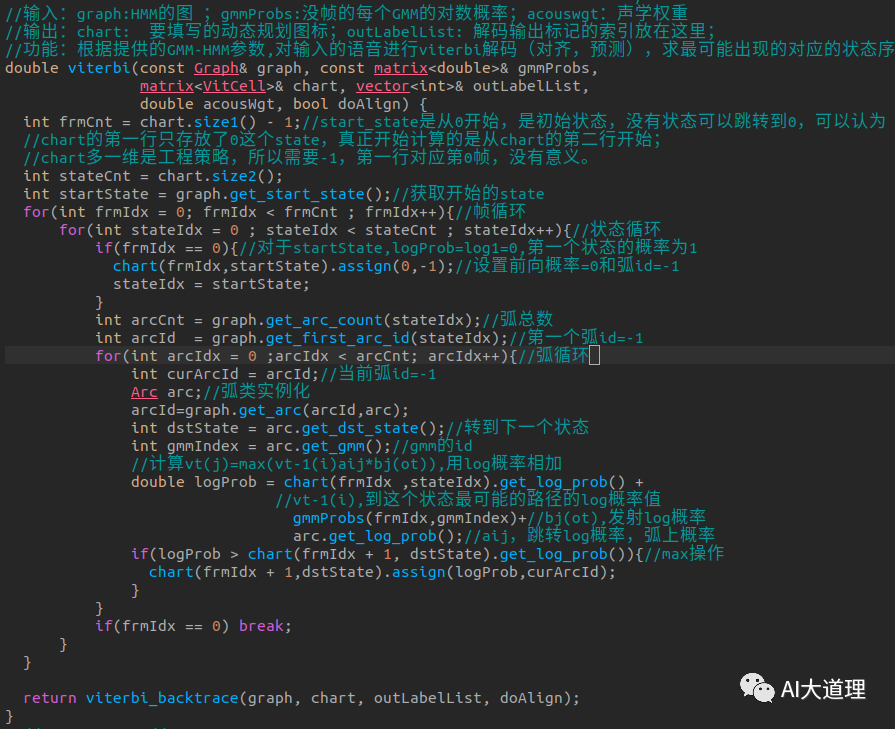
![]()
输出chart:

![]()
步骤四:Viterbi回溯
实际上chart图最后一帧即为最大似然概率对应的弧号,可以基于此回溯得到完成的弧号序列,弧号与状态之间存在映射关。
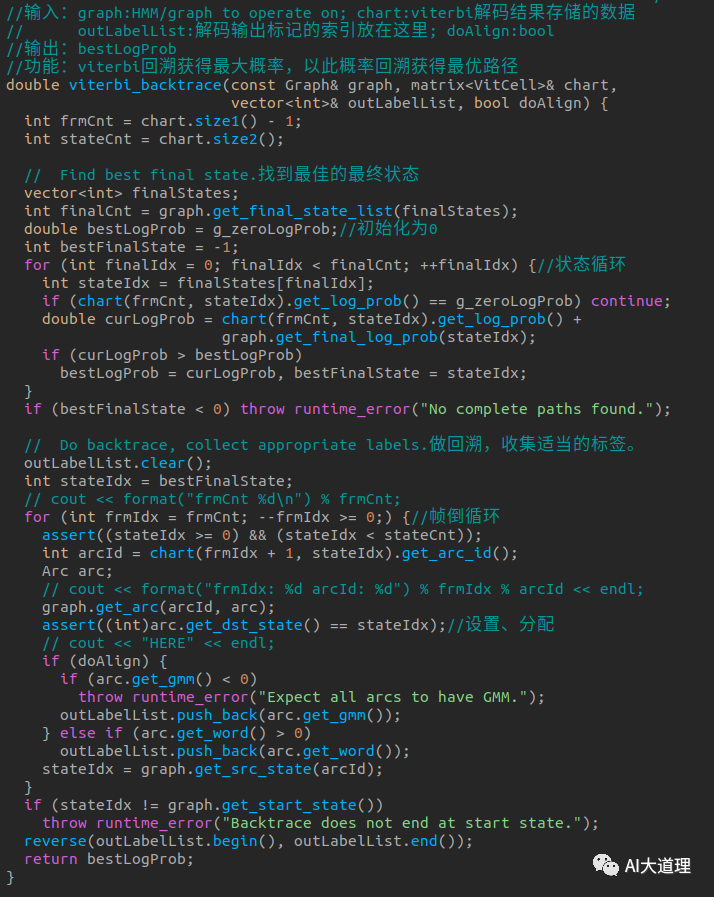
![]()
回溯结果:
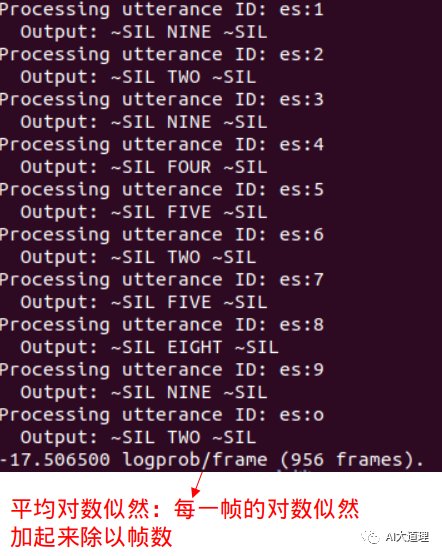
![]()
对于输入一段语音,解码结果为:
Nine Two Nine Four Five Two Five Eight Nine Two
(解码实际上是获得最可能的状态系列,状态可以组成音素,音素可以组成单词)
2 GMM训练
Viterbi-EM训练
上述Viterbi解码是为GMM-HMM训练做准备的,提供了对齐的数据。
在HMM专题中,HMM训练有两种方法,分别为Viterbi训练和Baum-Welch训练。
Viterbi学习算法是一种硬对齐,所谓硬对齐就是只有0或者1的归属,即一帧只归宿于某个状态,而Baum-Welch学习算法是一种软对齐,即一帧以一定概率归宿于某个状态。
模型的训练即给定观测序列O={o1,o2,...oT}和初始模型,调整模型λ=(A,B,Π)的参数,使该模型下观测序列的条件概率P(O|λ)最大。
(不能无中生有的训练一个λ=(A,B,Π),要有一个坏的初始模型为基础来调整参数。GMM参数训练必须依托于HMM,随着HMM的E步更新而更新)
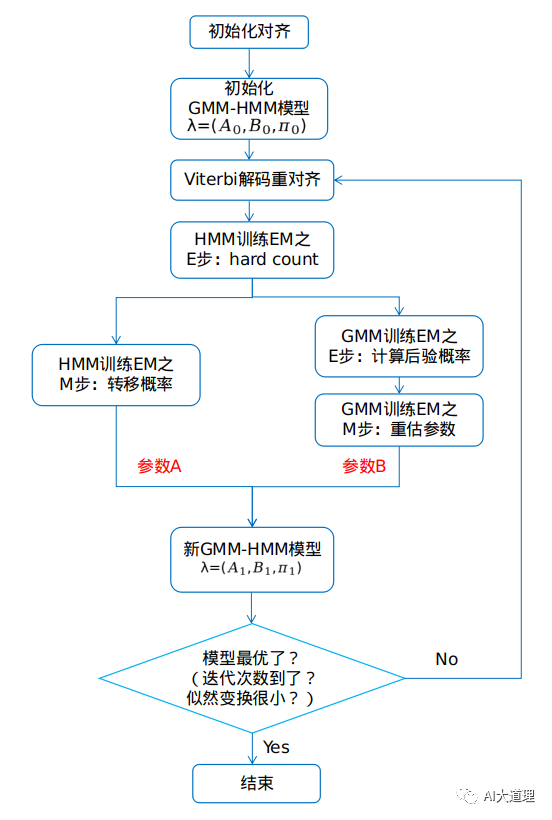
Viterbi-EM训练全过程:
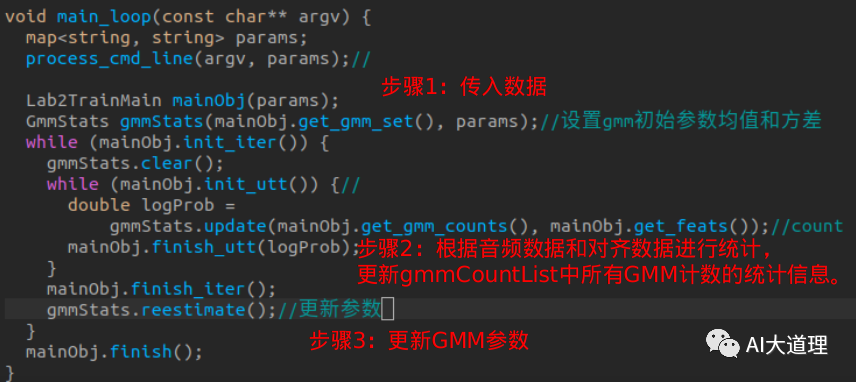
首先初始化对齐,平均分配帧给状态,可以得到初始GMM-HMM模型,利用初始模型和初始参数进行Viterbi解码,得到新的对齐。对齐后进行hard count。这里hard count 是HMM训练的E步,也是GMM训练的基础,GMM训练的数据就是count后得到的。
count后HMM可以进行M步得到转移概率,这就是模型中的A参数。GMM则在count基础上进行E步计算后验概率,再进行M步得到新的均值和方差参数,这是模型中的B参数。
至于Π,就是[1,0,0,0...],一开始在状态一的概率是100%。
在语音识别应用中由于HMM是从左到右的模型,第一个必然是状态一,即P(q0=1)=1。所以没有pi这个参数了。
![]()
注释:
没有考虑HMM中所有可能的路径来计算每个帧处每个弧的后验计数,而是使用维特比解码来找到HMM中的单个最可能路径。
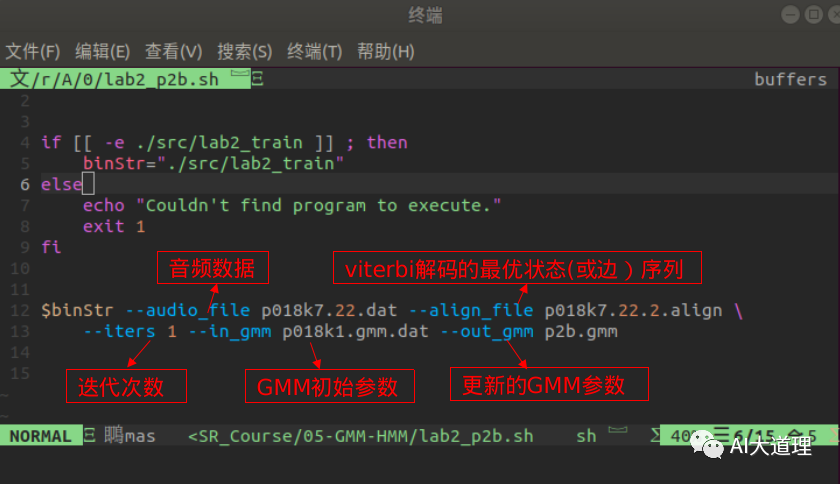
步骤一:传入数据
输入:初始GMM参数、Viterbi解码的最优状态序列、音频数据、迭代次数
输出:新GMM参数
![]()
![]()
步骤二:HMM的E步:hard count
![]()
gmmStates.updata():
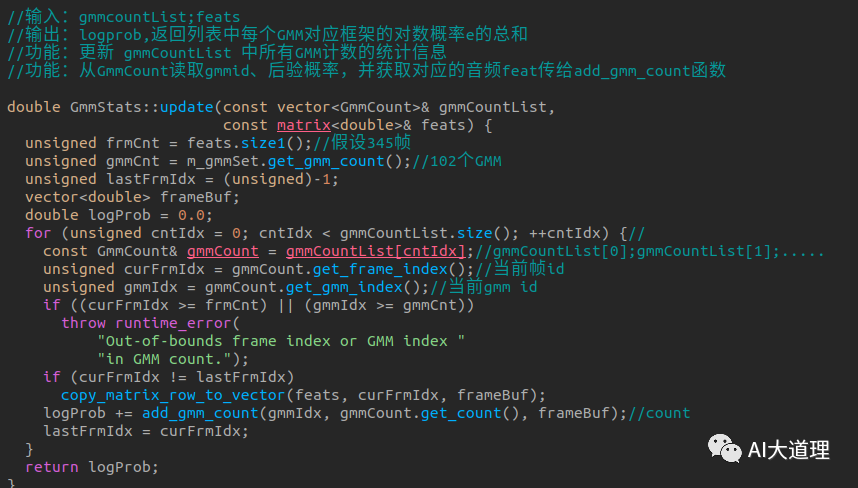
![]()
步骤三:GMM的EM步
add_gmm_count:
根据count获得多少帧对应一个状态,而这个状态对应着一个GMM,以这些帧的数据重新计算GMM参数。

![]()
步骤四:更新GMM参数
gmmStates.reestimate():
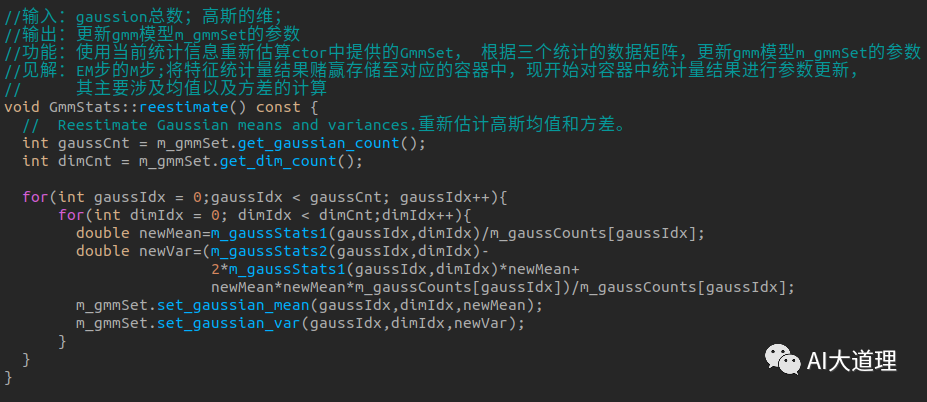
![]()
GMM新参数与初始参数对比:
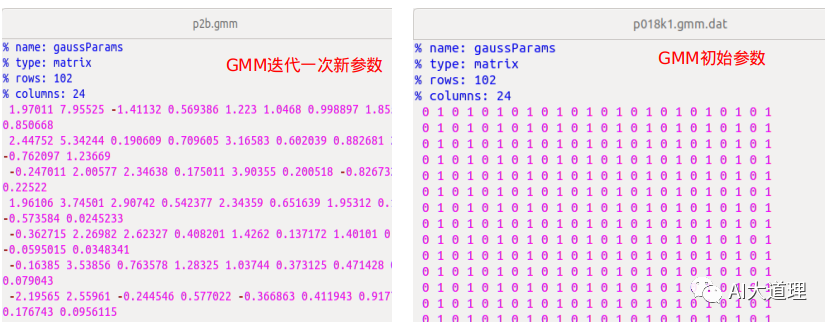
![]()
3 前向后向算法训练
基于Viterbi-EM算法来估计模型对于计算语料中帧对应状态的弧号存在计算复杂度指数级增加的问题,为解决上述问题,可以用前向后向算法来估计模型中参数。
Baum-Welch学习算法也叫前向后向算法,是一种软对齐,即一帧以一定概率归宿于某个状态。
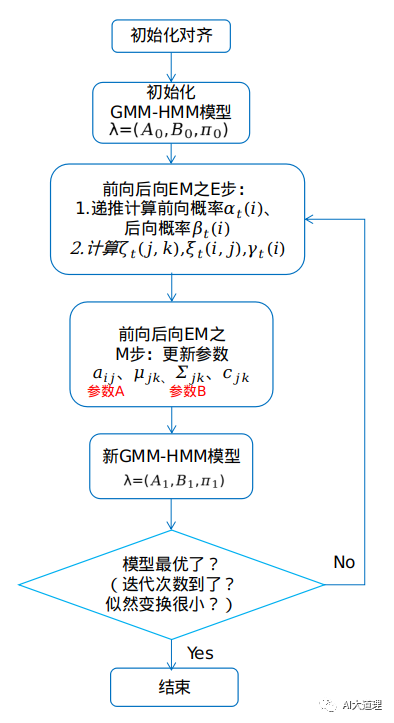
Baum-Welch训练全过程:
首先初始化对齐,平均分配帧给状态,可以得到初始GMM-HMM模型(也可以任意初始化所有参数),利用初始模型和初始参数进行Baum-Welch算法。
Baum-Welch算法考虑所有的路径,对于某个状态,将所有时刻的状态占用概率相加,可以认为是一个软次数,即进行soft count,估计状态占用概率(期望),即EM算法的E步。
基于估计的状态占用概率,重新估计参数 λ (最大化),即EM算法的M步。
至于Π,就是[1,0,0,0...],一开始在状态一的概率是100%。在语音识别应用中由于HMM是从左到右的模型,第一个必然是状态一,即P(q0=1)=1。所以没有pi这个参数了。
![]()
注释:
我们的词汇由十二个单词(一到九,零,OH和静默)组成,总共包含34个音素。每个音素使用3个HMM状态(不包括nal状态),总共有102个状态。这些状态中的每一个都有我们需要向其分配概率的两个输出弧,以及我们需要进行估计的GMM/高斯曲线。为简单起见,我们将忽略转移概率(将它们全部设置为1)。实际上,转移概率对性能的影响很小。
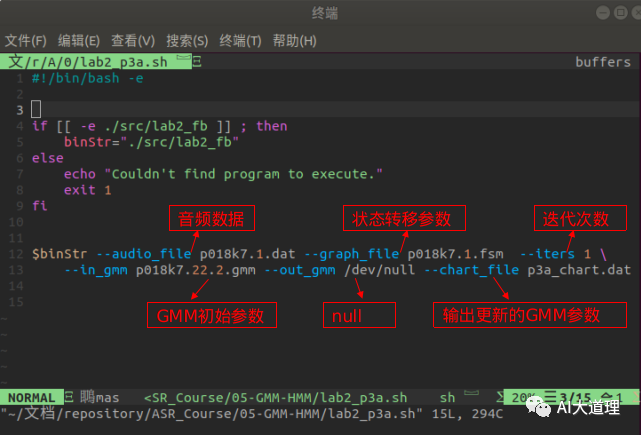
步骤一:传入数据
输入:初始GMM参数、状态转移参数(fsm图)、音频数据、迭代次数
输出:更新后GMM参数
![]()

![]()
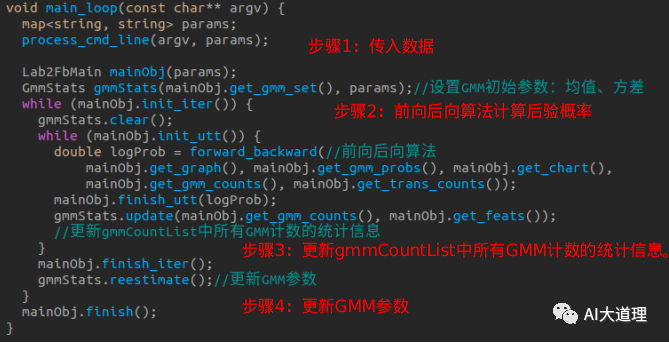
步骤二:前向后向算法计算后验概率
![]()
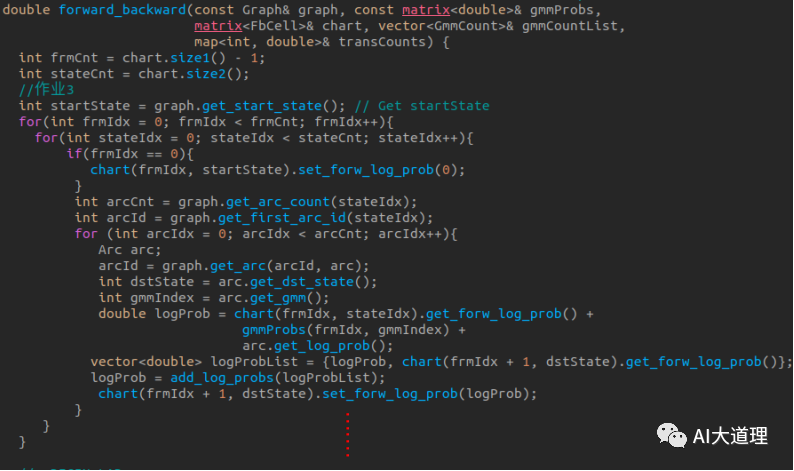
forward_backward():

![]()
算法实现:
![]()
步骤三:GMM的EM步(与上同)
gmmStates.update()
步骤四:更新GMM参数(与上同)
gmmStates.reestimate()

![]()
![]()
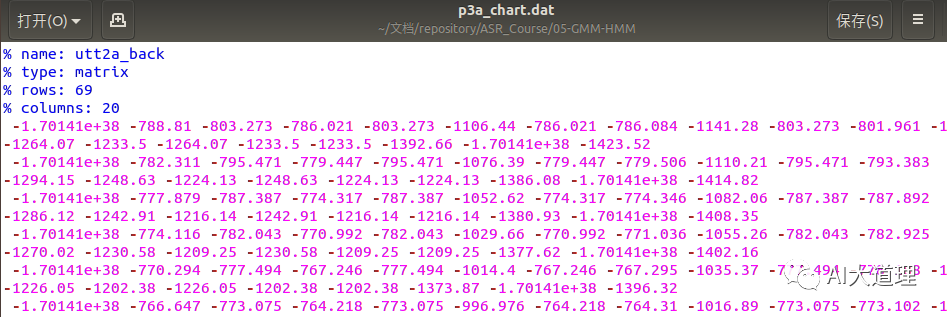
![]()
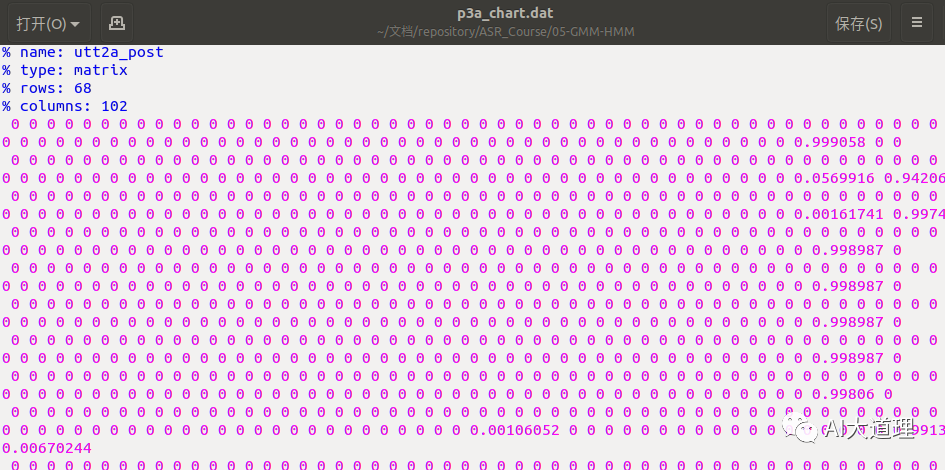
![]()
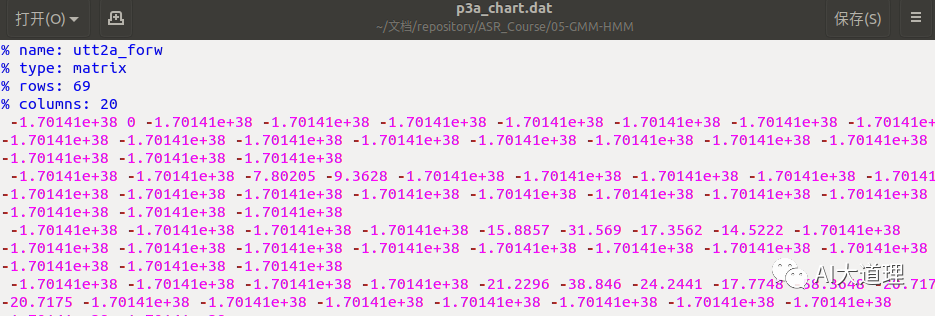
最终将前向概率与后向概率以及gmm模型的权重写入值chart图中,其中gmm权重在代码中表示为后验概率,最后后验概率表示如下图所示。
从上图可知,gmm权重大部分为0,这样大大减少了模型计算量且便于参数计算。
4 GMM-HMM模型测试
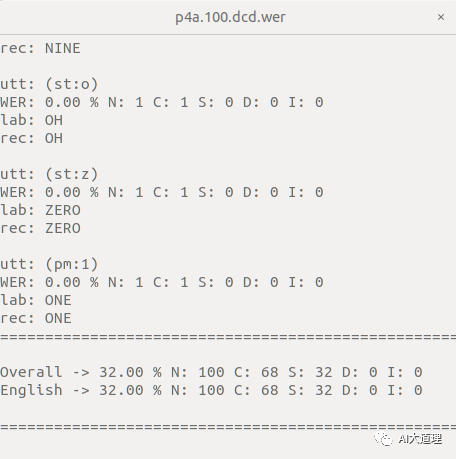
![]()
这是前向后向算法进行五次迭代训练出来的GMM-HMM模型。其中N是num总数,C是corr准确数,S是sub替换错误,D是Del是删除错误,I是INS插入错误。
模型识别率为68%。
5 总结
如果不是针对数字,而是所有普通词汇,可能达到十几万个词,解码过程将非常复杂,识别结果组合太多,识别结果不会太理想。因此需要引入语言模型来约束识别结果。让“今天天气很好”的概率高于“今天天汽很好”的概率,得到声学模型概率高,又符合表达的句子。
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号

![]()
欢迎加入!

![]()
▼
下期预告
▼
AI大语音(十)——语言模型
▼
往期精彩回顾
▼
AI大语音(一)——语音识别基础
AI大语音(二)——语音预处理
AI大语音(三)——傅里叶变换家族
AI大语音(四)——MFCC特征提取
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(六)——混合高斯模型(GMM)
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(八)——GMM-HMM声学模型