Before
在实现一个例子之前,首先要明确自己想要获得怎样的结果:爬取近六年出版评分在7分以上的漫画
最后我想要得到的信息是所有满足要求的书名
要求有二:1、近六年出版,即出版时间 >= 2013年 2、评分在7分以上
接下来针对我们的要求,去观察页面元素
我们观察一下页面(https://book.douban.com/tag/%E6%BC%AB%E7%94%BB?start=0&type=T),找到这两点信息的位置(图中黄色底部分信息)
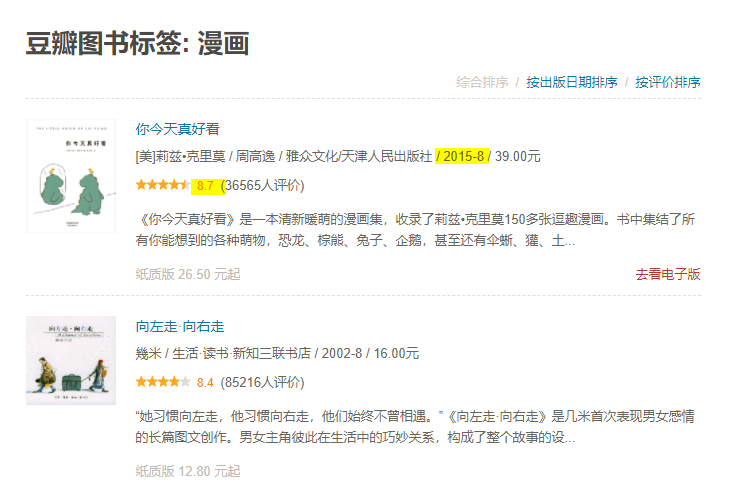
在检查元素里找到这两点信息的位置:年份信息包含在一个class为"pub"的标签中

评分信息包含在class为star clearfix的div标签的子标签span:class为rating_nums的信息中
注意:因为在后面爬虫的时候发现中间有些页面因为没有评分而没有class为rating_nums的标签,因此在爬取评分信息的时候
我们要先找到star clearfix 的这个div标签,再对具体情况进行处理

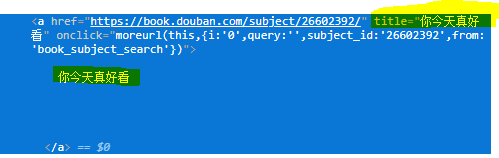
书名:在包含title元素的a标签中
结束上述准备以后,明确我们要提取的信息
1、书名:在包含title元素的a标签中
2、出版年份:在class为'pub'的div信息中
3、评分:在class为star clearfix的div标签的子标签span:class为rating_nums的信息中
本例中使用的网页解析工具是BeautifulSoup,比较好上手,合适网路爬虫初学者的一个可以代替正则表达式的网页解析工具
首先要安装,可以直接使用pip进行安装
安装代码:pip install bs4
安装成功后就可以直接在python环境下使用这个包里的内容了
接下来就可以开始去构造爬虫
import内容如下
1 import urllib.request 2 from bs4 import BeautifulSoup 3 import re 4 import time #豆瓣robots.txt文件限制了爬取的时间速度间隔最低为5s,因此需要自行限速,避免被禁
初始化访问urllist列表
1 ''' 2 构建访问url列表 3 ''' 4 urllist=[] 5 for i in range(1, 51): #初始化urllist,注意到地址的不同要分开对待 6 if i > 1: 7 urllist.append('https://book.douban.com/tag/%%E6%%BC%%AB%%E7%%94%%BB?start=%s0&type=T' % i) # 遍历2到50页的数据 8 else : 9 urllist.append('https://book.douban.com/tag/%E6%BC%AB%E7%94%BB?start=0&type=T') 10 # for i in urllist: 11 # print(i)
构造爬虫信息筛选函数,返回每一页符合条件的书名列表(详细解释见备注)
1 def choose_comics(url): 2 page = urllib.request.urlopen(url) # BeautifulSoup本身并不能访问网页,所以需要使用urllib库或者requests库去获取网页源代码,再交给BeautifulSoup进行处理 3 bsoup = BeautifulSoup(page,'lxml') # 此处后面要标明'lxml',不然会产生未写明解析器警告 4 5 # print(bsoup.text) 6 ''' 7 根据before中梳理的筛选信息的思路写出从源代码筛选目的数据的语句 8 ''' 9 title = [t['title'] for t in bsoup.find_all('a',title=True)] # title获取所有a标签中title内的元素 10 grade = [t.text for t in bsoup.find_all('div',class_ ='star clearfix')] #首先获取star clearfix模块内的内容 11 publication_date = [t.text for t in bsoup.find_all('div', class_='pub')] 12 # print(grade) 13 14 for i in range(len(grade)): 15 if (re.search(r'.*?([0-9]+.[0-9]).*?',grade[i])) :# 寻找star clearfix模块中是否存在浮点数,即有评分,否则用0分代替 16 grade[i]=re.search(r'.*?([0-9]+.[0-9]).*?',grade[i]).group() 17 # print(grade[i]) 18 else : 19 grade[i]='0.0' 20 ''' 21 上面这个二次筛选信息循环读取评分的处理是为了保证每一个书名对应序号在grade列表中都有对应的评分 22 不至于因为出现没有评分而出现匹配异常的情况 23 ''' 24 25 26 # print(title) 27 28 # print(publication_date) 29 # for i in range(len(grade)): 30 # if grade[i] == '' : 31 # grade[i] = "0.0" 32 33 print(grade) # 为了调试用的输出语句,可删去 34 35 book_list=[] 36 # if len(grade) == len(publication_date): 37 ''' 38 对已经获得的list信息进行筛选,把符合出版年份在2013年以后以及评分在7分以上的书本添加到book_list中 39 函数最后返回符合条件的一个书名列表 40 ''' 41 for i in range(len(title)): 42 if grade[i] : 43 grade_book = float(grade[i]) 44 pattern = re.compile(r'.*?20(d+).*?') 45 if re.findall(pattern,publication_date[i]) : 46 date_book = re.findall(pattern,publication_date[i])[0] 47 date_book = int('20' + date_book) 48 if (date_book >= 2013 and grade_book >= 7.0) : 49 book_list.append(title[i]) 50 51 return book_list
函数的调用与结果输出:
1 ''' 2 调用part 3 ''' 4 all_books=[] 5 for url in urllist: 6 time.sleep(5) 7 all_books.extend(choose_comics(url)) 8 all_books = list(set(all_books)) 9 ''' 10 结果展示 11 ''' 12 for item in all_books: 13 print(item)
实际在用的时候可以把结果列表转为csv存到数据中,不过目前我还不会这个……以后看看能不能导出来
最后贴一个爬下来的数据截图!