作为一个Anndroid开发人员来说,我们大多数情况下时使用的Java语言,自然在一些数据的处理时,使用到的集合框架也是Java的,比如HashMap、HashSet等,但是你可否知道,Android因为自身特殊的需求,也为自己量身定制了“专属”的集合类,查阅官方文档,android.util包下,一共捕获如下几个类:SparseArray系列(SparseArray,SparseBooleanArray,SparseIntArray,SparseLongArray,LongSparseArray),以及ArrayMap、ArraySet,我相信即便没学过,看到这些类名,基本也能猜到一些它们的区别和用法了,下面我们就来好好学一学它们,开始吧!
目录
1.使用方法
2.感受设计之美
3.优缺点及应用场景
正文
使用方法
按照我的习惯,我觉得不管学什么,首先需要的就是会用“它”,感受一下它的用法,其次才能再谈理论上的东西,下面我们先来学一学怎么使用。
首先我们看一下SparseArray的使用方法
//声明
SparseArray<String> sparseArray= new SparseArray<>();
//增加元素,append方式
sparseArray.append(0, "myValue");
//增加元素,put方式
sparseArray.put(1, "myValue");
//删除元素,二者等同
sparseArray.remove(1);
sparseArray.delete(1);
//修改元素,put或者append相同的key值即可
sparseArray.put(1,"newValue");
sparseArray.append(1,"newValue");
//查找,遍历方式1
for(int i=0;i<sparseArray.size();i++){
Log.d(TAG,sparseArray.valueAt(i));
}
//查找,遍历方式2
for(int i=0;i<sparseArray.size();i++){
int key = sparseArray.keyAt(i);
Log.d(TAG,sparseArray.get(key));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
OK,很正常的使用方法,和hashmap 等数据结构基本一样。
唯一不同的就是key和value的类型,hashmap的key值和value值为泛型,但是SparseArray 的key值只能为int 类型,value值为Object类型,看到这,你可能会觉得很奇怪,这不是在使用上受到了很大的约束嘛,这样约束的意义何在呢?
先别急,我们看看剩下的SparseArray 的双胞胎兄弟姐妹们,LongSparseArray 和SparseArray 相比,唯一的不同就是key值为long,所以,既然为long ,那么相对SparseArray 来说,它可以存储的数据元素就比SparseArray 多。
顺带温习一下,int的范围是-2^31 到 231-1,而long是-263 到 2^63-1
然后轮到了SparseBooleanArray,SparseIntArray,SparseLongArray,这三兄弟相对SparseArray 来说就是value值是确定的,SparseBooleanArray的value固定为boolean类型,SparseIntArray的value固定为int类型,SparseLongArray的value固定为long类型。
注意这里的value中的值类型boolean、int、long都是小写的,意味着是基本类型,而不是封装类型
稍作总结一下,如下
SparseArray <int, Object>
LongSparseArray <long, Object>
SparseBooleanArray <int, boolean>
SparseIntArray <int, int>
SparseLongArray <int, long>
- 1
- 2
- 3
- 4
- 5
ok,然后我们再看看ArrayMap和ArraySet 的使用
ArrayMap<String,String> map=new ArrayMap<>();
//增加
map.put("xixi","haha");
//删除
map.remove("xixi");
//修改,put相同的key值即可
map.put("xixi2","haha");
map.put("xixi2","haha2");
//查找,通过key来遍历
for(String key:map.keySet()){
Log.d(TAG,map.get(key));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
OK,很正常的用法,和HashMap无异。ArraySet就不用我继续说了吧,它们的关系就像HashMap和HashSet一样,它和HashSet都是不能存储相同的元素。
额外说明一下,ArraySet使用要求sdk最小版本为23,也就是minSdkVersion值必须大于等于23
感受设计之美
由于SparseArray 的三兄弟原理上和SparseArray 一样,所以我们先来看SparseArray的设计思想
首先,我们来到SparseArray的源码,其中定义了如下一些成员
private static final Object DELETED = new Object();
private boolean mGarbage = false;
//需要说明一下,这里的mKeys数组是按照key值递增存储的,也就是升序,这个在查找会讲到为什么要保证升序
private int[] mKeys;
private Object[] mValues;
private int mSize;
- 1
- 2
- 3
- 4
- 5
- 6
比较简单,一共五个字段,DELETED是一个标志字段,用于判断是否删除(这个后面分析到了,自然会就明白了),mGarbage也是一个标志字段,用于确定当前是否需要垃圾回收,熟悉的mKeys数组用于存储key,mValues数组用于存储值,最后一个表示当前SparseArray有几个元素,好了,接下来看最重要的增加方法,先看append 方法
public void append(int key, E value) {
if (mSize != 0 && key <= mKeys[mSize - 1]) {
//当mSize不为0并且不大于mKeys数组中的最大值时,因为mKeys是一个升序数组,最大值即为mKeys[mSize-1]
//直接执行put方法,否则继续向下执行
put(key, value);
return;
}
//当垃圾回收标志mGarbage为true并且当前元素已经占满整个数组,执行gc进行空间压缩
if (mGarbage && mSize >= mKeys.length) {
gc();
}
//当数组为空,或者key值大于当前mKeys数组最大值的时候,在数组最后一个位置插入元素。
mKeys = GrowingArrayUtils.append(mKeys, mSize, key);
mValues = GrowingArrayUtils.append(mValues, mSize, value);
//元素加一
mSize++;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
append方法主要处理两种情况:一:当前数组为空,二:添加一个key值大于当前所有key值最大值的时候。这两种情况都有一个共同的特点就是只需要在数组末尾直接插入就好了,不需要去关心插入在哪里,相当于处理两种简单的极端情形,所以我们在使用SparseArray的时候,也要有意识的将这两种情形下的元素添加,使用append来添加,提高效率。
其实,顾名思义,append,追加的意思嘛,看来取名字还都是有讲究的,不是乱取的,嘿嘿。
接下来看put方法
public void put(int key, E value) {
//二分查找,这里有个巨经典的处理,你相信我,要是不经典,我把好吃的给你。
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//查找到
if (i >= 0) {
mValues[i] = value;
} else {//没有查找到
i = ~i;//获得二分查找结束后,lo的值
//元素要添加的位置正好==DELETED,直接覆盖它的值即可。
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
//垃圾回收,但是空间压缩后,mValues数组和mKeys数组元素有变化,需要重新计算插入的位置
if (mGarbage && mSize >= mKeys.length) {
gc();
//重新计算插入的位置
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
//在指定位置i出=处,插入元素
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
首先,看上去似乎是一个很普通的方法,没有任何异样,但是仔细思考,其实暗藏玄机,我们看到作者先执行了一个二分查找,好,我们来到这个二分查找,如下
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // 找到了
}
}
return ~lo; // 没找到
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
很熟悉,对吧,基本上都会写,但是请你注意,注意了,人家在没找到的时候,返回了一个值,这个有什么用,换做我们的话,一般怎么处理,我想很多人和我一样,返回一个-1,表示查找失败不就可以了,是的,我也觉得这样写没毛病。
现在我们假设自己是作者,我们来想下,他为什么返回一个lo的取反,这没有道理嘛,有什么用呢?
一时想不到,没关系,我们再回头看看put方法,第一步拿到二分查找的结果 i 之后,判断 i 大于0,也就是查找到了,正常向下执行,然后else,也就是 i 值为负,就是没查找到,因为我们在二分查找里返回的是lo的取反,即便最后没查找到,lo也是个正数,正数取反为负数,达到了效果,这是妙用之一,这时你可能会想,我为啥不直接返回个-1,不也达到了效果吗?好,返回-1确实达到了效果,但是人家的返回值在完成了用于判断是否查找成功这个使命之后,还有第二个使命,首先负数取反后,即可再次得到二分查找结束时lo的值,这个lo的值,我现在告诉你,这个位置是不是有点特殊,那特殊在哪呢,没错,这个值就是添加元素的插入位置,接下来的你:
(先懵一会 -->> 仔细思考一下 -->> 拿个笔画一画 -->> 哎哟嘿,好像还真是这么回事 -->> 恍然大悟 -->> 发出感叹:妙啊)
好了,你的流程走完了,这时你应该懂了这个lo值处理的巧妙之处,不懂的就让我再啰嗦一会
假设我们有个数组 3 4 6 7 8。用二分查找来查找元素5
初始:lo=0 hi=4
第一次循环:mid=(lo+hi)/2=2 2位置对应6 6>5 查找失败,下一轮循环 lo=0 hi=1
第二次循环:mid=(lo+hi)/2=0 0位置对应3 3<5 查找失败,下一轮循环 lo=2 hi=1
lo>hi 循环终止
最终 lo=2 即5需要插入的下标位置
神奇不~
所以返回 ~lo的2个作用:一,用于判断是否查找成功;二,用于记录待添加元素的插入位置 (这操作真的完美!!)
好了,我们回到put方法,在拿到待插入元素应该插入的位置之后,我们就可以做出一系列操作了,但是你可能也注意到了一个地方,拿到插入的位置之后,它首先判断需要插入的位置对应mValues 数组的值是不是为DELETED,如果是的话,直接覆盖,至于为什么这样做,这个也就是下面我们要看的了,如果累了,可以喝口茶,接着再看,如下,delete方法源码
public void delete(int key) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
SparseArray也有remove方法,不过remove方法是直接调用的delete方法,所以二者是一样的效果,remove相当于是一个别名
看到这个delete方法,先让我感叹一下,真简单呐,清爽,直接,干脆。但是问题来了,就这几个操作就实现了删除?,逗我呢,这明明就没有删除嘛,okok,不急,我们还是耐心看下它到底做了啥,首先二分查找获取删除key的下标,然后如果成功查找,也就是 i>0 时,判断如果对应key值的value如果不等于DELETED,那么将值置为DELETED,然后设置mGarbage为true,也就是垃圾回收的标志在这里被设置为了true,ok,然后呢,还是一脸懵啊,这也没有删除元素啊,只是做了个赋值操作,好,既然它核心就两步赋值操作,我们不难想到,之前一直见到的一个叫gc() 的方法,我们来到这个方法
private void gc() {
//奇怪的作者没有删掉注释,代码强迫症的我好想给他把这句日志的注释删掉,但是没有权限,嘤嘤嘤!
// Log.e("SparseArray", "gc start with " + mSize);
int n = mSize;//压缩前数组的容量
int o = 0;//压缩后数组的容量,初始为0
int[] keys = mKeys;//保存新的key值的数组
Object[] values = mValues;//保存新的value值的数组
for (int i = 0; i < n; i++) {
Object val = values[i];
if (val != DELETED) {//如果该value值不为DELETED,也就是没有被打上“删除”的标签
if (i != o) {//如果前面已经有元素打上“删除”的标签,那么 i 才会不等于 o
//将 i 位置的元素向前移动到 o 处,这样做最终会让所有的非DELETED元素连续紧挨在数组前面
keys[o] = keys[i];
values[o] = val;
values[i] = null;//释放空间
}
o++;//新数组元素加一
}
}
//回收完毕,置为false
mGarbage = false;
//回收之后数组的大小
mSize = o;
//哼!,这里的注释也没删
// Log.e("SparseArray", "gc end with " + mSize);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
核心的压缩方法思想也很简单,主要就是通过之前设置的DELETED 标签来判断是否需要删除,然后进行数组前移操作,将不需要删除的元素排在一起,最后设置新的数组大小和设置mGarbage 为false。
这里我当初咋一看的时候,有个问题没想明白,就是对数组进行了赋值操作,更改的也是方法里声明的
keys和values数组,但是我没有更改mKeys数组和mValues数组嘛,这个其实是基础知识,数组在赋值的时候,是传递的引用,对数组来说,就是地址,就是两个数组指向了内存中同一块地址,修改任意一个,都会影响另外一个,不信的话,你可以试试下面的例子,看看运行结果
public static void main(String[] args) {
int[] a=new int[] {5,4,8};
int[] b=a;
b[1]=10;
System.out.println(a[1]);
}
到这为止,我们明白了SparseArray 的删除元素的机理,概括说来,就是删除元素的时候,咱们先不删除,通过value赋值的方式,给它贴一个标签,然后我们再gc的时候再根据这个标志进行压缩和空间释放,那么这样做的意图是什么呢?我为啥不直接在delete方法里直接删除掉,多干净爽快?绕那么大圈子,反正不是删除?
别急,我们回过头来看put 方法
//元素要添加的位置正好==DELETED,直接覆盖它的值即可。
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
- 1
- 2
- 3
- 4
- 5
- 6
还记得这一段吗,在添加元素的时候,我们发现如果对应的元素正好被标记了“删除”,那么我们直接覆盖它即可,有没有一种顿悟的感觉!也就是说,作者这样做,和我们每次delete都删除元素相比,可以直接省去删除元素的操作,要知道这在效率上是一个很可观的提高,但是并不是每次put元素都是这样的情况,因为还有gc() 方法来回收,那么我们再仔细想想,和每次delete元素相比,设置“删除”标志位,然后空间不足的时候,调用gc方法来一次性压缩空间,是不是效率上又有了一个提高。
仅仅只是一个删除元素的方法,作者的处理就使用了足足两个小技巧来提升效率,达到最优:一,删除设置“标志位”,来延迟删除,实现数据位的复用,二,在空间不足时,使用gc() 函数来一次性压缩空间。从中可见作者的良苦用心,每一个设计都可以堪称是精髓!。
我们再总结一下SparseArray中的优秀设计
- 延迟删除机制(当仁不让的排第一)
- 二分查找的返回值处理
- 利用gc函数一次性压缩空间,提高效率
好了,到这为止,相信你对SparseArray的基本工作原理有了一个比较清晰的认识!
中场休息:喝口快乐水,活动一下,稍后再来
我们接着来看ArrayMap!
在开始接下来的内容前,希望大家能对hashmap 的设计原理有一个比较深入的了解,因为学习的过程中,单一的学习某个东西,可能没有感受,即便是人家的优秀设计,也体会不到巧妙之处,但是一旦有了一个对比,学习起来就会有一种大局观,这对学习是非常有利的。
简单补充下hashmap的实现原理,采用数组+链表的结构来实现,添加元素时,首先计算key的hash值,然后根据这个hash值,定位到下标,如果冲突的话,则在该下标节点处链上一个链表,以头插法添加新元素为链表头结点,如果链表长度超过指定长度,则转换为红黑树。
hashmap解决冲突的办法叫做链地址法,或者叫拉链法。
先来看看ArrayMap 里面重要的成员变量
//是否置hashcode值为唯一,也就是固定值
final boolean mIdentityHashCode;
int[] mHashes;//存储key的hash值
Object[] mArray;//存储key值和value值
int mSize;//集合大小
//ArrayMap对象转换为MapCollections
MapCollections<K, V> mCollections;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
当然我们最需要关心的就是mHashes[] 和mArray[] 这两个数组.
接下来,看到增加元素的方法,append方法,如下
public void append(K key, V value) {
int index = mSize;
//获取key的hash值
final int hash = key == null ? 0
: (mIdentityHashCode ? System.identityHashCode(key) : key.hashCode());
if (index >= mHashes.length) {
throw new IllegalStateException("Array is full");
}
//当前数组不为空,hash值小于 mHashes[]数组最大的元素时(mHashes数组为递增有序数组)
if (index > 0 && mHashes[index-1] > hash) {
RuntimeException e = new RuntimeException("here");
e.fillInStackTrace();
Log.w(TAG, "New hash " + hash
+ " is before end of array hash " + mHashes[index-1]
+ " at index " + index + " key " + key, e);
put(key, value);//交给put方法处理
return;
}
//当前数组为空,或者hash值大于 mHashes[]数组最大的元素时
mSize = index+1;//数组元素数量+1
mHashes[index] = hash;//在mHashes数组index下标处放入key的hash值
index <<= 1;//相当于乘2操作,为什么要用移位操作呢,因为移位操作效率高
mArray[index] = key;//在mArray数组index*2下标处放入key值
mArray[index+1] = value;//在mArray数组index*2+1下标处放入value值
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
具体的分析,代码中已经给的比较明白了,通过这个append方法,我们可以看到ArrayMap里的两个核心数组mHashes[] 和mArray[] 是如何存储数据的,即,mHashes按照升序(这里看不出来升序,下面的查找会分析到)存储所有的key值计算出来的hash值,然后对于指定的key值计算出来的hash值存储的位置index,对应到mArray数组中,key就是index*2 ,value 就是index*2+1 分析到这里,其实查找的方法我们也知道了,只需要计算key的hash值,得到index后,对应的key和value去mArray数组中查找即可。
对应的存储结构用一张图来表示如下
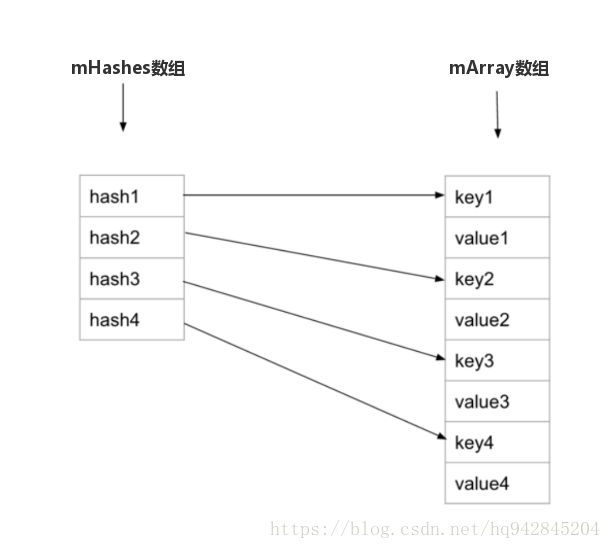
接下来我们再顺着看put方法,但是在看put方法之前,有没有一种似曾相识的感觉,有没有觉得append的这个逻辑套路和思想与SparseArray中的append方法的思想很像,二者都是类似的逻辑,先获取key的hash值,然后和存储hash值的数组作对比,如果小于最大值,则交由put处理,其它情况数组为空以及大于最大值,则append自己直接在数组末端添加即可,后续的操作也是一模一样,只不过根据不同的场景使用了不同的方法而已,可见很多东西是有共性的,如果我们自己需要设计这样某个容器的添加方法时,也可以采纳这种思想。
通过上面的对比分析,我们多多少少能猜到这里的一些逻辑,我们现在来看看put方法
@Override
public V put(K key, V value) {
final int hash;
int index;
if (key == null) {//key为空时,取hash值为定值0
hash = 0;
index = indexOfNull();
} else {
//根据mIdentityHashCode判断是否使用固定的hash值
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
index = indexOf(key, hash);//通过hash值计算下标值,最终也是使用的二分查找
}
if (index >= 0) {//如果找到了,说明之前已经put过这个key值了,这时直接覆盖对应value值
//mHashes数组中的index值,对应的value值在mArray中index*2+1处
index = (index<<1) + 1;
final V old = (V)mArray[index];//记录旧值
mArray[index] = value;//覆盖旧值,增加新的value值
return old;
}
//如果index<0,也就是没有根据key的hash值在mhashes数组中找到对应的下标值
index = ~index;//哇,经典复现!!!(具体SparseArray里才讲过)获取key的hash值要插入的位置
if (mSize >= mHashes.length) {//如果数组容量已满
//获取扩容的大小,这个就是一个稍显复杂的三目运算符,应该--问题不大!就不赘述了,嘿嘿
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
//接下来这三步,进行了allocArrays一个操作,我们暂且不管,放一放,待会再来收拾它
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
//将旧的数组赋值给进行allocArrays操作之后的数组
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
//进行一个叫freeArrays的操作,我们和allocArrays一样,待会再来收拾它
freeArrays(ohashes, oarray, mSize);
}
//如果待插入的位置小于mSize,则需要将mHashes数组index的位置空出来,相应的后面元素后移
//同时mArray数组中index*2和index*2+1这两个位置也要空出来,相应的后面的元素后移
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
//呼!终于可以进行插入操作了
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
中间有一些没见过的函数,没事,我们先让它嚣张一会会,待会再来收拾,整个函数大体流程为:通过key计算hash值,再使用得到的hash值二分查找(indexOf)在mhashes 数组中的index 下标值,我们追踪到indexfor方法里面,最终会发现它也是调用的ContainerHelpers.binarySearch 方法,熟悉不,没错,就是我们SparseArray 中使用的二分查找的方法,通过这个方法,我们在没有查找到元素时,只需要将返回值取反即可获取待插入元素需要插入的位置,然后接下来数组容量满的时候进行的一大串操作先不管,然后会执行数组移动的工作,为相应的元素插入腾出空间,最后插入,结束。
通过整个插入方法的流程,我们知道了ArrayMap里面数据的存储结构,以及其中的关系,我们接着往下。
接下来我们就来收拾刚才遇见的两个神秘大魔头函数,但是在收拾之前,我们先来看看ArrayMap 里与之相关的另外一些成员变量,它们的定义如下
//多次出现的BASE_SIZE ,固定值为4,至于为什么是4,分析完了,就知道了
private static final int BASE_SIZE = 4;
//缓存数组数量的最大值,也就是说最多只能缓存10个数组
private static final int CACHE_SIZE = 10;
//源码中对这几个数组作了英文注释说明,这里简要介绍下
//这四个成员变量完成的功能就是:缓存小数组以避免频繁的用new创建新的数组,避免消耗内存
static Object[] mBaseCache;//用来缓存容量为BASE_SIZE的mHashes数组和mArray数组
static int mBaseCacheSize;//代表mBaseCache缓存的数组数量,控制缓存数量
static Object[] mTwiceBaseCache;//用来缓存容量为BASE_SIZE*2的mHashes数组和mArray数组
static int mTwiceBaseCacheSize;//代表mTwiceBaseCache缓存的数组数量,控制缓存数量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
mBaseCache数组和mTwiceBaseCache数组实现的功能基本一样,只不过mBaseCache是用来缓存容器存储的元素数量为BASE_SIZE的数组,mTwiceBaseCache是用来缓存数量为BASE_SIZE*2的数组,它们都是一个指向数组对象的链表指针,每个数组对象中,数组的第一个元素指向下一个数组,第二个元素指向对应的hash值数组,余下为空。
了解上面这些相关的成员变量之后,我们首先收拾freeArrays 方法,他的代码如下
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
//参数hashes数组对应mHashes数组 参数array数组对应mArray数组 size代表容器元素数量
if (hashes.length == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {//防止多线程不同步
//如果没有达到缓存数量上限
if (mTwiceBaseCacheSize < CACHE_SIZE) {
array[0] = mTwiceBaseCache;//将array的第一个元素指向缓存数组
array[1] = hashes;//将array的第二个元素指向hashes数组
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;//将从下标2起始的位置,全部置空,释放空间
}
//将缓存数组指向设置完毕的array数组
//也就是将array数组添加到缓存数组的链表头
mTwiceBaseCache = array;
mTwiceBaseCacheSize++;//缓存完毕,缓存数组的数量加一
if (DEBUG) Log.d(TAG, "Storing 2x cache " + array
+ " now have " + mTwiceBaseCacheSize + " entries");
}
}
} else if (hashes.length == BASE_SIZE) {//完全一样的逻辑,同上
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
array[0] = mBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
if (DEBUG) Log.d(TAG, "Storing 1x cache " + array
+ " now have " + mBaseCacheSize + " entries");
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
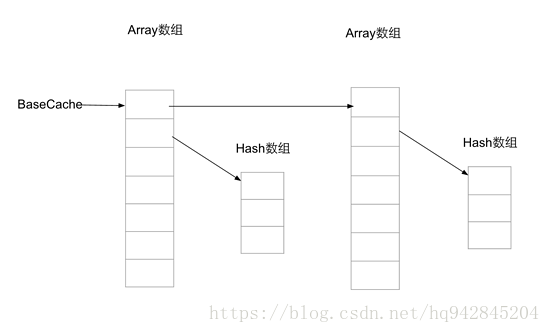
经过代码中的注释分析,我相信大家心中有数了,但是可能还是有点懵,我们再稍微分析一下,整体结构就是分为两种情况,一种是hashes 数组长度为 BASE_SIZE,一种是hashes 数组长度为BASE_SIZE*2 就两种情况,而且这两种情况的逻辑一模一样,只不过换了些成员变量而已,对于大小为其它的情况,这个函数不作任何处理,所以我们这里就挑BASE_SIZE*2 这种情况来分析,经过代码中逐行的解释,我们发现作者就是在构建一个单向链表,链表中的每个节点(这个节点就是处理过后的mArray数组)有两个对象(分别为下标0的值和下标1的值),一个指向下一个节点(相当于next指针),剩下一个就是指向存放hashes值的数组,也就是构建了一个存放mHashes数组的链表。
这个链表的结构如下:
那作者这样做图个啥呢,用一个链表把存放hashes值的数组串起来干嘛,有啥用呢,好的,我们带着疑问再来收拾另外一个allocArrays 方法(其实已经说了是缓存,就先假装不知道嘛),如下
private void allocArrays(final int size) {
//mHashes数组容量为0,直接抛出异常
//EMPTY_IMMUTABLE_INTS这个值是mHashes数组的初始值,是一个大小为0的int数组
//直接写mHashes.length==0不好吗,真是一个奇怪的作者,莫非暗藏玄机?暂且留作疑问
if (mHashes == EMPTY_IMMUTABLE_INTS) {
throw new UnsupportedOperationException("ArrayMap is immutable");
}
//如果大小为BASE_SIZE*2=8,这时缓存使用mTwiceBaseCache数组来缓存
if (size == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {//防止多线程操作带来的不同步
if (mTwiceBaseCache != null) {
final Object[] array = mTwiceBaseCache;
//将mArray指向mTwiceBaseCache(相当于缓存链表的头指针)
//初始化mArray的大小(其实里面0号位置和1号位置也有数据,只不过没有意义)
mArray = array;
//将mTwiceBaseCache的指针指向头节点数组的0号元素,也就是指向第二个缓存数组
mTwiceBaseCache = (Object[])array[0];
//获取头节点数组array的1号元素指向的hash值数组,并赋给mHashes数组
mHashes = (int[])array[1];
//将mTwiceBaseCache缓存链表的头节点0号元素和1号元素置空,释放
array[0] = array[1] = null;
//缓存数组的数量减一
mTwiceBaseCacheSize--;
if (DEBUG) Log.d(TAG, "Retrieving 2x cache " + mHashes
+ " now have " + mTwiceBaseCacheSize + " entries");
return;//结束
}
}
} else if (size == BASE_SIZE) {//使用mBaseCache数组来缓存,同上
synchronized (ArrayMap.class) {
if (mBaseCache != null) {
final Object[] array = mBaseCache;
mArray = array;
mBaseCache = (Object[])array[0];
mHashes = (int[])array[1];
array[0] = array[1] = null;
mBaseCacheSize--;
if (DEBUG) Log.d(TAG, "Retrieving 1x cache " + mHashes
+ " now have " + mBaseCacheSize + " entries");
return;//结束
}
}
}
//如果size既不等于BASE_SIZE,也不等于BASE_SIZE*2
//那么就new新的数组来初始化mHashes和mArray,里面数据均为空,相当于没有使用缓存
mHashes = new int[size];
mArray = new Object[size<<1];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
出奇的相似有木有,都是分为两种情况直接处理,一种BASE_SIZE*2,一种BASE_SIZE,而且从代码中可以看到这两者处理的逻辑一模一样,ok,好办了,我们同样的就挑BASE_SIZE*2 这种情况来分析,首先将mTwiceBaseCache 赋给mArray ,这一步就是初始化mArray 数组,然后将mTwiceBaseCache指向下一个节点,然后将头结点的1号元素,也就是缓存的hashes数组直接赋值给mhashes数组,这一步就是初始化mhashes 数组,初始化完毕后,将使用过的节点置空,缓存数组的数量减一,完毕!
这两个方法分析完毕之后,我们心中基本有了个大致的概念,freeArrays 方法就是添加缓存的,allocArrays 就是取缓存的,然后对于这里的缓存,主要是如下几点需要澄清和注意
- 只有当容器数量为
BASE_SIZE和BASE_SIZE*2这两种情况下才缓存 - 这里的缓存可能跟平时所理解的缓存不太一样,这里缓存主要是实现内存空间的复用缓存,主要是内存空间上的,而不是mHashes数组和mArray数组中数据的值的缓存
allocArrays这个操作会清空mHashes数组和mArray数组中的值。所在在这个操作之前,需要保存它们的值,然后在操作结束之后,用System.arraycopy方法再给他们赋值
接下来我们再回头看到put 方法里的那段绕过的代码,现在再来看看这两个函数到底做了什么,如下
if (mSize >= mHashes.length) {//数组容量满的时候
//计算扩容的大小
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
//保存mHashes和mArray的数据
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//这一步的工作就是,初始化mHashes和mArray数组为扩容后的大小,如何初始化?
//情形一:当且仅当n为BASE_SIZE或BASE_SIZE*2时,直接从对应的缓存数组中取,复用内存空间
//从缓存数组中取,有什么好处呢?就不用再new数组,以免重新开辟空间,浪费内存
//情形二:n不为BASE_SIZE或BASE_SIZE*2时,以new初始化mHashes数组和mArray数组
allocArrays(n);
//初始化完毕之后,再分别给对应的mHashes数组和mArray数组赋值
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
//给初始化后还未赋值的mHashes数组赋值
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);//同上
}
//添加缓存
//注意注意注意,这里传递的size为mSize,也就是扩容之前的大小,并非扩容之后的大小n
//参数一和参数二,也是扩容之前mHashes和mArray中的数据
//如何添加缓存?
//情形一:mSize为BASE_SIZE或BASE_SIZE*2时
//将mHashes数组和mArray数组链接到对应的缓存链表中存起来
//情形二:mSize不为BASE_SIZE或BASE_SIZE*2,什么鸟事都不做
freeArrays(ohashes, oarray, mSize);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
通过注释,我们可以很清楚的看到具体的每一步做了什么。
现在我们再来缕一下思路,关于扩容和缓存这里做个小总结:
当我们在put一个元素的时候
- (1).如果当前元素已满,那么就需要扩容,扩容的大小怎么确定,就是那个三目运算符,如果<4,则扩容至4,如果>4并且<8,则扩容至8,如果大于8,则按1.5倍增长。
- (2)得到扩容后的大小之后:
- 如果扩容后大小为BASE_SIZE或BASE_SIZE*2,那么以直接从缓存数组中取的方式来创建数组
- 如果扩容后的大小不是上述两种情况,那么以new的方式来创建数组,开辟新的空间,消耗内存
- (3)给扩容后的mHashes数组和mArray赋值
- (4)添加扩容之前的数组为缓存(当然前提是扩容之前,size为BASE_SIZE或BASE_SIZE*2)
这个是缓存在put 函数中的使用,机智的你肯定还会猜想,在其它的地方应该也是有使用的,这个我们不急,待会就又见到他啦。
综上,我们已经分析完了整个缓存的思想,整个缓存最终实现的效果总结成一句话就是:
避免了频繁的创建数组带来的内存消耗 (哎,为了一点内存,google设计人员也真的是煞费苦心啊)
现在我们对缓存有了一个清晰的认识之后,我们再来思考之前源码中的注释提出的一个问题:为什么BASE_SIZE要设定为4,从整个缓存的流程中我们可以看到,这个值主要就一个作用:当前数组是否需要缓存。那为什么数组长度为4的时候就要缓存呢?其实你想一下,平常在Android开发中能用到这些容器的场景,是不是都有这些特点:使用频率高,容纳数据量小。所以如果我们不做缓存处理,每次都为了一点点数据的存储去开辟一个新的数组空间,那么必然会浪费掉很多内存。所以4和8这个值是一个相对意义上的“小”值,这个大小基本能最大程度涵盖我们开发中大多数的应用场景,能最大限度上避免新开内存带来的内存消耗,当然你可能会说,那剩下的那些存储量很大的场景呢?这些场景咱们不缓存也罢,毕竟遇到的少,没有必要去做处理,咱们要考虑大局。
呼!终于收拾完了这两个大魔头,歇会,我们接着继续。
弄清楚了插入方法和缓存思想之后,其实剩下的方法都是些虾兵蟹将之类的杂兵了,但是杂兵也要清,那就花点时间清一下呗。
查找原理之前已经提到过了,我们现在就当做验证,看看它的代码是否如预期,代码如下
@Override
public V get(Object key) {
final int index = indexOfKey(key);//二分查找获取下标
//mHashes数组中index位置对应mArray中index*2+1的位置,使用位移操作以提高效率
return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}
- 1
- 2
- 3
- 4
- 5
- 6
这个方法看着非常干净利落,如果上面的都弄懂了,这个get方法的代码理解是完全没有难度的。
接下来我们再看看稍显复杂的删除代码,remove 方法如下
@Override
public V remove(Object key) {
final int index = indexOfKey(key);//计算下标index
if (index >= 0) {//如果找到了
return removeAt(index);//跳转到removeAt
}
//否则返回null
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们接着来到removeAt 方法,略长,但是不难,我们静下心来一点点看
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];//又是神秘操作,待会再看用来干嘛的
if (mSize <= 1) {//如果数组为空或者只有一个元素,那么直接将数组置空即可
// Now empty.
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");
freeArrays(mHashes, mArray, mSize);//又看到这个待会要收拾的方法了
mHashes = EmptyArray.INT;//置空,INT为一个大小为0的int数组
//奇怪的作者为什么要使用这个置空方法,是因为简洁嘛?真想问问他
mArray = EmptyArray.OBJECT;//置空,OBJECT为一个大小为0的Object数组
mSize = 0;//数组大小置0
} else {
//当数组长度大于BASE_SIZE*2=8并且当前元素数量小于总容量的1/3时
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
// 嘿嘿,通过下面的英文注释,可以看到下面的操作是在干嘛了
// Shrunk enough to reduce size of arrays. We don't allow it to
// shrink smaller than (BASE_SIZE*2) to avoid flapping between
// that and BASE_SIZE.
//翻译过来就是,收缩足够的空间来减少数组大小,也就是说这样是为了避免连续
//删除元素导致大量无用内存,这些内存需要及时释放,以提高内存效率
//(哎,再感叹一次,为了一点点点点的内存,设计人员真的是煞费苦心啊)
//但是注释里也说了,还要控制数组不能收缩到小于8的值,以避免“抖动”
//这个抖动我本来想具体解释下的,但是我感觉这个东西完全可以意会,我就不言传了
//所以就留给你们自己感受这个“抖动”吧!哈哈
//计算新的容量,如果大于8,那么就收缩为当前元素数量的1.5倍,否则,就置为8
final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2);
//讨厌的日志,删不掉删不掉删不掉!!!
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);
//保存当前数组的值
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//又看到allocArrays这个方法了,嘿嘿,现在我们知道他是干嘛的了
allocArrays(n);//浓缩成一句话:复用内存以初始化mHashes数组和mArray数组
//数组元素减一
mSize--;
//如果删除的下标index值大于0,则赋值以恢复mHashes和mArray数组index之前的数据
if (index > 0) {
//将之前保存的数组的值赋值给初始化之后的mHashes和mArray数组,恢复数据
//但是注意到第五个参数index,表示这一步只是赋值了删除元素index之前的数据
if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
//如果index小于容器元素数量,则赋值index之后的数据
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + mSize
+ " to " + index);
//对mHashes数组和mArray数组作前移操作,前移index位置以后的元素
System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index);
//当然对mArray来说,就是前移index*2+2之后的数据元素
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
} else {//当前数组容量<8或者大于总容量的1/3时,不需要收缩数组容量
mSize--;//直接减小1
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + mSize
+ " to " + index);
//前移index之后的元素
System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index);
//前移index*2+2之后的元素
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
//前移后,最后一个元素空出来了,及时置空,以释放内存
mArray[mSize << 1] = null;
mArray[(mSize << 1) + 1] = null;
}
}
//呼!分析完了
return (V)old;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
remove 方法我在注释中已经分析的非常详尽了,主要就是一个地方注意的就是空间的收缩问题,根据源码我们可以明确的看到如果当前数据元素小于数组长度的1/3,并且长度大于8时才收缩,为什么是这个界限呢,因为一个数组里容纳的元素1/3都不到,可见效率是非常低的,所以为了节约内存要及时收缩,但是为什么要保证大于8呢,本来是想留给你们自己意会的,我就还是再啰嗦一下,做一下解释。
因为如果我不控制一个界限的话,那么我在低数据量的操作时(<=8,也就是BASE_SIZE*2),我就有两种选择,要么每次都从缓存中去取,要么完全不使用缓存,每次都直接前移index之后的元素,首先我们肯定不能使用后者,这样是完全违背作者设计缓存的思想的,好,那我们现在采用第一种,因为没有了>=8的条件,只需要满足 < mHashes.leng/3即可,但是在数组长度只有8的时候,8/3=2,也就是说我当前数据元素有1个的时候,1<2,所以要去缓存取,但是我只需要再增加一个元素,也就是mSize=2时就不需要去缓存取了,那我再删除一个元素,又只有一个元素了,这时又要去缓存取,那我不断的增加删除元素,是不是就会频繁的去在这两种情况之间切换,导致“抖动”。
所以我们的解决办法就是添加一个下边界,来避免这种情况的发生。(设计人员,您费心了)
至此,我们弄懂了所有的增删查方法,综上:可以看到allocArrays 方法和freeArrays 方法主要出现在需要调整数组容量大小的地方,比如put 和remove 然后再调整的时候,根据数组的长度,来判断是否选择缓存,所以我们不难想到这两兄弟还会出现的第三个地方:没错,就是容量扩充的方法。如下:
public void ensureCapacity(int minimumCapacity) {
if (mHashes.length < minimumCapacity) {
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(minimumCapacity);
if (mSize > 0) {
System.arraycopy(ohashes, 0, mHashes, 0, mSize);
System.arraycopy(oarray, 0, mArray, 0, mSize<<1);
}
freeArrays(ohashes, oarray, mSize);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
弄懂了之前的方法之后,这个方法的理解对我们来说简直是小菜一碟呀,同样的套路,同样的操作!三步走:保存当前值 -> 初始化大小 -> 移动元素 -> 缓存之前的数组 ,不对,好像是四步,嘿嘿!
好啦,我们ArrayMap的原理也弄懂了,做个小小的总结,总结下它的优秀设计
- 存储结构,两个数组存储,一个存key的hash,一个存key和value(设计是最棒的)
- 数组缓存设计(那2个大魔头弄懂就行)
- 删除元素时的数组容量及时收缩
- 删除元素时的下界控制,防止抖动
最后附上一下官方介绍自己亲儿子ArrayMap的视频链接
点我查看Google介绍自己的亲儿子ArrayMap
最后,不得不感叹一下,优秀的思想真的有种让人如允甘醇一般的畅快之感。
优缺点及应用场景
其实在分析源码的时候我们就或多或少可以感受到,它们的优点和缺点,这里我就简单明了,直接亮出它们的优缺点
SparseArray 优点:
- 通过它的三兄弟可以避免存取元素时的装箱和拆箱(关于装箱和拆箱带来的效率问题,可以查看我的这篇文章,Java装箱和拆箱详解)
- 频繁的插入删除操作效率高(延迟删除机制保证了效率)
- 会定期通过gc函数来清理内存,内存利用率高
- 放弃hash查找,使用二分查找,更轻量
SparseArray缺点:
- 二分查找的时间复杂度O(log n),大数据量的情况下,效率没有HashMap高
- key只能是int 或者long
SparseArray应用场景:
- item数量为 <1000级别的
- 存取的value为指定类型的,比如boolean、int、long,可以避免自动装箱和拆箱问题。
ArrayMap优点:
- 在数据量少时,内存利用率高,及时的空间压缩机制
- 迭代效率高,可以使用索引来迭代(
keyAt()方法以及valueAt()方法),相比于HashMap迭代使用迭代器模式,效率要高很多
ArrayMap缺点:
- 存取复杂度高,花费大
- 二分查找的O(log n )时间复杂度远远小于HashMap
- ArrayMap没有实现Serializable,不利于在Android中借助Bundle传输。
ArrayMap应用场景:
- item数量为 <1000 级别的,尤其是在查询多,插入数据和删除数据不频繁的情况
- Map中包含子Map对象
如果觉得这些优缺点一大堆,还是很迷,我就再精简一下二者使用的取舍:
(1) 首先二者都是适用于数据量小的情况,但是SparseArray以及他的三兄弟们避免了自动装箱和拆箱问题,也就是说在特定场景下,比如你存储的value值全部是int类型,并且key也是int类型,那么就采用SparseArray,其它情况就采用ArrayMap。
(2) 数据量多的时候当然还是使用HashMap啦
其实我们对比一下它们二者,有很多共性,,也就是它们的出发点都是不变的就是以时间换空间,比如它们都有即时空间压缩机制,SparseArray 采用的延迟删除和gc机制来保证无用空间的及时压缩,ArrayMap 采用的删除时通过逻辑判断来处理空间的压缩,其实说白了,它们的设计者都是力求一种极致充分的内存利用率,这也必然导致了所带来的问题,例如插入删除逻辑复杂等,不过这和我们使用起来一点都不违背,我们只需要在合适的场景进行取舍即可。
知道了它们的优缺点,我们才可以在实际应用场景中选取合适的容器来辅助我们的开发,提升我们程序的性能才是最关键的,毕竟人家Google设计人员煞费苦心为Android量身打造设计的容器,肯定是有使用的需求和场景的,所以我们在开发中要多对比,有取舍的使用容器。