1.交叉验证
交叉验证:为了让被评估的模型更加准确可信
交叉验证过程
交叉验证:将拿到的数据,分为训练和验证集。
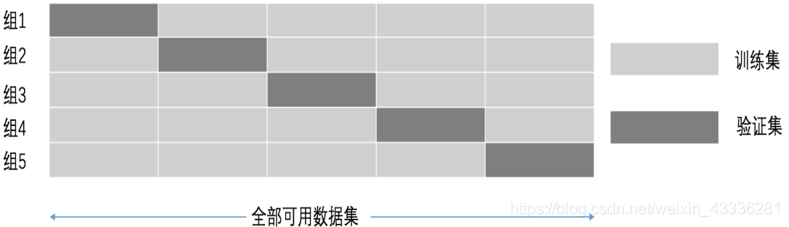
以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
2.网格搜索
网格搜索:调参数 K-近邻。
超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。
但是手动过程繁杂,所以需要对模型预设几种超参数组合。
每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
API
sklearn.model_selection.GridSearchCV
GridSearchCV
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
结果分析:
best_score_:在交叉验证中测试的最好结果
best_estimator_:最好的参数模型
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果