import pandas as pd
import xgboost as xgb
import operator
from matplotlib import pylab as plt
def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0} {1} q
'.format(i, feat))
i = i + 1
outfile.close()
def get_data():
train = pd.read_csv("../input/train.csv")
features = list(train.columns[2:])
y_train = train.Hazard
for feat in train.select_dtypes(include=['object']).columns:
m = train.groupby([feat])['Hazard'].mean()
train[feat].replace(m,inplace=True)
x_train = train[features]
return features, x_train, y_train
def get_data2():
from sklearn.datasets import load_iris
#获取数据
iris = load_iris()
x_train=pd.DataFrame(iris.data)
features=["sepal_length","sepal_width","petal_length","petal_width"]
x_train.columns=features
y_train=pd.DataFrame(iris.target)
return features, x_train, y_train
#features, x_train, y_train = get_data()
features, x_train, y_train = get_data2()
ceate_feature_map(features)
xgb_params = {"objective": "reg:linear", "eta": 0.01, "max_depth": 8, "seed": 42, "silent": 1}
num_rounds = 1000
dtrain = xgb.DMatrix(x_train, label=y_train)
gbdt = xgb.train(xgb_params, dtrain, num_rounds)
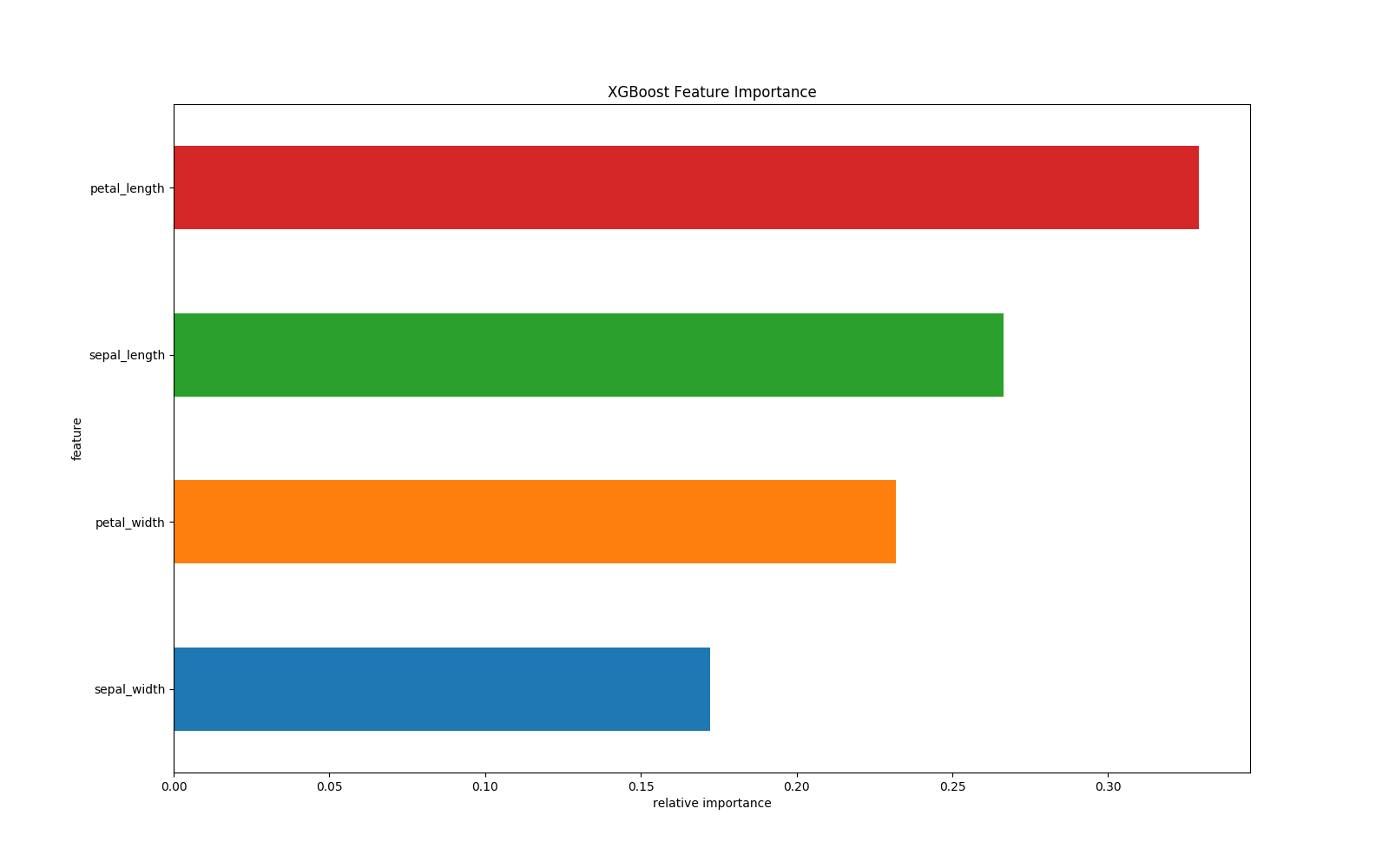
importance = gbdt.get_fscore(fmap='xgb.fmap')
importance = sorted(importance.items(), key=operator.itemgetter(1))
df = pd.DataFrame(importance, columns=['feature', 'fscore'])
df['fscore'] = df['fscore'] / df['fscore'].sum()
plt.figure()
df.plot()
df.plot(kind='barh', x='feature', y='fscore', legend=False, figsize=(16, 10))
plt.title('XGBoost Feature Importance')
plt.xlabel('relative importance')
plt.gcf().savefig('feature_importance_xgb.png')
根据结构分数的增益情况计算出来选择哪个特征的哪个分割点,某个特征的重要性,就是它在所有树中出现的次数之和。
参考:https://blog.csdn.net/q383700092/article/details/53698760
另外:使用xgboost,遇到一个问题

看到网上有一个办法:
重新新建Python文件,把你的代码拷过去;或者重命名也可以;还不行,就把代码复制到别的地方(不能在原始文件夹内),会重新编译,就正常了
但是我觉得本质问题不是这样解决的,但临时应急还是可以的,欢迎讨论!
问题根源:
初学者或者说不太了解Python才会犯这种错误,其实只需要注意一点!不要使用任何模块名作为文件名,任何类型的文件都不可以!我的错误根源是在文件夹中使用xgboost.*的文件名,当import xgboost时会首先在当前文件中查找,才会出现这样的问题。所以,再次强调:不要用任何的模块名作为文件名!
另外:若出现问题:
D:ProgramPython3.5libsite-packagessklearncross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
先卸载原先版本的xgboost, pip uninstall xgboost
然后下载安装新版本的xgboost,地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
命令:pip install xgboost-0.6-cp35-none-win_amd64.whl