第十章 早期(编译期)优化
1、Javac的源码与调试
编译期的分类:
- 前端编译期:把*.java文件转换为*.class文件的过程。例如sun的javac、eclipseJDT中的增量编译器。
- JIT编译期:后端运行期编译器,把字节码转换成机器骂的过程。例如 HotSpot VM的C1、C2编译器。
- AOT编译器:静态提前编译器,直接拔Java文件编译成本地机器代码的过程,例如GCJ。
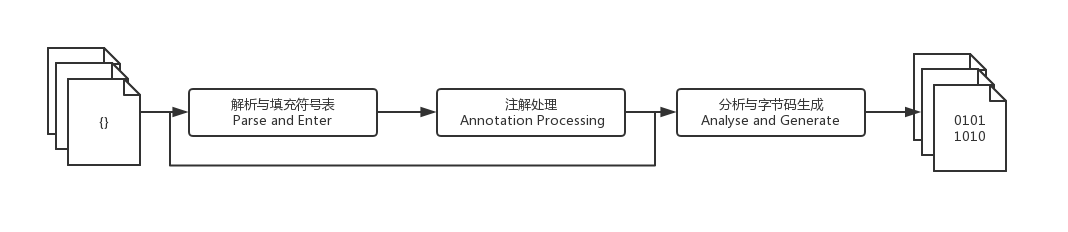
Javac的编译过程:
- 解析与填充符号表的过程。
- 插入式注解处理器的注解过程。
- 分析与字节码生成的过程。
- Javac编译动作的入口是com.sun.tools.javac.main.JavaCompiler类,上述3个过程的代码逻辑集中在这个类的compile()和compile2()方法中,其中主体代码如图所示,整个编译最关键的处理就由图中标注的8个方法来完成,下面我们具体看一下这8个方法实现了什么功能。

解析与填充符号表的过程:
- 词法分析,是将源代码的字符流转变为标记(Token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,关键字、变量名、字面量、运算符都可以成为标记。
- 语法分析,是根据Token序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个阶段都代表着程序代码中的一个语法结构(Construct),例如包、类型、修饰符、运算符、接口、返回值甚至代码注释等都可以是一个语法结构。
- 填充符号表,符号表是由一组符号地址和符号信息构成的表格。符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否一致)和产生中间代码。在目标代码生成阶段,当对符号名进行地质分配时,符号表是地址分配的依据。填充符号表的过程由com.sun.tools.javac.comp.Enter类实现,此过程的出口是一个待处理列表(To Do List),包含了每一个编译单元的抽象语法树的顶级节点,以及package-info.java(如果存在的话)的顶级节点
注解处理器:
- 在JDK1.6中实现了JSR-269规范,提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止。
- 插入式注解处理器的初始化过程是在initPorcessAnnotations()方法中完成的,而它的执行过程则是在processAnnotations()方法中完成的。
- 实现注解处理器的代码需要继承抽象类javax.annotation.processing.AbstractProcessor,这个抽象类中只有一个必须覆盖的abstract方法:“process()”,除了process()方法的传入参数之外,还有一个很常用的实例变量“processingEnv”,它是AbstractProcessor中的一个protected变量,在注解处理器初始化的时候(init()方法执行的时候)创建,继承了AbstractProcessor的注解处理器代码可以直接访问到它。它代表了注解处理器框架提供的一个上下文环境,要创建新的代码、向编译器输出信息、获取其他工具类等都需要用到这个实例变量。注解处理器除了process()方法及其参数之外,还有两个可以配合使用的Annotations:@SupportedAnnotationTypes和@SupportedSourceVersion,前者代表了这个注解处理器对哪些注解感兴趣,可以使用星号“*”作为通配符代表对所有的注解都感兴趣,后者指出这个注解处理器可以处理哪些版本的Java代码。每一个注解处理器在运行的时候都是单例的,如果不需要改变或生成语法树的内容,process()方法就可以返回一个值为false的布尔值,通知编译器这个Round中的代码未发生变化,无须构造新的JavaCompiler实例,在这次实战的注解处理器中只对程序命名进行检查,不需要改变语法树的内容,因此process()方法的返回值都是false。
package com.ecut.javac; import java.util.EnumSet; import java.util.Set; import javax.annotation.processing.AbstractProcessor; import javax.annotation.processing.Messager; import javax.annotation.processing.ProcessingEnvironment; import javax.annotation.processing.RoundEnvironment; import javax.annotation.processing.SupportedAnnotationTypes; import javax.annotation.processing.SupportedSourceVersion; import javax.lang.model.SourceVersion; import javax.lang.model.element.Element; import javax.lang.model.element.ElementKind; import javax.lang.model.element.ExecutableElement; import javax.lang.model.element.Name; import javax.lang.model.element.TypeElement; import javax.lang.model.element.VariableElement; import javax.lang.model.util.ElementScanner7; import javax.tools.Diagnostic.Kind; //这个注解处理器对那些注解感兴趣,使用*表示支持所有的Annotations @SupportedAnnotationTypes(value = "*") //这个注解处理器可以处理那些Java版本的代码,只支持Java1.8的代码 @SupportedSourceVersion(value = SourceVersion.RELEASE_8) public class NameCheckProcessor extends AbstractProcessor { private NameCheck nameCheck; /** * 初始化检查插件 * 继承了AbstractProcessor的注解处理器可以直接访问继承了processingEnv,它代表上下文环境,要穿件新的代码、向编译器输出信息、获取其他工具类都需要用到这个实例 * * @param processingEnv ProcessingEnvironment */ @Override public synchronized void init(ProcessingEnvironment processingEnv) { super.init(processingEnv); this.nameCheck = new NameCheck(processingEnv); } /** * 对语法树的各个节点今夕名称检查 * java编译器在执行注解处理器代码时要调用的过程 * * @param annotations * @param roundEnv * @return */ @Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) { if (!roundEnv.processingOver()) { for (Element element : roundEnv.getRootElements()) { nameCheck.check(element); } } return false; } /** * 程序名称规范的编译期插件 * 程序名称规范的编译器插件 如果程序命名不合规范,将会输出一个编译器的Warning信息 * * @author kevin */ public static class NameCheck { Messager messager = null; public NameCheckScanner nameCheckScanner; private NameCheck(ProcessingEnvironment processingEnv) { messager = processingEnv.getMessager(); nameCheckScanner = new NameCheckScanner(processingEnv); } /** * 对Java程序明明进行检查,根据《Java语言规范(第3版)》6.8节的要求,Java程序命名应当符合下列格式: * <ul> * <li>类或接口:符合驼式命名法,首字母大写。 * <li>方法:符合驼式命名法,首字母小写。 * <li>字段: * <ul> * <li>类,实例变量:符合驼式命名法,首字母小写。 * <li>常量:要求全部大写 * </ul> * </ul> * * @param element */ public void check(Element element) { nameCheckScanner.scan(element); } /** * 名称检查器实现类,继承了1.6中新提供的ElementScanner6<br> * 将会以Visitor模式访问抽象语法数中得元素 * * @author kevin */ public static class NameCheckScanner extends ElementScanner7<Void, Void> { Messager messager = null; public NameCheckScanner(ProcessingEnvironment processingEnv) { this.messager = processingEnv.getMessager(); } /** * 此方法用于检查Java类 */ @Override public Void visitType(TypeElement e, Void p) { scan(e.getTypeParameters(), p); checkCamelCase(e, true); super.visitType(e, p); return null; } /** * 检查方法命名是否合法 */ @Override public Void visitExecutable(ExecutableElement e, Void p) { if (e.getKind() == ElementKind.METHOD) { Name name = e.getSimpleName(); if (name.contentEquals(e.getEnclosingElement().getSimpleName())) { messager.printMessage(Kind.WARNING, "一个普通方法:" + name + " 不应当与类名重复,避免与构造函数产生混淆", e); checkCamelCase(e, false); } } super.visitExecutable(e, p); return null; } /** * 检查变量是否合法 */ @Override public Void visitVariable(VariableElement e, Void p) { /* 如果这个Variable是枚举或常量,则按大写命名检查,否则按照驼式命名法规则检查 */ if (e.getKind() == ElementKind.ENUM_CONSTANT || e.getConstantValue() != null || heuristicallyConstant(e)) { checkAllCaps(e); } else { checkCamelCase(e, false); } super.visitVariable(e, p); return null; } /** * 判断一个变量是否是常量 * * @param e * @return */ private boolean heuristicallyConstant(VariableElement e) { if (e.getEnclosingElement().getKind() == ElementKind.INTERFACE) { return true; } else if (e.getKind() == ElementKind.FIELD && e.getModifiers().containsAll(EnumSet.of(javax.lang.model.element.Modifier.FINAL, javax.lang.model.element.Modifier.STATIC, javax.lang.model.element.Modifier.PUBLIC))) { return true; } return false; } /** * 检查传入的Element是否符合驼式命名法,如果不符合,则输出警告信息 * * @param e * @param initialCaps */ private void checkCamelCase(Element e, boolean initialCaps) { String name = e.getSimpleName().toString(); boolean previousUpper = false; boolean conventional = true; int firstCodePoint = name.codePointAt(0); if (Character.isUpperCase(firstCodePoint)) { previousUpper = true; if (!initialCaps) { messager.printMessage(Kind.WARNING, "名称:" + name + " 应当已小写字符开头", e); return; } } else if (Character.isLowerCase(firstCodePoint)) { if (initialCaps) { messager.printMessage(Kind.WARNING, "名称:" + name + " 应当已大写字母开否", e); return; } } else { conventional = false; } if (conventional) { int cp = firstCodePoint; for (int i = Character.charCount(cp); i < name.length(); i += Character.charCount(cp)) { cp = name.codePointAt(i); if (Character.isUpperCase(cp)) { if (previousUpper) { conventional = false; break; } previousUpper = true; } else { previousUpper = false; } } } if (!conventional) { messager.printMessage(Kind.WARNING, "名称:" + name + "应当符合驼式命名法(Camel Case Names)", e); } } /** * 大写命名检查,要求第一个字符必须是大写的英文字母,其余部分可以下划线或大写字母 * * @param e */ private void checkAllCaps(VariableElement e) { String name = e.getSimpleName().toString(); boolean conventional = true; int firstCodePoint = name.codePointAt(0); if (!Character.isUpperCase(firstCodePoint)) { conventional = false; } else { boolean previousUnderscore = false; int cp = firstCodePoint; for (int i = Character.charCount(cp); i < name.length(); i += Character.charCount(cp)) { cp = name.codePointAt(i); if (cp == (int) '_') { if (previousUnderscore) { conventional = false; break; } previousUnderscore = true; } else { previousUnderscore = false; if (!Character.isUpperCase(cp) && !Character.isDigit(cp)) { conventional = false; break; } } } } if (!conventional) { messager.printMessage(Kind.WARNING, "常量:" + name + " 应该全部以大写字母" + "或下划线命名,并且以字符开否", e); } } } } }
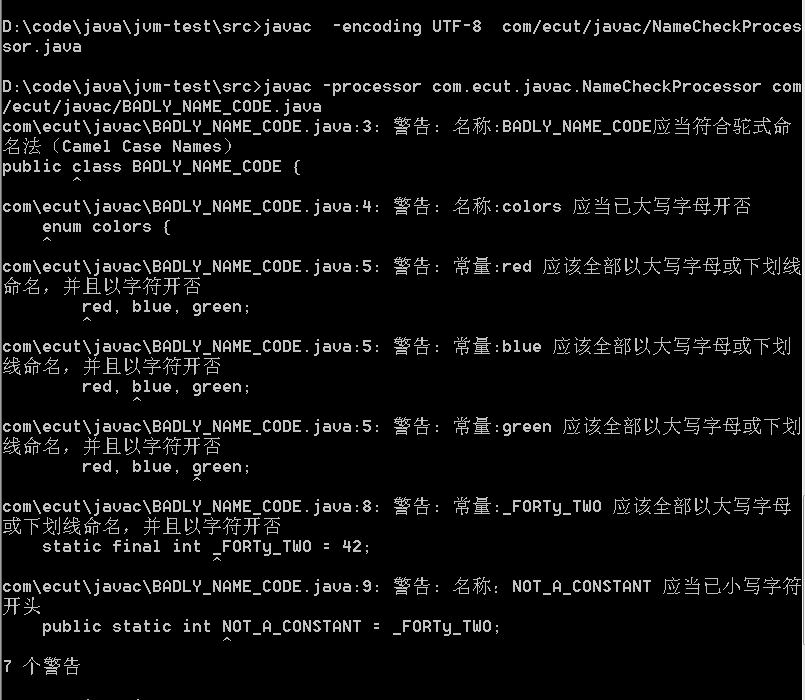
测试类:
package com.ecut.javac; public class BADLY_NAME_CODE { enum colors { red, blue, green; } static final int _FORTy_TWO = 42; public static int NOT_A_CONSTANT = _FORTy_TWO; protected void Badly_Named_Code() { return; } public void NOTcameCASEmethodNAME() { return; } }
运行结果如下图:
语义分析与字节码生成:
- 语法分析之后,编译器获得了程序代码的抽象语法树表示,语法树能表示一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。而语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型审查。
- 语义分析过程分为标注检查以及数据及控制流分析两个步骤。字节码生成之前还需要解语法糖。
- 标注检查,步骤检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等。标注检查步骤在Javac源码中的实现类是com.sun.tools.javac.comp.Attr和com.sun.tools.javac.comp.Check类。
- 数据及控制流分析,是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。
- 解语法糖, 语法糖(System Sugar),也称糖衣语法,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说,使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。java中常用的语法糖主要是泛型、变长参数、自动装箱/拆箱等,虚拟机运行时不支持这些语法,他们在编译阶段还原回简单的基础语法结构,这个过程称为解语法糖。
- 字节码生成,是javac编译过程的最后一个阶段,这个阶段不仅把前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘里,编译器还进行了少量的代码添加和转换工作。 比如:实力构造器()方法和类构造器()方法就是在这个阶段添加到语法树中(并不是默认构造函数,如何用户代码中没有任何构造函数,添加默认构造函数是在填充符号表阶段完成)
2、Java语法糖的味道
泛型与类型檫除:
- Java中的泛型只在程序源码中存在,在编译后的字节码文件中就已经替换为原来的原生类型(裸类型),并且在相应的地方插入强制转型代码。
- 因此对于运行期的java语言来说,ArrayList<Integer>与ArrayList<String>就是同一个类,所以泛型技术就是一颗语法糖,java语言中的泛型实现方法称为类型檫除,基于这种方法实现的泛型称为伪泛型。
泛型擦除前:
package com.ecut.javac; import java.util.HashMap; import java.util.Map; public class GenericTest { public static void main(String[] args) { Map< String , String > map = new HashMap<>(); map.put("How are you ?","吃了吗?"); map.put("Hi","您好!"); System.out.println(map.get("Hi")); } }
编译后,泛型擦除后:
package com.ecut.javac; import java.io.PrintStream; import java.util.HashMap; import java.util.Map; public class GenericTest { public static void main(String[] args) { Map map = new HashMap(); map.put("How are you ?", "吃了吗?"); map.put("Hi", "您好!"); System.out.println((String)map.get("Hi")); } }
泛型重载:
package com.ecut.javac; import java.util.List; public class GenericTypes { //报错信息:“method(list<string>)”与“method(list<integer>)”冲突;两种方法具有相同的擦除功能 public static void method(List<String> list ){ System.out.println("invoke method(List<String> list "); } public static void method(List<Integer> list ){ System.out.println("invoke method(List<Integer> list "); } }
- Signature属性存储一个方法字节码层面的特征签名(区别java层面特征签名,还包含返回值和受查异常表),这个属性中保存的参数类型并不是原生的类型,而是参数化的类型信息。
- LocalVariableTable属性用来描述栈帧中局部变量与Java源码中定义的变量之间的关系。
- Class文件的Signature参数檫除类型只是檫除Code属性中的字节码,实际上元数据还保留了泛型信息。
自动装箱、拆箱与遍历循环:
- 自动装箱、拆箱与遍历循环解语法糖测试
package com.ecut.javac; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; import java.util.stream.Stream; public class ForeachTest { public static void main(String[] args) { List<Integer> list = Arrays.asList(1, 2, 3, 4); // JDK1.8 List<Integer> list2 = Stream.of(1, 2, 3, 4).collect(Collectors.toList()); // JDK1.9 //List<Integer> list3 = Lists.newArrayList(1, 2, 3, 4); int sum = 0; for (int i : list) { sum += i; } System.out.println(sum); } }
编译后:
package com.ecut.javac; import java.io.PrintStream; import java.util.Arrays; import java.util.Iterator; import java.util.List; import java.util.stream.Collectors; import java.util.stream.Stream; public class ForeachTest { public static void main(String[] args) { List list = Arrays.asList(new Integer[] { Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3), Integer.valueOf(4) }); List list2 = (List)Stream.of(new Integer[] { Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3), Integer.valueOf(4) }).collect(Collectors.toList()); int sum = 0; for (Iterator localIterator = list.iterator(); localIterator.hasNext(); ) { int i = ((Integer)localIterator.next()).intValue(); sum += i; } System.out.println(sum); } }
泛型在编译过程中会进行擦除,将泛型参数去除;自动装箱、拆箱在变之后被转化成了对应的包装盒还原方法,如Integer.valueOf()与Integer.intValue()方法;而遍历循环则被还原成了迭代器的实现,这也是为什么遍历器循环需要被遍历的类实现Iterator接口的原因。变长参数(asList()),它在调用的时候变成了一个数组类型的参数,在变长参数出来之前,程序员使用数组来完成类似功能。
- 自动装箱的陷阱
package com.ecut.javac; /** * 基本数据类型和引用类型的区别主要在于基本数据类型是分配在栈上的,而引用类型是分配在堆上的 * 不论是基本数据类型还是引用类型,他们都会先在栈中分配一块内存,对于基本类型来说,这块区域包含的是基本类型的内容; * 而对于引用类型来说,这块区域包含的是指向真正内容的指针,真正的内容被手动的分配在堆上。 */ public class AutoBox { public static void main(String[] args) { Integer a = 1; Integer b = 2; Integer c = 3; Integer d = 3; Integer e = 321; Integer f = 321; Long g = 3L; Integer h = new Integer(3); Integer i = new Integer(3); /* 包装类遇到“==”号的情况下,如果不遇到算数运算符(+、-、*、……)是不会自动拆箱的.所以这里“==”比较的是对象(地址) */ //true 对于Integer 类型,整型的包装类系统会自动在常量池中初始化-128至127的值,如果c和d都指向同一个对象,即同一个地址。 System.out.println("c==d:" + (c == d)); //false 但是对于超出范围外的值就是要通过new来创建包装类型,所以内存地址也不相等 System.out.println("e==f:" + (e == f)); //true 因为遇到运算符自动拆箱变为数值比较,所以相等。 System.out.println("c==(a+b):" + (c == (a + b))); //true 包装类都重写了equals()方法,他们进行比较时是比的拆箱后数值。但是并不会进行类型转换 System.out.println("c.equals(a+b)" + (c.equals(a + b))); //true ==遇到算数运算符会自动拆箱(long) 3==(int)3 System.out.println("g==(a+b)" + (g == (a + b))); //false equals首先看比较的类型是不是同一个类型,如果是,则比较值是否相等,否则直接返回false System.out.println("g.equals(a+b):" + g.equals(a + b)); //true equals首先看比较的类型是不是同一个类型,如果是,则比较值是否相等,否则直接返回false System.out.println("h.equals(i):" + h.equals(i)); //false 通过new来创建包装类型,所以内存地址也不相等 System.out.println("h == i:" + (h == i)); } }
条件编译:
- java语言之中并没有使用预处理器,因为Java语言天然的编译方式(编译器并非一个个地编译Java文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译,因此各个文件之间能够互相提供符号信息)无须使用预处理器。
- Java语言可以使用条件为常量的if语句进行条件编译,根据常量的真假来将分支中不成立的代码块消除掉。
- 只能使用if,若使用常量甚至于其他带有条件判断能力的语句描述搭配,则可能在控制流分析中提示错误,拒绝编译Uncreachable Code。
package com.ecut.javac; public class IfTest { public static void main(String[] args) { if(true){ System.out.println("true"); }else{ System.out.println("false"); } } }
编译后:
package com.ecut.javac; import java.io.PrintStream; public class IfTest { public static void main(String[] args) { System.out.println("true"); } }
源码地址:
https://github.com/SaberZheng/jvm-test/tree/master/src/com/ecut/javac
转载请于明显处标明出处: