与新建线程池相比线程池的优点
线程池的分类
ThreadPoolExector参数、执行过程、存储方式
阻塞队列
拒绝策略
10.1 Exector框架简介
10.1.1 Executor框架的两级调度模型
Exector框架目的是提高Java使用线程执行异步任务的效率,核心思想是把工作单元和执行机制分开,在此之前工作单元和执行机制的角色都由Java中的线程来扮演,在此之后执行机制由Exector来提供。主线程创建实现Runnable或者Callable接口的对象封装需要执行的任务,这一点和传统的多线程机制相同,但是创建完相应的对象后不是执行执行新建的线程而是交给Exector框架去具体的启动线程,Exector返回实现Future接口的对象作为执行结果。
传统的调度方式称为“一级调度框架”(我起的),新建的线程直接交给OS执行,线程执行完毕后销毁。两级调度框架主线程只是把“任务”交给Executor,具体启动线程、何种方式启动线程、执行完毕后线程如何处理等需要和OS打交道的事情由Executor来处理。
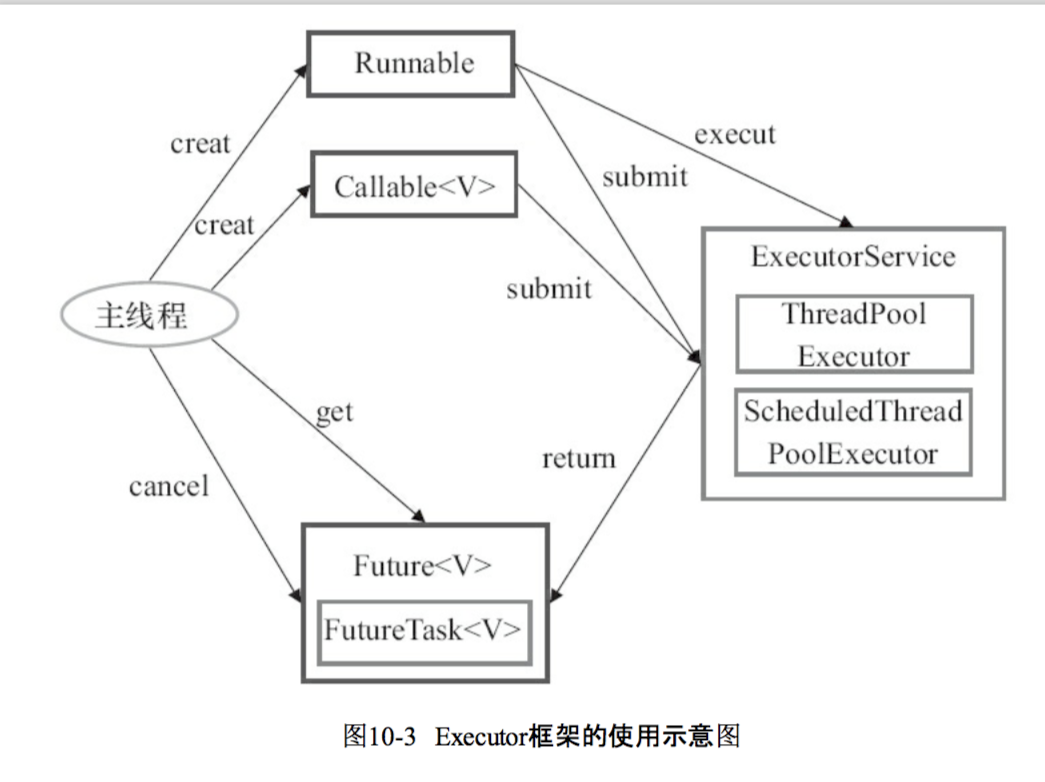
下面使用一个简单的线程池的使用例子。把新建MyTask类实现Runnable接口并把需要执行的代码写在run方法里。在主线程main方法里新建了大小为5的线程池并向线程池里添加了10个任务。
public class ThreadDemo { public static class MyTask implements Runnable{ @Override public void run() { System.out.println(System.currentTimeMillis() + ":Thread Id" + Thread.currentThread().getId()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { MyTask myTask = new MyTask(); ExecutorService threadPool = Executors.newFixedThreadPool(5); for(int i=0;i<10;i++){ threadPool.submit(myTask); } } }
结果如下,可以看到两个特点:1、前五个任务和后五个线程的ID相同,说明线程池的线程是复用的。2、前五个和后五个执行时间相差5S,说明本次使用的线程池是固定大小的
1552285178203:Thread Id10 1552285178203:Thread Id11 1552285178203:Thread Id9 1552285178203:Thread Id12 1552285178203:Thread Id13 1552285179208:Thread Id10 1552285179208:Thread Id9 1552285179209:Thread Id13 1552285179209:Thread Id12 1552285179209:Thread Id11
10.1.2 Executor框架的成员
正如Spring框架,Executor框架在架构上是由一些最简单的接口串起来,下面按照创建工作单元,交给框架,得到返回结果的顺序介绍Executor的成员。
(1) Runnable Callable接口
实现上述两个接口都要重写run方法,所有需要执行的逻辑都写在run方法里,实现了这两个接口的对象就是工作单元,所有工作单元都可以交给Executor框架去执行。他们的区别在于Callable接口有返回值。
(2) Executor接口
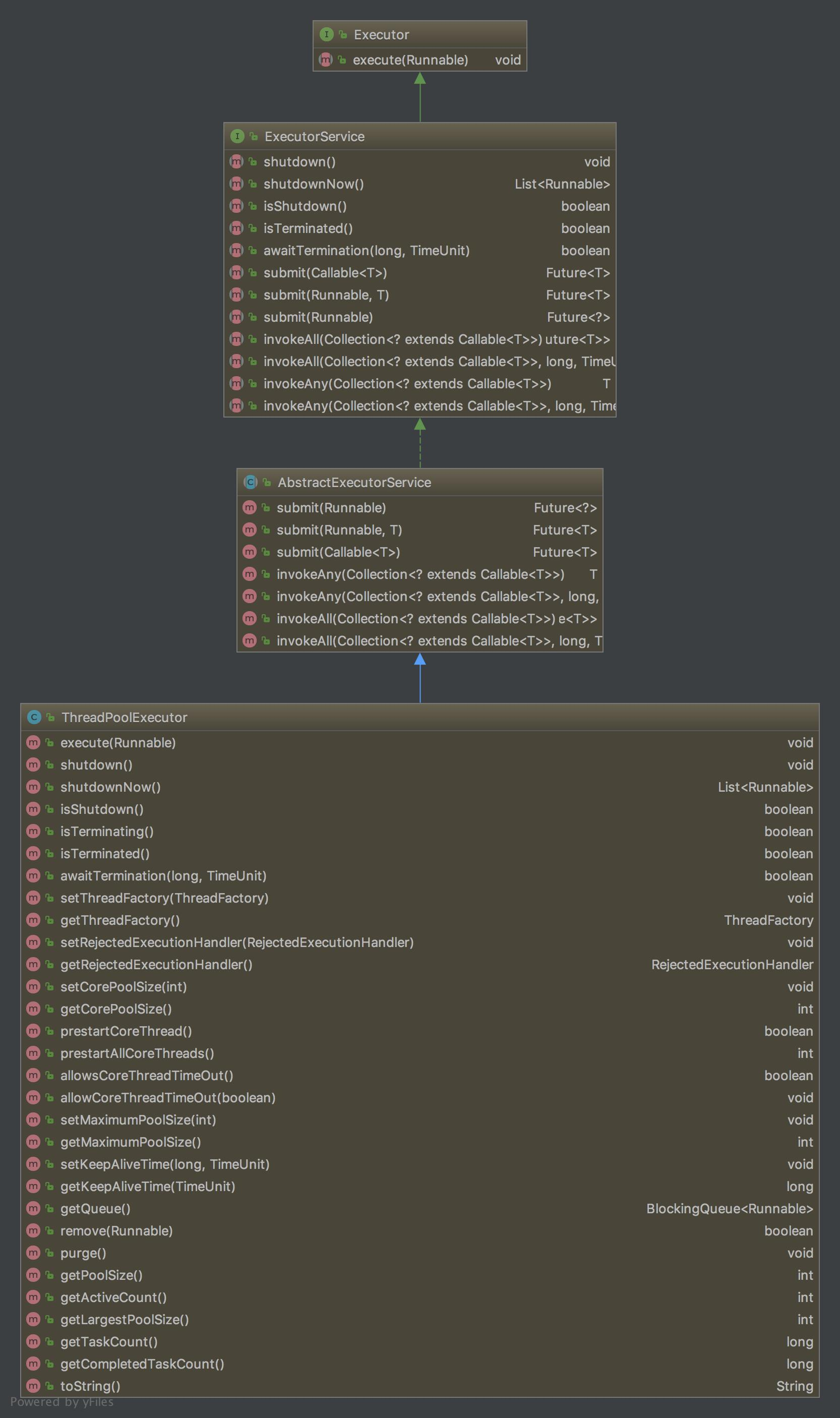
最上层是Executor接口,仅仅提供了execute方法。其次是ExecutorService接口,扩展了Executor接口提供了更多方法如各种各样终止线程池的方法。再接着是一个抽象类AbstractExecutorService,该抽象类提供了一些供子类使用的方法如submit方法,该方法会以某种方式调用executor方法。最后才遇到了最重要的类ThreadPoolExecutor,上面示例代码使用的FixedThreadPool实际上就是ThreadPoolExecutor。Executor下各种各样不同的可以直接使用的线程池类都是采用不同的入参创建的ThreadPoolExecutor和ScheduledThreadPoolExecutor。
(3) Future 接口

Future接口及其实现类是用来表示计算结果,但使用方式并不是我猜想的的在计算结束后把结果用Future实现类包装起来,关于Futur接口的使用可以看一下AbstractExecutorService的submit方法。submit方法的重载方法一共有三个,不管入参的类型如何在submit方法里总是把Runnable或者Callable的对象封装成RunnableFuture的对象ftask,而Executor框架真正处理的对象就是RunnableFuture对象,RunnableTask是一个接口,真的的对象类型是FutureTask。
FutureTask像一个运输工具,载着Runnable Callable进Executor框架,载着返回结果出来。
public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; } /** * @throws RejectedExecutionException {@inheritDoc} * @throws NullPointerException {@inheritDoc} */ public <T> Future<T> submit(Runnable task, T result) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task, result); execute(ftask); return ftask; } /** * @throws RejectedExecutionException {@inheritDoc} * @throws NullPointerException {@inheritDoc} */ public <T> Future<T> submit(Callable<T> task) { if (task == null) throw new NullPointerException(); RunnableFuture<T> ftask = newTaskFor(task); execute(ftask); return ftask; }
10.2 ThreadPoolExecutor
10.2.1 ctl与内部状态
ctl是用来表示线程池的运行状态和线程池中任务状态的AtomicInteger变量。前三位用来表示线程池的状态共有五中状态
- Running 线程池处在运行状态,可以向线程池加入新的任务,线程池也会处理线程池里的任务
- Shutdown 线程池不接受新的任务,但是会处理原有剩余的任务
- Stop 撂挑子,及不接受新任务,也不处理原有任务
- TIDYING 当线程池“任务”数量为0的时候会变为TIDYING状态,当变为TIDYING状态时为执行terminated方法用于线程终止前的后事处理。该方法默认为空需要用户根据需要重写
- TERMINATED 在TIDYING运行完terminated后来到的状态

10.2.2 关键参数与执行流程
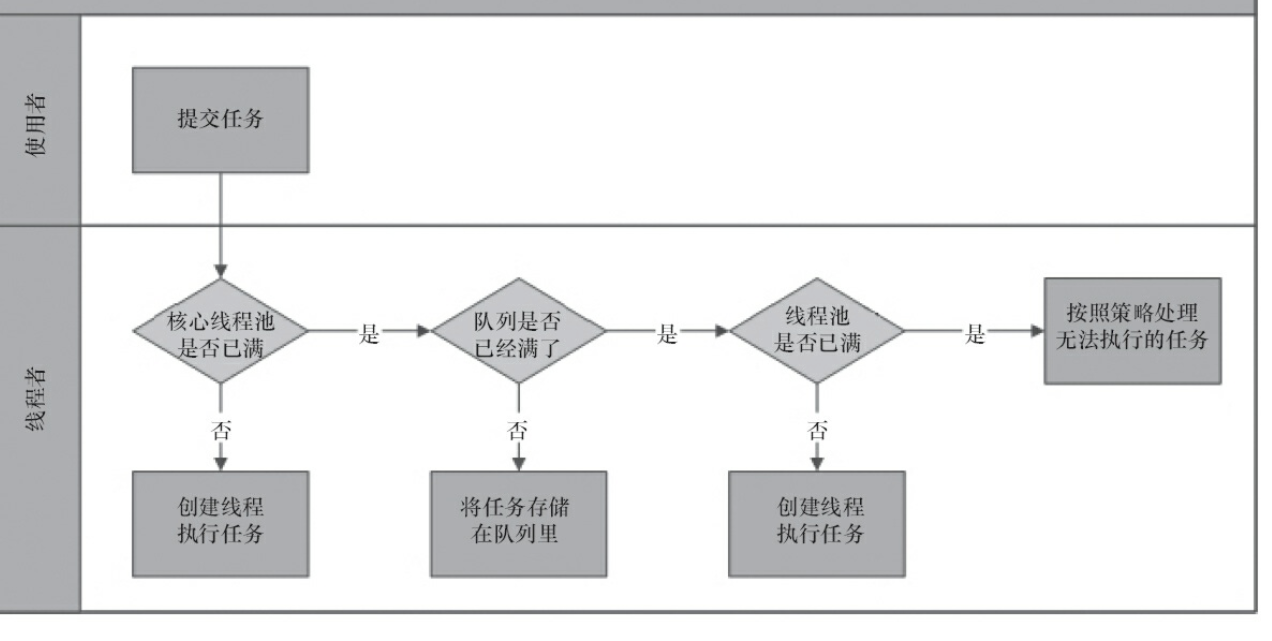
- corePoolSize 线程池新接受一个任务时,如果当前线程池worker的数目少于corePoolSize,无论当前的Worker是否存在空闲都要新建一个Worker。
- 如果当前Worker的数目大于corePoolSize,就把新任务加入workQueue中。再把任务加入队列后还要进行两次检查,如果当前队列已经不处于running则从队列移除出去;如果当前线程数目等于零那么就新建线程,注意这里新建的线程传入的command参数为null。
- 如果workQueue不是无界队列,那么当该队列满的时候回创建新的worker
- 如果超过了maximumPoolSize,那么执行拒绝策略
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) reject(command); }
这种设计思路似的线程池在绝大多数工作中第二种状态,即新的任务在队列里等待,等到线程空余下来去执行他们,省略了线程创建和销毁的代价。线程池中的线程在执行完新建该线程传进来的任务后会反复从队列里取出待执行的任务并执行。
addWorker是整个线程池最核心的方法用于向线程池里增加线程,刚方法一共做了三件事情:
- 判断是否可以创建新的线程。首先根据线程池的状态判断,其次根据当前线程池拥有的线程的数目判断
- CAS 修改线程池里线程的数目
- 新建woker对象加入队列并启动worker对象。
private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // Re-read ctl if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { final ReentrantLock mainLock = this.mainLock; w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int c = ctl.get(); int rs = runStateOf(c); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
一个worker启动的时候会首先执行新建该worker时传入的任务,如果该任务为Null就会调用getTask方法去队列里取任务并执行。整个过程是一个循环如果这个循环结束那么worker会被销毁,即当getWorker返回为Null的时候worker会被销毁。getWorker会到队列里不停的取任务,取任务的过程如果超时那么getWorker就会返回null即worker被销毁。
final void runWorker(Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null; w.unlock(); // allow interrupts boolean completedAbruptly = true; try { while (task != null || (task = getTask()) != null) { w.lock(); // If pool is stopping, ensure thread is interrupted; // if not, ensure thread is not interrupted. This // requires a recheck in second case to deal with // shutdownNow race while clearing interrupt if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); Throwable thrown = null; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); } } finally { task = null; w.completedTasks++; w.unlock(); } } completedAbruptly = false; } finally { processWorkerExit(w, completedAbruptly); } }
10.3 派生出的线程池
通过传入不同的参数ThreadPoolExecutor可以变成不同策略的线程池,主要关注的参数有核心线程数目和最大线程数目、阻塞队列的种类、超时。
10.3.1 FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
新建fixedThreadPool的时候需要传入nThreads,该参数即是核心线程数目也是最大线程数目,这意味着当等待队列满的时候直接执行拒绝策略,但其传入的队列是一个无界队列所以这种情况并不存在。其次超时时间为0,意味着当worker一旦空闲就会立即销毁。无界队列和超时时间为0的组合使得一旦线程池没有任务整个线程池就会停止。并且无界队列由于永远不会满,所以不会执行拒绝策略。
10.3.2 SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
新建的时候有一个线程,也就是说是一个线程在循环往复的工作。并且采用的是无界队列。
10.3.3 CachedThreadPool