FROM : 通过协程实现mysql查询的异步化
前言
最近学习了赵海平的演讲,了解到facebook的mysql查询可以进行异步化,从而提高性能。由于facebook实现的比较早,他们不得不对php进行hack才得以实现。现在的php5.5,已经无需hack就可以实现了。
对于一个web网站的性能来说,瓶颈多半是来自于数据库。一般数据库查询会在某个请求的整体耗时中占很大比例。如果能提高数据库查询的效率,网站的整体响应时间会有很大的下降。如果能实现mysql查询的异步化,就可以实现多条sql语句同时执行。这样就可以大大缩短mysql查询的耗时。
异步为啥比同步快?
与异步查询相反的时同步查询。通常情况下mysql的query查询都是同步方式。下面我们对两种方式做下对比。对比的例子是,请求两次select sleep(1)。这条语句在mysql服务器端大概耗时1000ms。
同步方式的执行流程: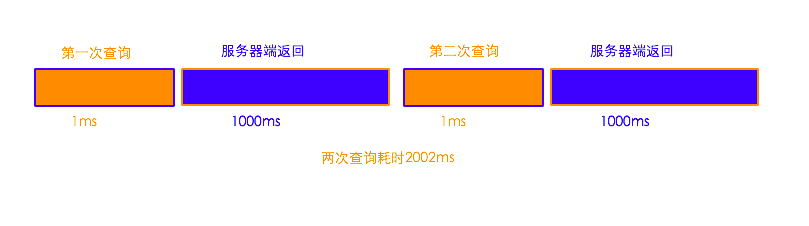
第一步,向mysql服务器端发送第一次查询请求。大概耗时 1ms
第二步,mysql服务器端返回第一次查询的结果。大概耗时 1000ms
第三步,向mysql服务器再次发送请求。大概耗时 1ms
第四步,mysql服务器端返回第二次查询的结果。大概耗时 1000ms
同步的方式执行两次select sleep(1),大概耗时 2002ms。
异步方式的执行流程: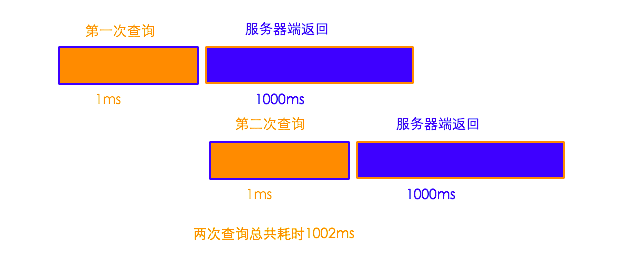
第一步,向mysql服务器端发送第一次查询请求。大概耗时1ms
第二步,在等待第一次请求返回数据的同时,向服务器端发送第二次查询请求。大概耗时 1ms
第三步,接受mysql服务器端返回的两次查询请求。大概耗时 1000ms。
对比分析
异步查询比同步查询速度快,是因为多条查询语句在服务器端同时执行,大大缩短了服务器端的响应时间。并行一般情况下总比串行快嘛。sql语句执行时间越长,效果越明显。
如何实现mysql的异步查询?
要实现异步查询的关键是能把发送请求和接受返回数据分开。正好mysqlnd中提供了这个特性。
在mysqlnd中对应的方法是:
mysqlnd_async_query 发送查询请求
mysqlnd_reap_async_query 获取查询结果
mysqli扩展针对mysqlnd的这个特性做了封装,在调用query方法时,传入MYSQLI_ASYNC即可。
具体代码实现可以查看博文 php中mysql数据库异步查询实现
为啥使用协程?
查看了博文中的代码实现,是不是感觉写法和平时不一样?一般在项目当中,我们都是以function的形式去相互调用,function中包含了数据库查询。为了保持这个习惯,方便大家使用,因此引入了协程。在php5.5中正好提供了yield和generator,方便我们实现协程。示例代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
<?phpfunction f1(){ $db = new db(); $obj = $db->async_query('select sleep(1)'); echo "f1 async_query
"; yield $obj; $row = $db->fetch(); echo "f1 fetch
"; yield $row;}function f2(){ $db = new db(); $obj = $db->async_query('select sleep(1)'); echo "f2 async_query
"; yield $obj; $row = $db->fetch(); echo "f2 fetch
"; yield $row;}$gen1 = f1();$gen2 = f2();$gen1->current();$gen2->current();$gen1->next();$gen2->next();$ret1 = $gen1->current();$ret2 = $gen2->current();var_dump($ret1);var_dump($ret2);class db{ static $links; private $obj; function getConn(){ $host = '127.0.0.1'; $user = 'demo'; $password = 'demo'; $database = 'demo'; $this->obj = new mysqli($host, $user, $password, $database); self::$links[spl_object_hash($this->obj)] = $this->obj; return self::$links[spl_object_hash($this->obj)]; } function async_query($sql){ $link = $this->getConn(); $link->query($sql, MYSQLI_ASYNC); return $link; } function fetch(){ for($i = 1; $i <= 5; $i++){ $read = $errors = $reject = self::$links; $re = mysqli_poll($read, $errors, $reject, 1); foreach($read as $obj){ if($this->obj === $obj){ $sql_result = $obj->reap_async_query(); $sql_result_array = $sql_result->fetch_array(MYSQLI_ASSOC);//只有一行 $sql_result->free(); return $sql_result_array; } } } }}?> |
在终端命令行方式执行结果如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$time php ./async.php f1 async_query f2 async_queryf1 fetchf2 fetcharray(1) { ["sleep(1)"]=> string(1) "0"}array(1) { ["sleep(1)"]=> string(1) "0"}real 0m1.016suser 0m0.007s |
从结果上我们可以看出执行流程是,先发了两次mysql查询,然后在接受数据库的返回数据。正常情况下,至少需要2000ms才能执行完毕。但是,real 0m1.016s,说明两次查询的耗时只有1016ms。
tips:以上代码只是示例代码,还有一些需要完善的地方。
注意
需要注意的是,如果mysql服务器本身负载很大,这种并行执行的方式就不一定是好的解决方法。因为,mysql服务端会为每个链接创建一个单独的线程进行处理。如果创建的线程数过多,会给系统造成负担。